



Batch Normalization存在的一些问题
(1)BN在mini-batch较小的情况下不太适用
BN是对整个mini-batch的样本统计均值和方差
当训练样本数很少时,样本的均值和方差不能反映全局的统计分布信息,从而导致效果下降
(2)BN无法应用于RNN
RNN实际是共享的MLP,在时间维度上展开,每个step的输出是(bsz, hidden_dim)
由于不同句子的同一位置的分布大概率是不同的,所以应用BN来约束是没意义的
BN应用在CNN可以的原因是同一个channel的特征图都是由同一个卷积核产生的
在训练时,对BN来说需要保存每个step的统计信息(均值和方差)
在测试时,由于变长句子的特性
测试集可能出现比训练集更长的句子,所以对于后面位置的step,是没有训练的统计量使用的
Layer Normalization的原理
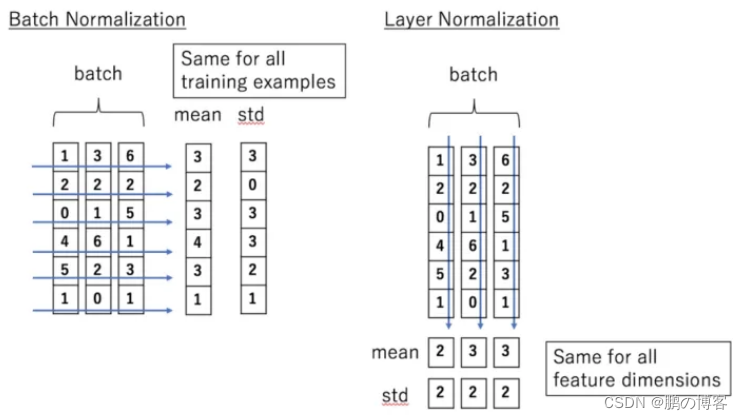
BN是对batch的维度去做归一化,也就是针对不同样本的同一特征做操作
LN是对hidden的维度去做归一化,也就是针对单个样本的不同特征做操作
BN就是在每个维度上统计所有样本的值,计算均值和方差
LN就是在每个样本上统计所有维度的值,计算均值和方差
因此LN可以不受样本数的限制

计算均值和方差
x = torch.randn(bsz, hidden_dim)
mu = x.mean(dim=1) # 注意!要统计的是每个样本所有维度的值,所以应该是dim=1上求均值
sigma = x.std(dim=1)
Transformer中Layer Normalization的实现
Layer Normalization的和Batch Normalization一样,同样会施以线性映射的
区别就是操作的维度不同
# features: (bsz, max_len, hidden_dim)
class LayerNorm(nn.Module):
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
# 就是在统计每个样本所有维度的值,求均值和方差,所以就是在hidden dim上操作
# 相当于变成[bsz*max_len, hidden_dim], 然后再转回来, 保持是三维
mean = x.mean(-1, keepdim=True) # mean: [bsz, max_len, 1]
std = x.std(-1, keepdim=True) # std: [bsz, max_len, 1]
# 注意这里也在最后一个维度发生了广播
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
Layer Normalization VS Batch Normalization
LN特别适合处理变长数据,因为是对channel维度做操作(这里指NLP中的hidden维度),和句子长度和batch大小无关
BN比LN在inference的时候快,因为不需要计算mean和variance,直接用running mean和running variance就行
直接把VIT中的LN替换成BN,容易训练不收敛,原因是FFN没有被Normalized,所以还要在FFN block里面的两层之间插一个BN层。(可以加速20% VIT的训练)
总结
Layer Normalization和Batch Normalization一样都是一种归一化方法
因此,BatchNorm的好处LN也有,当然也有自己的好处:比如稳定后向的梯度,且作用大于稳定输入分布
然而BN无法胜任mini-batch size很小的情况,也很难应用于RNN
LN特别适合处理变长数据,因为是对channel维度做操作(这里指NLP中的hidden维度),和句子长度和batch大小无关
BN比LN在inference的时候快,因为不需要计算mean和variance,直接用running mean和running variance就行
BN和LN在实现上的区别仅仅是:BN是对batch的维度去做归一化,也就是针对不同样本的同一特征做操作
LN是对hidden的维度去做归一化,也就是针对单个样本的不同特征做操作
对于NLP data来说,Transformer中应用BN并不好用,原因是前向和反向传播中,batch统计量及其梯度都不太稳定
对于VIT来说,BN也不是不能用,但是需要在FFN里面的两层之间插一个BN层来normalized
参考文献
- https://zhuanlan.zhihu.com/p/492803886
- https://arxiv.org/pdf/2003.07845.pdf
- https://stackoverflow.com/questions/45493384/is-it-normal-to-use-batch-normalization-in-rnn-lstm





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











