



二维码介绍
二维码主要有以下几种类型,本次主要以QRCODE为切入点。

版本
QRcode主要有40个版本(v1 -> V40)
符号的范围是2121(version 1)===>177177(version 40)。每提升一个版本长和宽各添加4个符号位长度。
版本定位: 其版本定位由V-E来标识。V标识其版本号(1-40),E定义其纠错码级别(L、M、Q、H),后面会有介绍到;
基本结构
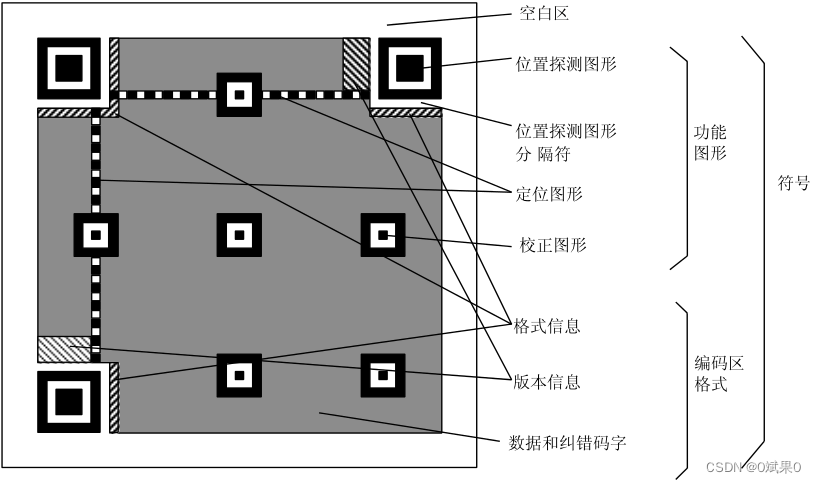
空白区: 包围在最外层的四个module宽度的区域。主要用于分割主内容部分,提高二维码识别效率。
位置探测图形(定位符): 左上,右上,左下角各一个定位符。所有的定位符都是有77的深色,55的亮色,33的深色module组成。定位符会被优先识别,通过其来得知二维码的位置、旋转、拉伸、偏移等信息。用来确认符号的笛卡尔坐标表示的。
**定位图像(时序符):**由一个module宽度组成的符号,可以是亮色可以是深色。提供了符号的密度和版本信息,用来定位和提供数据的位置和确定module的坐标。在QR Code中分别位于横向和钟祥的第六行和第六列。
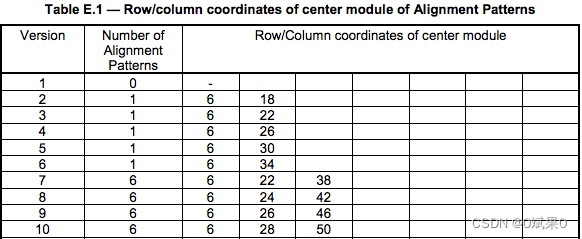
校正图形(校正符): QR Code在版本V2以上才有,所有的校正符都是由55的深色,3*3的亮色和一个深色的module来组成,数量与版本有关。
**编码区域:**符号上没有被功能符号占用的区域,用于存储编码数据,纠错码,版本信息内容。
编码流程概览:
1.数据解析
2.数据编码
3.纠错码编码
4.重构最后信息
5.矩阵转换
6.数据遮掩
7.格式和版本信息
数据解析
解析输入的数据串来确定是采用默认或则是扩展的ECI模式来解析内容。
解析输入的数据串来决定是采用默认或者是扩展的ECI模式来解析内容。所以我们需要在一个符号编码切换到另外的编码,来尽可能减少比特数据流的长度。这样至少其中的某一部分或者几个部分可以更有效率的。比如 数字序列可以按照数字文本模式解读。理论上最有效率的模式是每个数据字符需要最小的比特长度的,但是有些时候模式的指示符号会被跳过,而且这个和每次模式切换的字符长度有关。在一些最短暂的比特流字符串可能不会被此都会转换。并且因为二维码的数据容量的增长步骤和版本是分离的,所以我们可能没必要每次都以最有效率的方式解析。
编码模式
输入数据流是由一个或者几个置顶编码模式形成的碎片的比特流组成的。比特流的编码规则由第一个模式指示符号决定。
QRCode默认ECI时000003,就是iso8859-1字符集
支持的编码模式有:
1.数组编码(Numeric mode)
默认由纯数字0-9或者字节数据(16进制30-39),通常三个数字字符被10个bit标识。
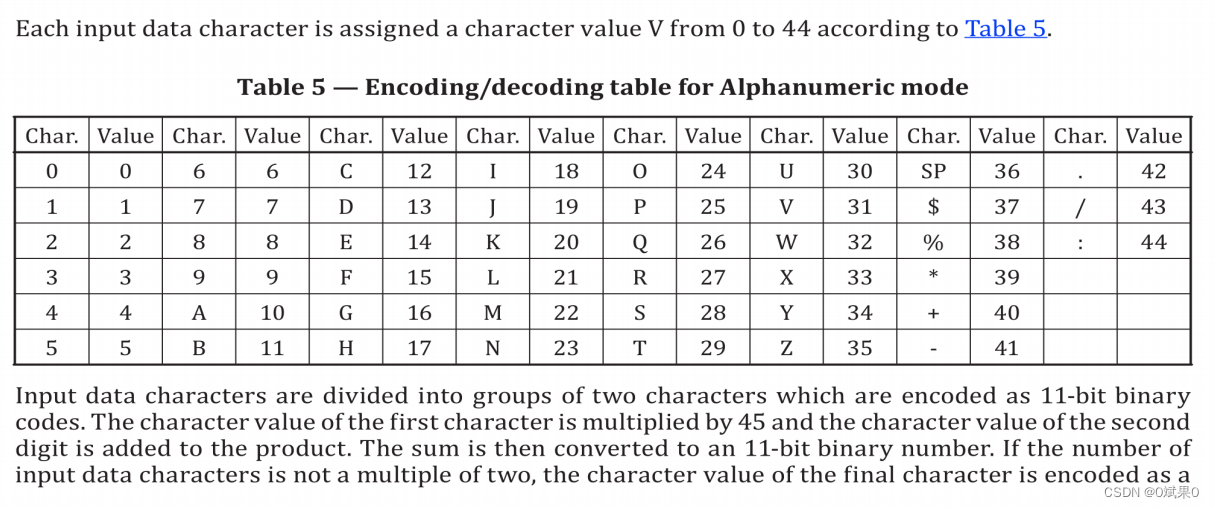
2.数字文本模式(Alphaumeric mode)
数字文本模式由45个字符集合内的数据编码而成。包括 十个数字 0-9(30-39 hex)26个字符(A-Z)(41-5A HEX),以及9个符号(SP,$,%,*,+,-,./😅(20,24,25,2A,2b,2d-2f,3a HEX).正常情况下两个字符被11个bit所标识
3.字节模式(Byte mode)
该模式下,每个字符被编码为8比特。当字符集被修改时,解码应用程序也会相应变化。
4.日本字模式(kanji mode)
5.混合模式(Mixing modes)
6.结构添加模式(Structured Append mode)
7.FNC1模式(FNC1 mode)
编码表


数字模式
输入的字符串数据,会被分组成由三个数字组成的小组,并且每个小组的数据都会被切换成10个比特的二进制模式。如果划分后的数字不为三个,则被一二位会分别转换为4个比特或7个比特。
例子1 对于1H级别的数据来说
输入数据为 01234567
转换为三个数字分组 012 345 67
按组进行二进制转换 012 转换为 0000001100 345转换为 0101011001 67转换为1000011
讲数字链接成数据子句 0000001100 0101011001 1000011
讲字符长度转换为2进制的标示(1H版本是10个比特长度) 8 -> 0000001000
模式标识符0001 和比特长度加到前面形成结果
0001 0000001000 0000001100 0101011001 1000011
B = M + C + 10(D DIV 3) + R
注:
B 字符长度
M mode类型长度
C 对应数据个人长度
D 源数据长度
R (D mod 3 = 2) ? 7 : (D mod 3 = 1) ? =4 : 0
数字文本模式
对于数字文本模式会将其划分成两个一组,生成的编码规则是第一位乘以45再加上第二位,再将结果转为二进制,剩下一位的时候直接转二进制。
输入数据 AC-42
1 根据表5来确定字符的具体数值 AC-42 -> 10,12,41,4,2
2 对字符数值两两分组 (10,12)(41,4)(2)
3 按照编码规则,转换为11位的比特
10,12 10*45+12 -> 00111001110
41.4 41*45+4 -> 11100111001
2 -> 000010
4 链接成数据子句
00111001110 11100111001 000010
5 字符数量转换为二进制
5 → 000000101
6 添加模式标示0010 至模式头部
0010 000000101 00111001110 11100111001 000010
字母数字类别的字符,比特长度转换依赖与下面的公式:
B = M + C + 11(DDIV2) + 6(D MOD 2)
字节模式
一个8比特长度的 字直接代表一个 字节的数值。
对于所以字符类型的数据字节流长度,可以通过下面的额公式计算
B = M + C + 8D
结束符号
符号的数据部分结束时,应该加上0bit序列作为标识。这些事情在表2中有定义。 这些比特序列会跟在最终模式片段之后。 终止符号在处理数据时应该被忽略,如果数据刚刚好填充满符号。或者如果剩余空间不足比特长度终止符长度的时候,应该缩写。
比特流编码为字
当比特流转换为各个模式的片段时,必须按照一定的顺序进行。终止符号需要被添加到比特流后面,就如7.4.9所描述的那样。 然后得到的结果需要被拆分编码为字。所有的字都应该时8个比特长度。如果比特不能被8整除,那说明他们还不到一个字的边界,应该填充0比特知道边界。比特的长度应该符合表8中对version和纠错码的约定,不足的地方交替填充字 11101100和00010001。
例如:
hello world 采用1-Q数字文本模式编码,得到的是一个74位的模块片段,需要追加终止符号0000。所以得到78位,因为比特流最后要达到8的倍数,所以还得补充结束符号,因为不足4位所有补充缩写00。而且其长度还没达到(26 - 13)* 8 = 104比特。所以还得交替补充(104 - 80)/ 8 = 6个补充字
纠错码编码
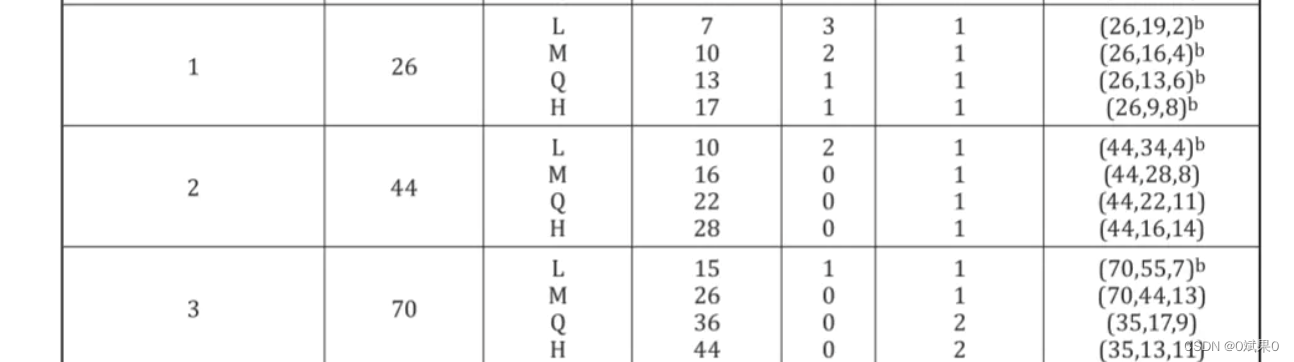
QR CODE使用了里德所罗门算法来识别和纠正错误信息。会有一系列纠错码数据字被生成出来,添加到数据的后面用来让符号在数据丢失或损坏得情况下,依然可以使用。 表8中定义了四种可以选择得纠错码级别,他们可以让恢复指定数量得容量。
纠错字可以纠正两种类型得情况,第一种时失去的字数据(明确位置信息,但是信息字节错误)第二种时错误信息(未知位置信息,错误得信息字) 遗失的意思时,无法扫描或者无法解码,错误的意思时解析失败的符号字符。因为二维码时一种矩阵技术,所以如果某个模块 黑色被当成了白色,或者白色被当成了黑色,都可以被识别为一个错误标识的内容。这样的一个错误,需要两个纠错码才能纠正它。
纠错码级别:
L ----7%
M ----15%
Q ----25%
H ----30%
可以被纠错和遗失的模点遵循下面公式:
e + 2t <= d - p
e 是遗失的模点数量 t 是错误的模点数量 d 是纠错码数量 p 是被错误解析的保护字节(译者注:错误而非遗失)
一般情况下,p 是0,但是如果大部分的纠错码容量就去用于处理遗忘模点,然后可能会导致没有发现的错误增加。不论何时,当遗失模点的数量超过纠错码一半的时候,p =3。 对于小于8个纠错码字的小符号来说,遗忘纠错不应被使用(e = 0 并且 p > 0)
举个例子 在版本6H符号来说,数据容量尺寸是172,112是纠错码字,剩下60个纯粹的数据字。112个数据纠错码,可以纠正56个错误字.(解析错误,或者移位错误) 换句话说 56/172 也就是32.6%的符号容量
举个例子再2L 版本中,一共有44个字长,其中34个是是数据字,还有十个是纠错码。从表9中可以看到它的错误容量是4(e = 0),套用上面的公式:
0 + 2 * 4 = 10 - 2;
它的意思是纠正四个错误,只需要8个错误矫正符号。剩下的两个可以用来检测(仅仅是检测,而不是修正)额外的错误。如果超过四个错误,那么解析失败。
消息构建
构造最终的消息字节序列需要下列几个步骤(消息 + 纠错码 + 填充码)
第一步: 将数据序列分组拆分到各个模块之间
第二步: 对各个数据块,分别计算纠错码
第三步: 将各个数据块的数据和纠错码取出,重新拼接到一起。
里德索罗门码
-
消息多项式
消息多项式的系数组成:数字码字。如“hello world” ,利用二维码的编码原理,转换成十进制数字为“32, 91, 11, 120, 209, 114, 220, 77, 67, 64, 236, 17, 236, 17, 236, 17”,因此,这个语句的消息多项式为:

-
生成多项式
生成多项式可以用下面这个式子概括:
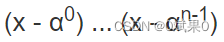
n是生成的纠错码字的数量,α一般默认为2。为了方便进行多项式的出发,我们需要对生成多项式进行展开。

(多项式在源文档82页’dog head’)
注意,在这里的指数大于255也是不行的,一旦超过255,就要通过对255取模的方式来降一降。
注:GF(256)是啥?QR Code标准表示使用逐位模2算术和逐字节模100011101算法,也就是使用伽罗瓦域2^8.或者或者伽罗瓦域256,有时写为GF(256)。GF(256)的范围是0~255。
简而言之,在这个神奇的领域里面,超过255是不允许的,一旦超过就要通过异或的方式来降一降。比如说2^8=256,因此需要和100011101进行异或操作来得到最终的值,所以
2^8=256 异或85 = 58
2^9=58 * 2=116。
2^10=116*2=232。……
3.进行除法
将生成多项式除以消息多项式来得到最后的结果。普通的多项式除法一般大家以前都接触过,但在这里不是在乘法步骤之后减去,而是执行XOR(在GF(256)中,其实就是一样的)。
就不多介绍。
步骤可以分为以下三步:
1. 找到适当的项乘生成多项式,使得乘法的结果与消息多项式具有相同的第一项。
2. 使用消息多项式(在第一个乘法步骤中)或余数(在所有后续乘法步骤中)对结果进行异或。
3. 执行这些步骤n次,其中n是消息多项式中的系数。
在进行两个多项式的除法之后,将有一个余数。 该余数的系数是纠错码字。
拿完整的消息多项式和生成多项式做一个例子。
完整的消息多项式如下(Hello world的例子):
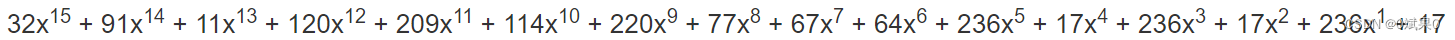
为了确保在除法期间引导项的指数不会变得太小,将消息多项式乘以x^n,n是所需的纠错码字的数量。如当纠错码字的数量是10时,上式应该变成:
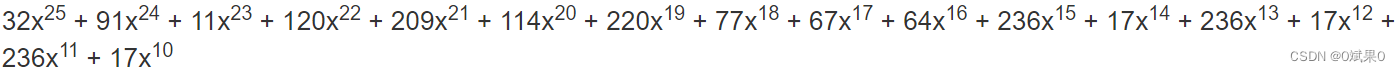
生成多项式的前导项也应该具有相同的指数,因此生成多项式也乘x^15得到下式(这里的原始生成多项式可以从上面给的链接里面轻松得到)
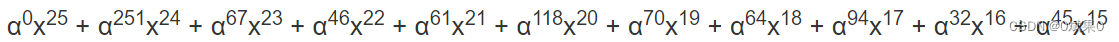
具体开始步骤:
1. 将生成多项式乘以消息多项式的前导项。消息多项式的前导项是32,也就是α^5,乘上生成多项式后,生成多项式变成

注意,指数的值不能超过255,一旦超过就要进行对255取模的操作。
可以明显看出经过上面这些步骤(保持指数相同,将消息多项式的前导码乘到生成多项式上),生成多项式和信息多项式拥有了完全相同的第一项。
2.使用消息多项式对结果进行异或;从下面这个式子也可以看出来,就是消息多项式和生成多项式中相同次数的项的系数进行了异或操作,经过这个操作之后,消息多项式中最高次数的项已经没有了(因为生成多项式和消息多项式拥有完全相同的第一项,一异或就没了)。
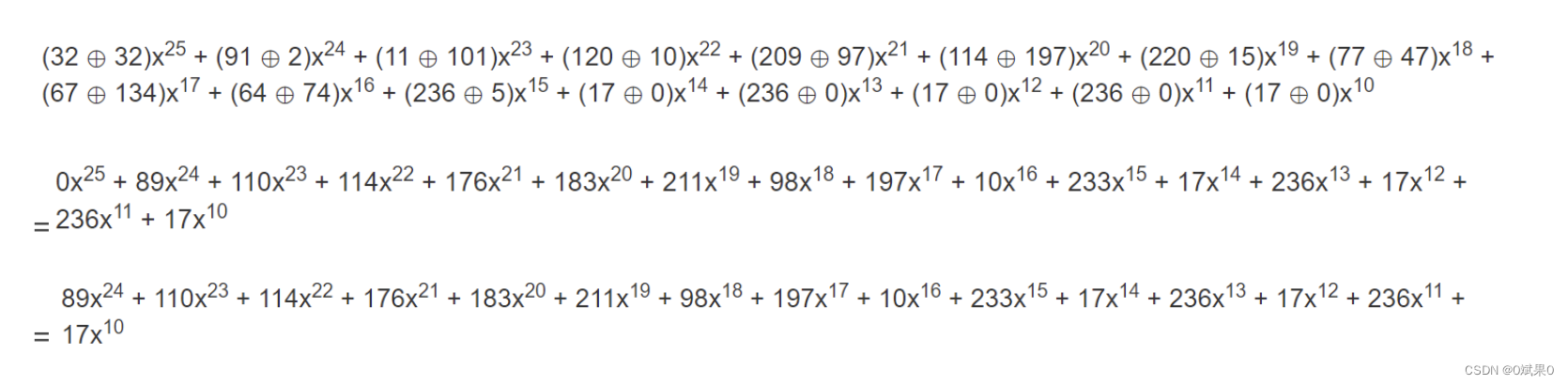
3. 将生成多项式乘上一步的XOR结果的前导项。注意,这里的生成多项式已经经过了和现在的信息多项式等指数的过程,所以最高次是24。
在这个例子中,前导项是89x^24,做乘法的时候,把数字用α表示比较简单,89又等于α^210(这个可以查表得),所以
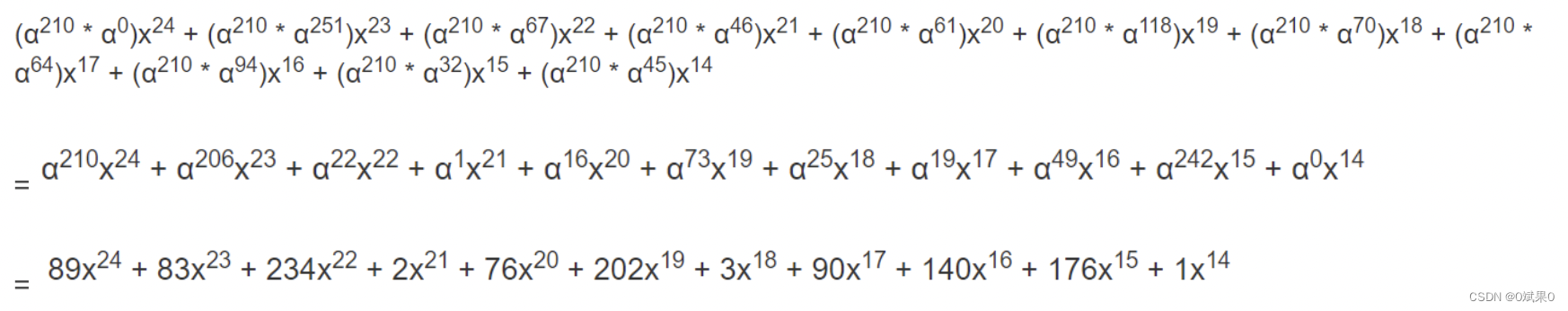
4.将上一步得到的式子继续重复类似步骤2的异或操作,这个操作之后,最前面那项(次数为24次的那项)又成功没有了。
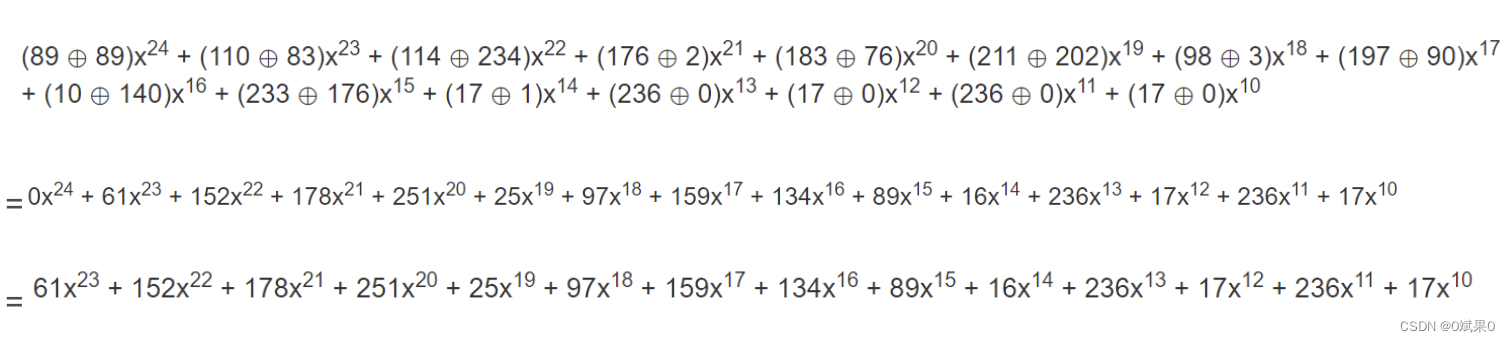
接下来这一步就可以想象啦,就是把61乘到原始的生成多项式上,把指数对好了的生成多项式和上一步得到的式子进行异或操作。
那么重复到什么时候好呢?从上面可以看出来,循环一次,就有一个消息多项式中的一项被消除,所以消息多项式有多少项,就进行多少次循环(这就好像除法进行到了最后一位)。上述例子循环16次后,就得到了下面这个式子(从这个式子中我们就可以看出来,刚开始的时候乘x^10有多明智,为什么是10而不是9或者8也从这里可以看出,因为生成多项式的最高次数是纠错码字的数目,一项项异或之后,最后的余数的位数和生成多项式的位数是相关的)
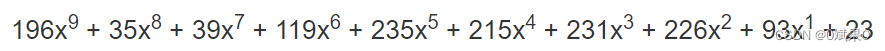
现在我们就得到纠错码字了:196 35 39 119 235 215 231 226 93 23
得到纠错码字之后就是按照规范给填到二维码的格子里面。
详细链接:https://blog.youkuaiyun.com/ljm1995/article/details/88819664
构建最终的消息字节序列
消息的字节数必须始终与表7 表9中关于容量的约束。构造最终的消息字节序列需要下列几个步骤(消息+纠错码+填充码 如果需要)
第一步 按照表9中的约定,将数据序列分组拆分到各个 模块之间(对于MICRO来说只有一个模块)
第二步 对各个数据块,分别计算纠错码 按照7.5.2和附件A中的约定
第三步 将各个数据块的 数据和纠错码取出,并且重新拼接到一起。 举例,比如现在有四个数据块序列,那么他们的顺序是 块1的第一个字节,块2 的第一个字节…块1的第1个字节,块2的第一个字节,以此类推。二维码的符号包含的数据和纠错码信息刚刚好填充满整个符号。但是在某些版本可能不能刚刚整除8,所以可以需要3,4,7个填充的比特添加到消息后用来填充编码区域。
最短的数据块应该放到最前面,纠错码放到数据块后面。举个例子在5-H版本符号中,包含了四个数据和纠错码的数据块,前两个包含着11个数据字和22个纠错码字,后两个包含的是12个数据字和22个纠错码字,他们的变化过程可以参看说明15. 每行的数据字(用Dn标识)都在纠错字的前面(用En标识)字符的序列关系是按照每列从上向下来回反复。
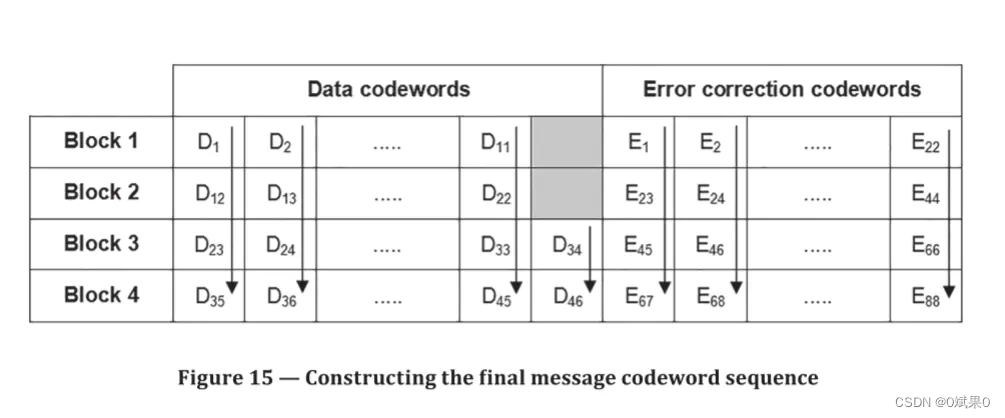 版本5-H 最终消息的字节序列是这样的:
版本5-H 最终消息的字节序列是这样的:
D1 D12 D23 D35 D2。。。。
纠错码也是如此。最后,将结果放到一起(源码在前,纠错码在后)。
某些编码区域 是没有被占满的,需要补充0来填满编码区域,详细看表1.
绘制图形
首先,根据字符长度和校验级别级别指定对应的qrcode版本。根据位置相对信息构建对应的定位符、分割线、终止符、修正符号。格式版本模点位置先临时值空。
绘制位置探测方块
先把三个大“回”字画整起来!分别放在左上、右上和左下角,回字的大小是固定的。

生成N个校正方块
格式信息
格式信息是一个15比特的序列,其中包含5个数据序列和10个纠错比特序列,使用的是(15,5)的BCH编码。对于纠错码生产部分的详细信息参考附录3,前两个数据比特会包含符号的纠错码级别。
前两个是纠错版本,后三个是数据遮掩版本。
15个比特纠错码格式信息应该被XOR操作,和 掩码 101010000010010, 为了保证不会出现类似全零的数据字符串。
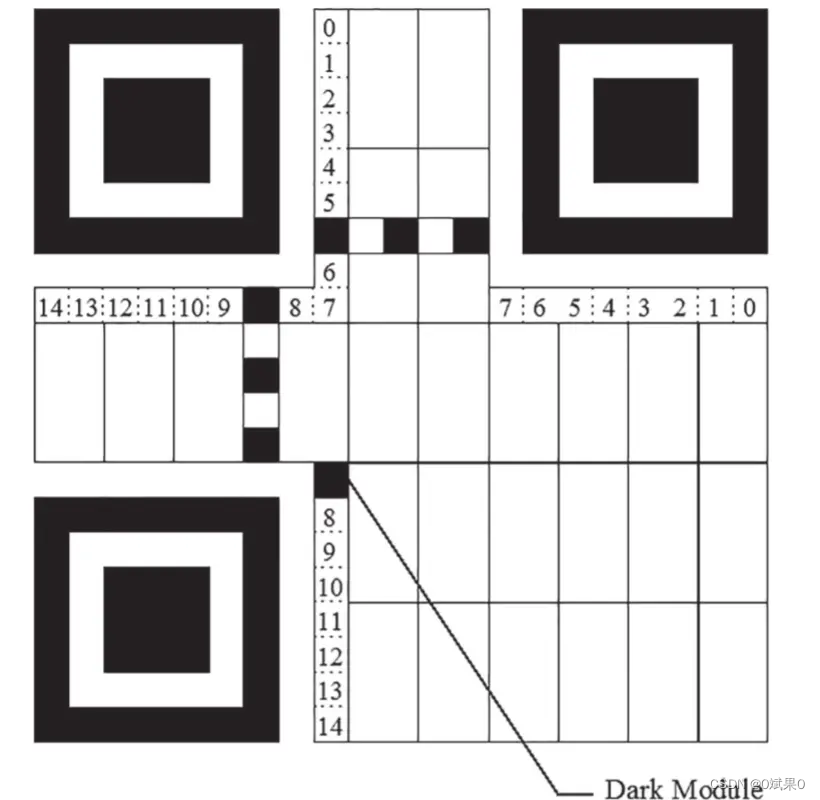
最终得到的结果应该被嵌入指定区域,按照说明25中的描述,值得注意的是,格式信息在符号中会出现两次,为了提供必要的冗余。最低有效位,放在0的位置, 最高有效位放在14的位置。 有一个特殊的小黑点,(4V+9,8)这是一个永远是黑色,且不属于格式信息的一个模点位置。
版本信息
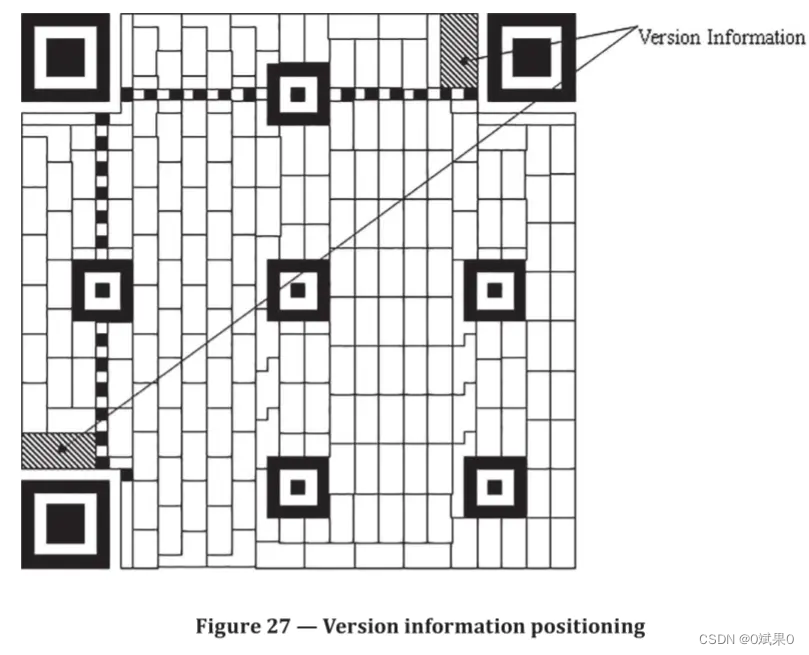
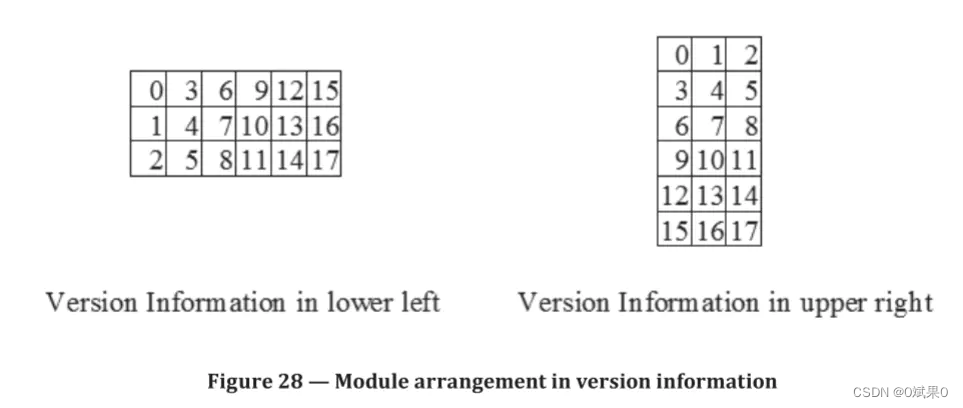
版本信息只存在7级以上的版本中。它是一个18比特序列构成,其中六个数据比特,12个纠错码比特。他们由(18,6)的多兰码计算得出。如果没有版本信息,将会被全0的数据字符串填充,只有版本为7-40的符号由版本信息。 数据遮罩不会应用于版本信息。
纠错符信息

编码
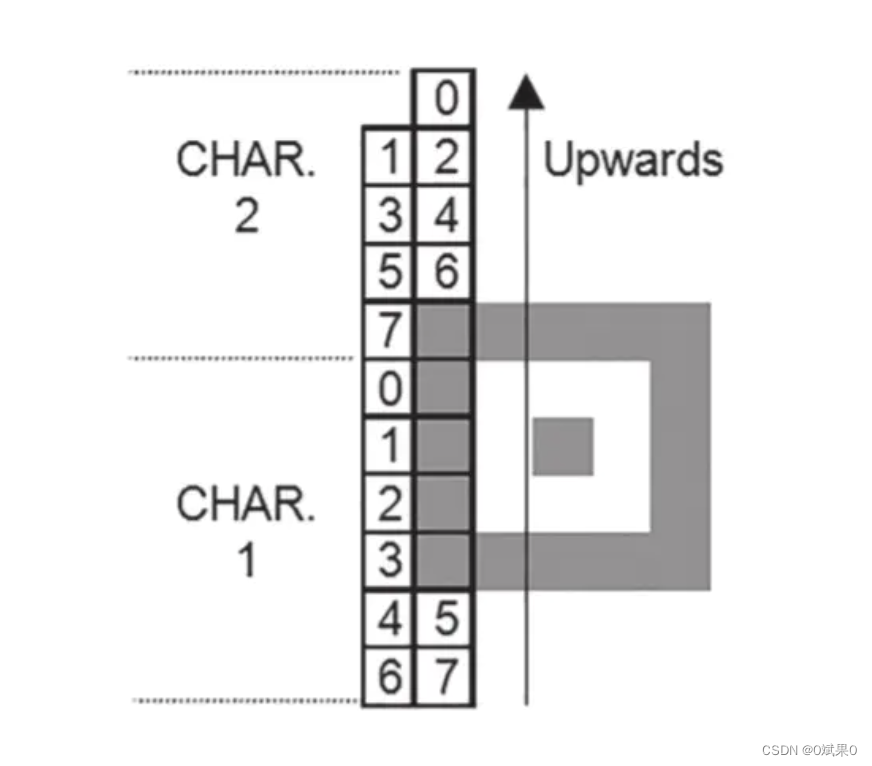
在二维码符号的编码区域,字符符号的位置是由两个模点宽度的,从右下角开始,蛇行向上左转。他们所需要遵循的原则看下面。 说明19和说明20. 用图示的方式说明了版本2和版本7如何应用这些规则。
a) 一行比特序列应该遵循从右向左的原则,不是向上就是向下,具体要根据符号字符的方向
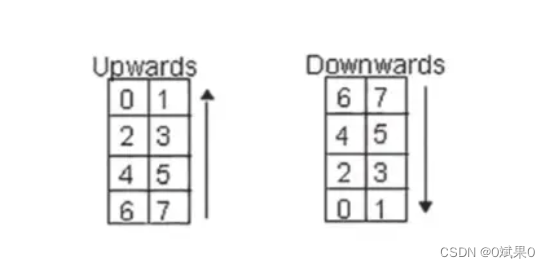
b) 字节中最有意义的比特(比如bit7)应该被放到第一个可以使用的模点位置,剩下的比特放到下一个模点位置。因此在上升的情况下,最有效比特会出现在 右下角,在下降的方向下,最有效比特会出现在右上角。
c) 当一个符号字符遇到 校正符号或者终止符号的横向边界时,在所有的模点杭商,都应该按照编码区域向上或者向下继续。(向上向下取决于当时的方向,这句话是我自己的理解)
d) 当遇到纵向,也就是向上向下的边界时(比如遇到符号的边界,格式信息区域,版本信息区域或者间隔符号)剩下的比特应该向左一行继续,方向反转。
e) 有的时候会因为矫正符号或者版本符号导致右手边的行被占用,此时比特们会被用非规则的形式所展示,他们只会只用一行模点来使用矫正符号或者版本符号。 如果当前字符结束前还没有遇到两行可用的情况。那么下一个字符继续占用单行。

备注:版本16以上的qrcode符号可能会使用结构化添加格式。如果一个符号是由多个结构化信息拼凑出来的,那么它会在前两个半符号字符位置标识出来。结构化添加模式标识符号0011,会在符号的第一个字符 大端位置的前四个比特中放置。
扩展:当前说明的这个码字 标识了 二维码符号属于结构化添加格式的部分中的位置(版本16以上)(在n个符号中第m个位置)
前四个比特标识了 当前符号在整个符号中的位置,后面的四个比特标识了当前图形拥有多少位置。
每四个比特 应该用来展示 m-1 和 n-1的二进制模式展示
举个例子: 标识在7个符号中的第三个符号位置,应该是下面的编码
第三个位置 0010
一共七个符号 0110
最终的bit模式 00100110
在此之后,立刻跟上两个结构化添加字,放置在第一个符号字符的四个小端比特位置。符号的第二个字符和 符号第三个字符的大端位置。 第一个字是符号序列的标识,第二个字是数据校验位,并且所有的信息都是相同的。这样可以验证所有的符号都是一致的,以至于可以构成同一个结构化添加信息。上述的头部信息后面会立刻跟上数据编码字,并且连接第一个模式标识符。 如果存在一个或者多个非默认的ECI,那么每个ECI模块(由ECI模式指示符和ECI 设计符组成)都需要加上头部信息。
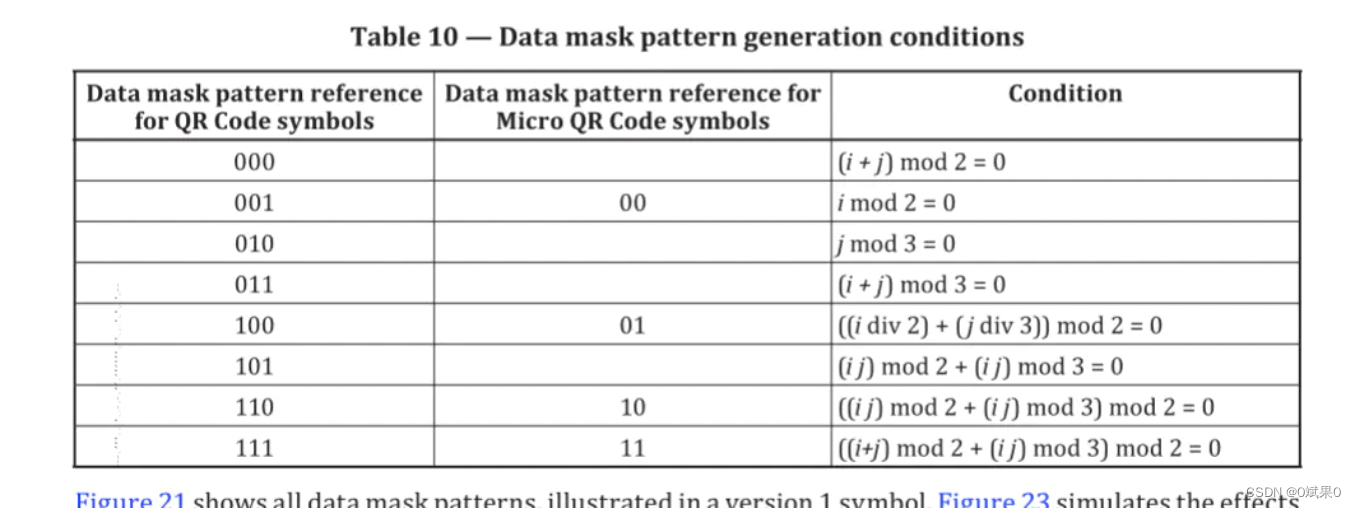
数据遮掩
为了保证二维码可以被可靠的古曲,亮色和暗色之间最好可以有一个比较好的分布形态。比如 模点1011101有可能会被识别为一个定位符号,为了避免这种情况,我们应该使用数据遮罩,按照下面讲的步骤。
数据遮罩层 不会适用于功能区域
2 根据给定的模式,对各个矩阵模式,对编码区域进行转换(版本信息和格式信息不包含在内)xor操作。所谓的xor操作,就是将矩阵中和遮罩层为黑色的进行反转运算。
3 尝试所有的遮罩模式,并且打分。打分通过检查不良的特征点。
4 选择分数最低的模式

最终生成图形

解码过程
1 从图像元素中,定位并且截取到符号的部分。 识别其中的深色,浅色模点,将其组成 0,1组成的比特序列。识别反射极性通过对定位符号色彩的识别。
2 读取(比特序列中的)格式信息,释放其中的遮罩层信息并且根据其中的纠错码得到格式信息模点。 如果这个时候成功了,说明当前是正常的方向,否则尝试从景象图像中读取格式信息。直接,从其中读取纠错码级别或者数据遮罩模式。在QR符号中,或者从MICRO QR符号数字中。
3 读取其中的版本信息(取决于应用程序),然后决定符号的版本。(如果是MICRO QR,则取决于区号的模点数量)
4 通过读取格式符号信息中其他信息,得到数据遮罩符号。 通过数据遮罩符号进行xor操作,解码得到编码区域的比特序列。
5 根据编码的排版规则读取符号的字符,还原数据和纠错码字组成的消息内容。
6 根据纠错码级别信息,拾取纠错码字当中的错误。如果发现存在错误,则纠正它。
7 根据数据中的模式标识符和数量标识符,将拆解出来的数据分别放置到对应的片段。

















 1257
1257

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









