




 本文介绍了ANTLR在编译器前端中的作用,包括词法分析、语法分析和抽象语法树的生成。ANTLR使得处理编程语言变得更加容易,同时探讨了正则表达式在文本处理中的局限性。文章详细阐述了编译原理中的概念,如上下文无关文法、LL(1)分析算法,并提到了消除二义性的方法。此外,还讨论了语义分析、中间代码生成和目标代码等编译器后续阶段的重要工作。
本文介绍了ANTLR在编译器前端中的作用,包括词法分析、语法分析和抽象语法树的生成。ANTLR使得处理编程语言变得更加容易,同时探讨了正则表达式在文本处理中的局限性。文章详细阐述了编译原理中的概念,如上下文无关文法、LL(1)分析算法,并提到了消除二义性的方法。此外,还讨论了语义分析、中间代码生成和目标代码等编译器后续阶段的重要工作。
识别和处理编程语言是 Antlr 的首要任务,编程语言的处理是一项繁重复杂的任务,为了简化处理,一般的编译技术都将语言处理工作分为前端和后端两个部分。其中前端包括词法分析、语法分析、语义分析、中间代码生成等若干步骤,后端包括目标代码生成和代码优化等步骤。
Antlr 致力于解决编译前端的所有工作(不包括目标代码生成)。使用 Anltr 的语法可以定义目标语言的词法记号和语法规则,Antlr 自动生成目标语言的词法分析器和语法分析器;此外,如果在语法规则中指定抽象语法树的规则,在生成语法分析器的同时,Antlr 还能够生成抽象语法树;最终使用树分析器遍历抽象语法树,完成语义分析和中间代码生成。整个工作在 Anltr 强大的支持下,将变得非常轻松和愉快。
文本处理
当需要文本处理时,首先想到的是正则表达式,使用 Anltr 的词法分析器生成器,可以很容易的完成正则表达式能够完成的所有工作;除此之外使用 Anltr 还可以完成一些正则表达式难以完成的工作,比如识别左括号和右括号的成对匹配等。
先来看一张图片

字符序列:程序代码存放在程序文本里的表现形式被词法分析后生成记号序列(ex: if (x > 5 ) 这样的 i f ( x > 5 ) 这样就叫一个个字符流)
词法分析:将字符序列解析成记号序列(了解转移图的概念)
记号序列:一个个token流
语法分析:检查这个程序的语法是否合法,符合语言规则, 然后在内存当中建立一个抽象语法树这样的数据结构.
语言规则: 三型文法(正则表达式) 二型文法(上下文无关文法) 一型文法(上下文有关文法) 零型文法(任意文法).
这里只讨论上下文无关文法
上下文无关文法是一个四元组G = (T, N, P, S) 其中T是终结符集合,N是非终结符集合, P是一组产生式规则用来联系终结符集 合和非终结符集合,S是唯一的开始符号. ex:如下图

分析树和二义性文法
E-> num
| id
| E + E
| E * E
能否推导出句子 3 + 4 * 5
显然通过下面两个推导式可看出上面的文法是一个二义性文法, 造成的后果就是会生成不同的分析树 如图(a) 和图(b)
E -> E + E
-> 3 + E
-> 3 + E * E
-> 3 + 4 * E
-> 3 + 4 * 5
E -> E * E
-> E + E * E
-> 3 + E * E
-> 3 + 4 * E
-> 3 + 4 * 5
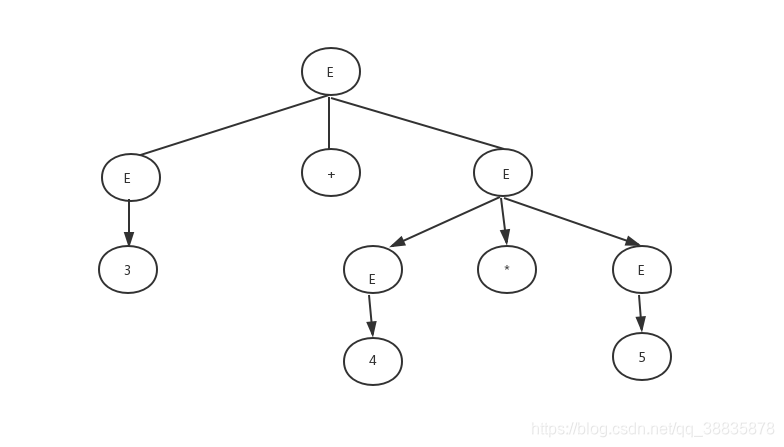
(图a)
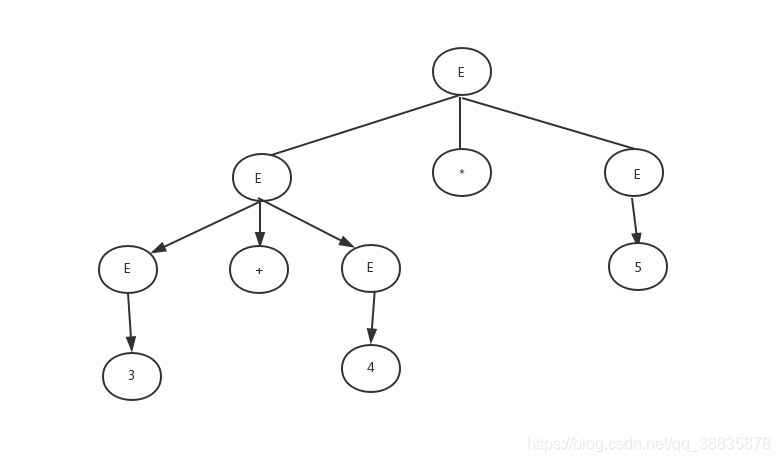
图(b)
对于二义性文法问题,解决方法主要就是通过重写文法.
(1) 自顶向下分析的算法思想
语法分析:给定文法G和句子s,回答s是否能从G推导出来,因为是从开始符号出发推出句子,因此称为自顶向下分析, 它会对每个非终结符以回溯的方式通过产生式规则来选择终结符,
(2) 递归下降分析算法 (分治法思想) N V N -> g d w 分成三部分(N 能不能推出g V能不能推出d N能不能推出w)
每个非终结符构造一个分析函数,用前看符号指导产生式规则的选择
(3)LL(1)分析算法:从左(L)向右读入程序,最左(L)推导,采用一个前看符号(1). 表驱动的分析算法. (基于递归下降分析)
First集定义: First(N) = 从非终结符N开始推导得出的句子开头的所有可能终结符集合(避免回溯)
对 N -> a => FIRST(N) ∪ = {a}
对 N -> M => FIRST(N) ∪ = FIRST(M)
为什么需要求FIRST集合:因为一个产生式存在多个候选式,选择哪一个候选式是不确定的,所以这就产生了回溯。回溯需要消耗大量的计算、存储空间,所以我们需要消除回溯。而消除回溯的其中一种方法叫作“预测”,即根据栈顶非终结符去预测后面的候选式,那预测方法就是求第一个非终结符,来判断是否和读头匹配,以达到预测的效果
NUAABLE集定义:非终结符X->或X属于集合NULLABLE,当且仅当 X -> Y1 ... Yn, Y1...Yn是n个非终结符,且都属NULLABLE
FOLLOW集:当某一非终结符的产生式中含有空产生式时,它的非空产生式右部的开始符号集两两不相交,并与在推导过程中紧跟该非终结符右部可能出现的终结符集也不相交,则仍可构造确定的自顶向下分析
为什么要有NULLABLE集和FOLLOW集参考地址:https://blog.youkuaiyun.com/liujian20150808/article/details/72998039(就是因为First集为空时,那么就需要看Follow集了)
一般条件下LL1分析表构造对于FIRST集一般情况下需要知道某个非终结符是否可以推出空串(NULLABLE)并且要知道某个非终结符后面跟着什么符号(FOLLOW).如下图

算完以后我们就可以得到任意串的FIRST集合了 伪代码如下:
foreach(production p)
FIRST_S(p) = {}
calculte_FIRST_S(production p: N->β1 … βn)
foreach (βi from β1 to βn)
if (βi== a …)
FIRST_S(p)∪= {a}
return;
if (βi== M …)
FIRST_S(p)∪= FIRST(M)
if (M is not NULLABLE)
return;
FIRST_S(p)∪= FOLLOW(N)
LL1冲突(面临栈顶元素和前看符号的时候不知道用哪个产生式规则来进行替换) , 他会导致算法进行回溯从而降低分析效率.
冲突检测:对N的两条产生式规则 N -> B 和 N -> Y要求FIRST_S(B) ∩ FIRST_S(Y) = {}
以上算法都是做语法分析, 用来回答程序语法是否合法, 但是编译器还需要完成后续工作 包括但不限于(类型检查、目标代码生成、中间代码生成), 这些后续工作一般可通过语法制导的翻译完成.
抽象语法树:是源代码的抽象语法结构的树状表示,树上的每个节点都表示源代码中的一种结构,这所以说是抽象的,是因为抽象语法树并不会表示出真实语法出现的每一个细节,比如说,嵌套括号被隐含在树的结构中,并没有以节点的形式呈现。抽象语法树并不依赖于源语言的语法,也就是说语法分析阶段所采用的上下文无关文法,因为在写文法时,经常会对文法进行等价的转换(消除左递归,回溯,二义性等),这样会给文法分析引入一些多余的成分,对后续阶段造成不利影响,甚至会使各个阶段变得混乱。因些,很多编译器经常要独立地构造语法分析树,为前端,后端建立一个清晰的接口。

语义分析:试图对抽象语法树的合法性做处理(一个变量在使用前是否被声明,调用的函数是否有相对应的定义),在这之后就可以保证程序没有任何语法或者语义错误了,理论上编译器就不应该再报任何错误了
中间代码:一种介于语言和目标语言之间的代码;
代码生成:将中间代码生成目标代码
目标代码:主要有3种形式:机器语言,汇编语言,待装配机器语言模块
符号表:存取了编译过程程序的相关重要信息, 每个阶段的工作都需要和它进行交互
看书的过程中备注一些额外学习到的知识点(Java虚拟机规定一个方法的字节码长度不超过65535字节、字符串常量存于class文件的常量池当中,理论上没有长度限制,但是编译期间会有限制,
String内部是以char数组的形式存储,数组的长度是int类型,那么String允许的最大长度就是Integer.MAX_VALUE = 2^31 - 1 = 2147483647。又由于java中的字符是以16位存储的,因此大概需要4GB的内存才能存储最大长度的字符串。
不过这仅仅是对字符串变量而言,如果是字符串常量,如“abc”、”1234”之类写在代码中的字符串str,那么允许的最大长度取决于字符串在常量池中的存储大小,也就是字符串在class格式文件中的存储格式:
CONSTANT_Utf8_info {
u1 tag;
u2 length;
u1 bytes[length];
}
u2是无符号的16位整数,因此理论上允许的string str的最大长度是2^16-1=65535。然而实际测试表明,允许的最大长度仅为65534,超过就编译错误。
)
visitor、listenor模式的区别:访问器必须显示触发对子节点的访问以便树的遍历过程能够正常进行,因为访问器机制需要显式调用方法来访问子节点,所以它能控制遍历过程中的访问顺序,监听器的优雅之处在于 我们不需要写出任何遍历语法分析树的代码,也不需要显式的访问子节点,遍历器会对传入的节点进行一个深度优先遍历,将其节点的所有子节点遍历完以后再退出.
listenor :
- 程序员不需要显示定义遍历语法树的顺序,实现简单
- 缺点,也是不能显示控制遍历语法树的顺序,visit方式可以
- 动作代码与文法产生式解耦,利于文法产生式的重用
- 没有返回值,需要使用map、栈等结构在节点间传值
visitor
- 程序员可以显示定义遍历语法树的顺序
- 不需要与antlr遍历类ParseTreeWalker一起使用,直接对tree操作
- 动作代码与文法产生式解耦,利于文法产生式的重用
- visitor方法可以直接返回值,返回值的类型必须一致,不需要使用map这种节点间传值方式,效率高
https://cntofu.com/book/115/calculator-listener.md 代码参考
我们会生成一个访问器接口,然后手动编写该接口的实现类来进行节点的visit遍历。 最后在自己的逻辑中调用该实现类的visit方法来访问这个类获取相关的节点信息。
https://m.aliyun.com/yunqi/articles/119342 关于visitor和lisener模式对AST遍历的了解.
https://saumitra.me/blog/antlr4-visitor-vs-listener-pattern/ 又发现了个老外大牛的文章 这个对比会比较清晰
There are 3 primary differences:
- Listener methods are called automatically by the ANTLR provided walker object, whereas visitor methods must walk their children with explicit visit calls. Forgetting to invoke visit() on a node’s children means those subtrees don’t get visited
- Listener methods can’t return a value, whereas visitor methods can return any custom type. With listener, you will have to use mutable variables to store values, whereas with visitor there is no such need.
- Listener uses an explicit stack allocated on the heap, whereas visitor uses call stack to manage tree traversals. This might lead to StackOverFlow exceptions while using visitor on deeply nested ASTs

















 7428
7428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









