 间隙锁与死锁:防止幻读的原理与实例分析
间隙锁与死锁:防止幻读的原理与实例分析




 文章探讨了间隙锁在数据库中的作用,主要是为了防止幻读,阻止间隙内数据的插入和已有数据更新到间隙内。通过一个死锁场景的复盘,解释了当两个事务分别持有无限范围的间隙锁时,尝试插入数据可能导致死锁的情况。内容涉及数据库事务处理和InnoDB存储引擎的锁机制。
文章探讨了间隙锁在数据库中的作用,主要是为了防止幻读,阻止间隙内数据的插入和已有数据更新到间隙内。通过一个死锁场景的复盘,解释了当两个事务分别持有无限范围的间隙锁时,尝试插入数据可能导致死锁的情况。内容涉及数据库事务处理和InnoDB存储引擎的锁机制。
如果删除索引的数据不存在,会出现一个间隙锁,区间(左边最近第一个值, 右边最近第一个值), 间隙锁之间是不会冲突的,只有往间隙中插入数据的操作,才会被阻塞。
重温间隙锁目的:
间隙锁的目的是为了防止幻读,其主要通过两个方面实现:
(1)防止间隙内有新数据被插入
(2)防止已存在的数据,更新成间隙内的数据(例如防止numer=3的记录通过update变成number=5)
死锁场景流程复盘:开启事务,任务数据先执行批量删除操作,然后执行插入操作, 出现死锁。
数据表
CREATE TABLE `task` (
`uid` int(11) NOT NULL,
`task_id` int(11) NOT NULL,
`state` int(11) DEFAULT NULL,
`sub_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`uid`,`task_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='任务数据';
-
空表的情况下, 删除操作都可以,从提示看没有改动数据
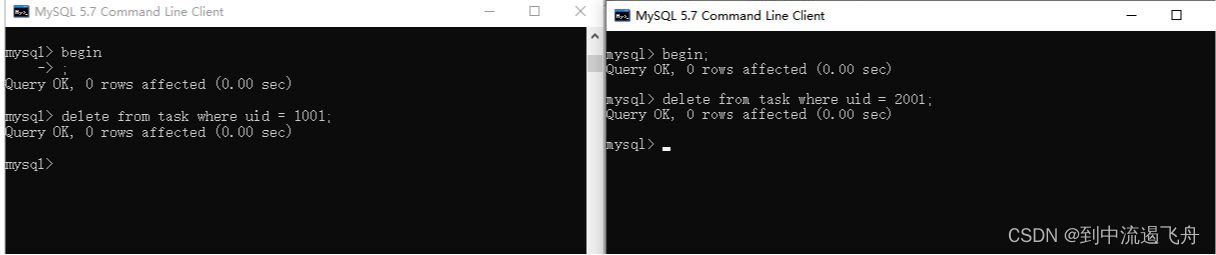
2. 开始分别插入一些数据, 左边阻塞了,然后我们看锁表的信息
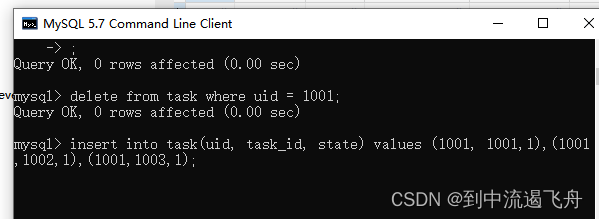
3. 查看INNODB_LOCKS 表
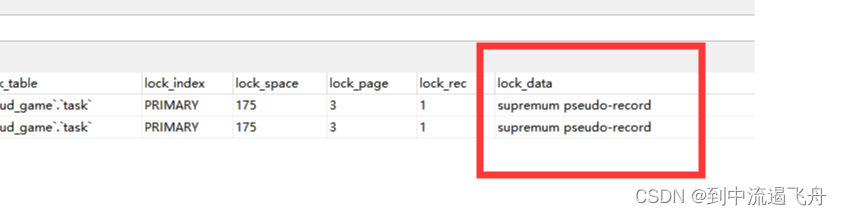
suprenum 表示超过索引中的最大值,也就是说 两个事务的间隙锁 范围都是 (-∞, +∞),左边 执行insert 的事务正在等待右边释放锁,这时候如果右边事务也执行insert 就死锁了……

















 1359
1359

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









