




LLaMA Adapter论文地址:
https://arxiv.org/pdf/2303.16199.pdf
LLaMA Adapter V2论文地址:
https://arxiv.org/pdf/2304.15010.pdf
LLaMA Adapter效果展示地址:
LLaMA Adapter 双语多模态通用模型 为你写诗 - 知乎
LLaMA Adapter GitHub项目地址:
https://github.com/OpenGVLab/LLaMA-Adapter
LLaMA Adapter V2 GitHub项目地址(包含在LLaMA-Adapter项目中):
https://github.com/OpenGVLab/LLaMA-Adapter/tree/main/llama_adapter_v2_multimodal7b
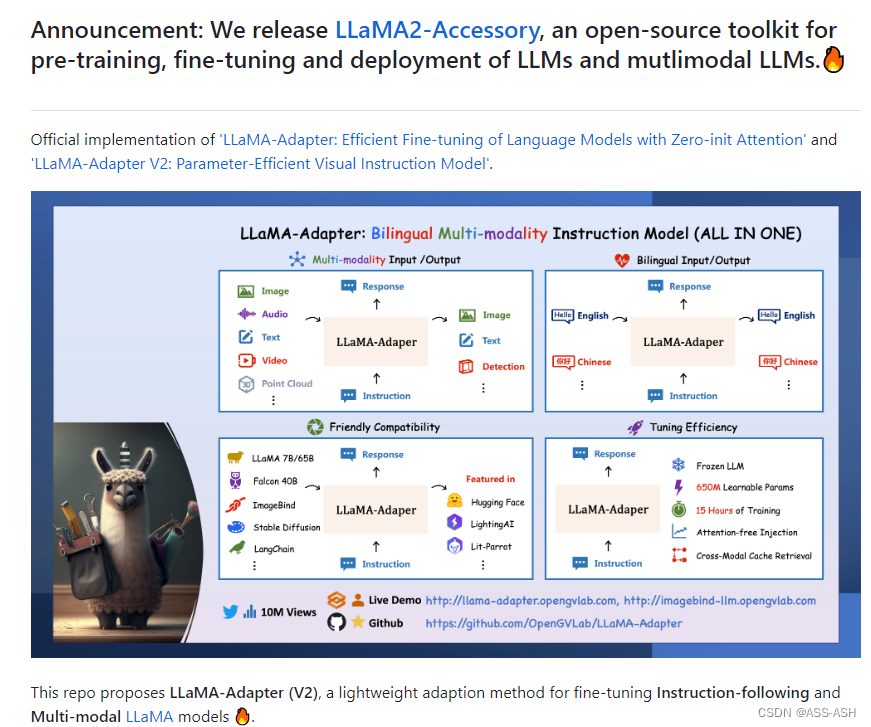
LLaMA-Adapter简介
LLaMA-Adapter是一个参数高效的多模态指令模型
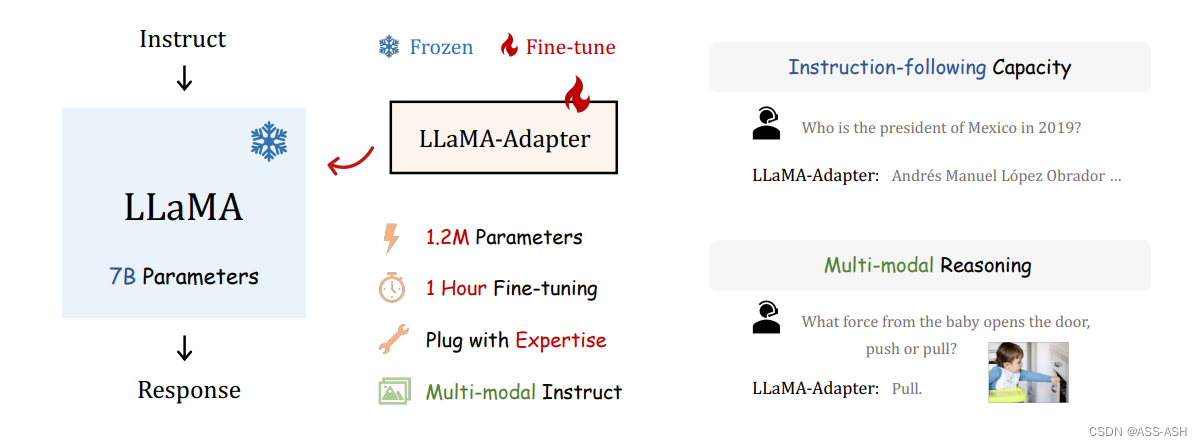
论文作者提出了 LLaMA-Adapter,一种轻量级的适应方法,可以有效地将 LLaMA 微调为一个跟随指令的模型。LLaMA-Adapter 使用 52K 个自我指示的样例,在冻结的 LLaMA 7B 模型上只引入了 120 万个可学习参数,在 8 个A100 GPU 上进行微调的成本不到 1 小时。
具体来说,作者采用了一组可学习的适应性提示,并将其预置在较高 Transformer 层的输入文本标记上。
然后,作者提出了一个具有零初始(zero-init)的注意力机制,该机制可以自适应地将新的训练线索注入到 LLaMA 中,同时有效地保留了其预训练的知识。通过有效的训练,LLaMA-Adapter 产生了高质量的反应,与具有完全微调的 7B 参数的 Alpaca 相当。
此外,该方法可以简单地扩展到多模态的输入,例如图像,多模态模型在 ScienceQA 上实现了卓越的推理能力。
特点
LLaMA-Adapter具有如下四个特点:
1、掌握多种模态:
LLaMA-Adapter 能够无缝整合多种输入模态,如图像、音频、文本、视频和3D点云等,并提供图像、文本和检测输出。
2、支持双语功能:
LLaMA-Adapter 具有双语功能,能够支持中英双语输入输出。
3、强大的兼容性:
LLaMA-Adapter 有强大的兼容性,兼容LLaMA,Falcon,ImageBind,StableDiffusion,LangChain等,并且目前已得到HuggingFace和Lightning AI 的大力支持。
4、参数高效:
LLaMA-Adapter 在冻结的语言模型上只引入了650M的参数,在8张A100显卡上只需15小时就能完成训练。此外,LLaMA-Adapter提供无需注意力的多模态注入,并支持跨模态缓存检索。
LLaMA-Adapter V2 论文简略解读
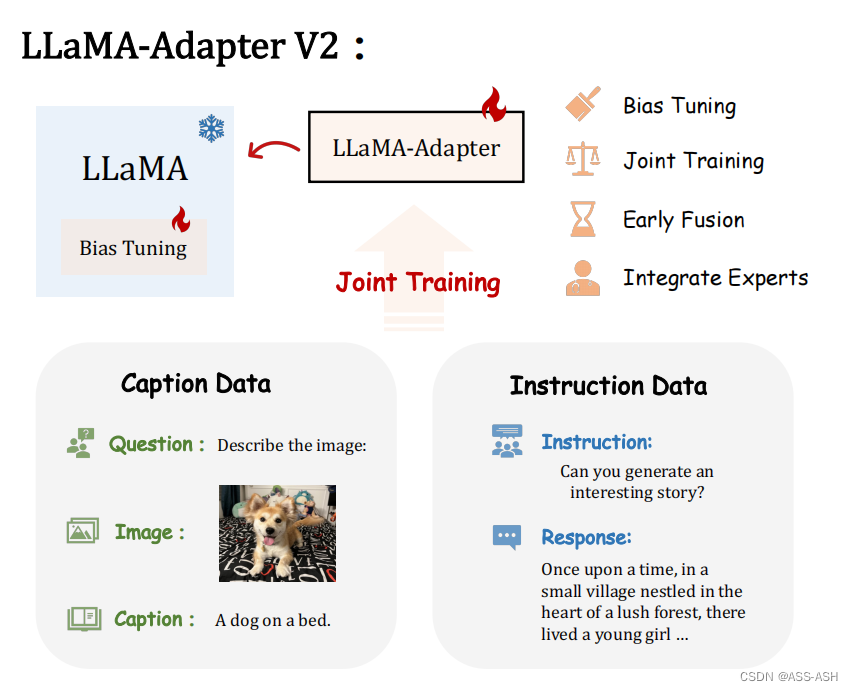
摘要
如何有效地将大型语言模型(LLM)转化为指令跟随器是最近一个热门的研究方向,而训练 LLM 进行多模态推理的探索仍然较少。尽管最近的 LLaMA-Adapter 展示了使用 LLM 处理视觉输入的潜力,但它仍然不能很好地泛化到开放式视觉指令,并且落后于 GPT-4。在本文中,作者提出了LLaMA-Adapter V2,一种参数高效的视觉指令模型。具体来说,作者首先通过解锁更多可学习参数(例如范数、偏差和比例)来增强 LLaMAAdapter,这些参数将指令遵循能力分布到整个 LLaMA 模型中,除了适配器之外。其次,作者提出了一种早期融合策略,仅将视觉标记提供给早期的 LLM 层,有助于更好地整合视觉知识。第三,通过优化不相交的可学习参数组,引入了图像-文本对和指令跟随数据
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 234
234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









