






数据及账号准备
首先您需要将数据上传至您的MongoDB数据库。本例中使用阿里云的云数据库 MongoDB 版,网络类型为VPC(需申请公网地址,否则无法与DataWorks默认资源组互通),测试数据如下。
{
"store": {
"book": [
{
"category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{
"category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{
"category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
},
"expensive": 10
}登录MongoDB的DMS控制台,本例中使用的数据库为 admin,集合为 userlog,您可以在查询窗口使用db.userlog.find().limit(10)命令查看已上传好的数据,如下图所示。 
此外,需提前在数据库内新建用户,用于DataWorks添加数据源。本例中使用命令db.createUser({user:"bookuser",pwd:"123456",roles:["root"]}),新建用户名为 bookuser,密码为 123456,权限为root。
使用DataWorks提取数据到MaxCompute
- 新增MongoDB数据源
进入DataWorks数据集成控制台,新增MongoDB类型数据源。

具体参数如下所示,测试数据源连通性通过即可点击完成。由于本文中MongoDB处于VPC环境下,因此 数据源类型需选择 有公网IP。
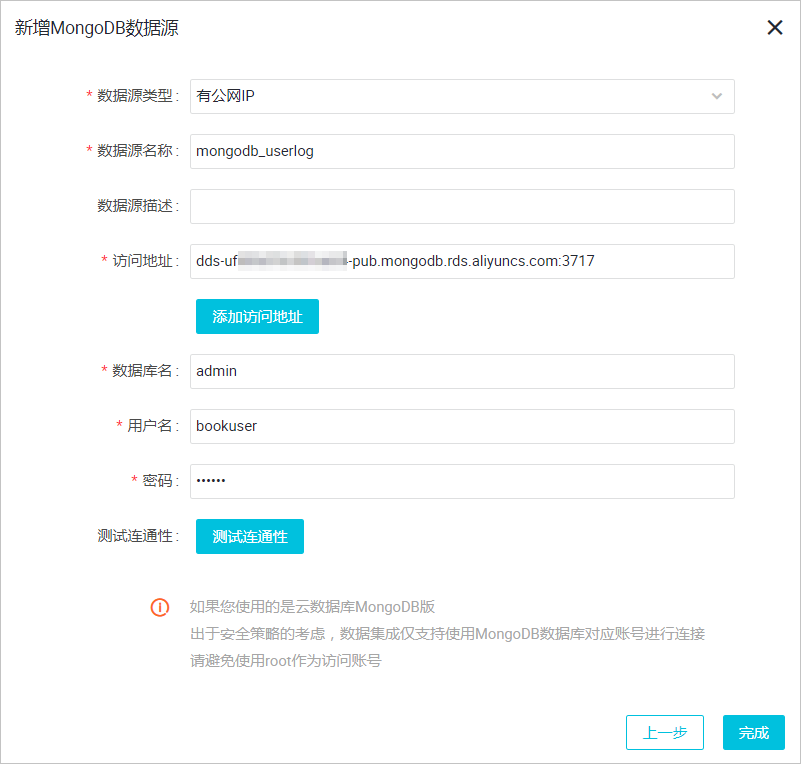
访问地址及端口号可通过在MongoDB管理控制台点击实例名称获取,如下图所示。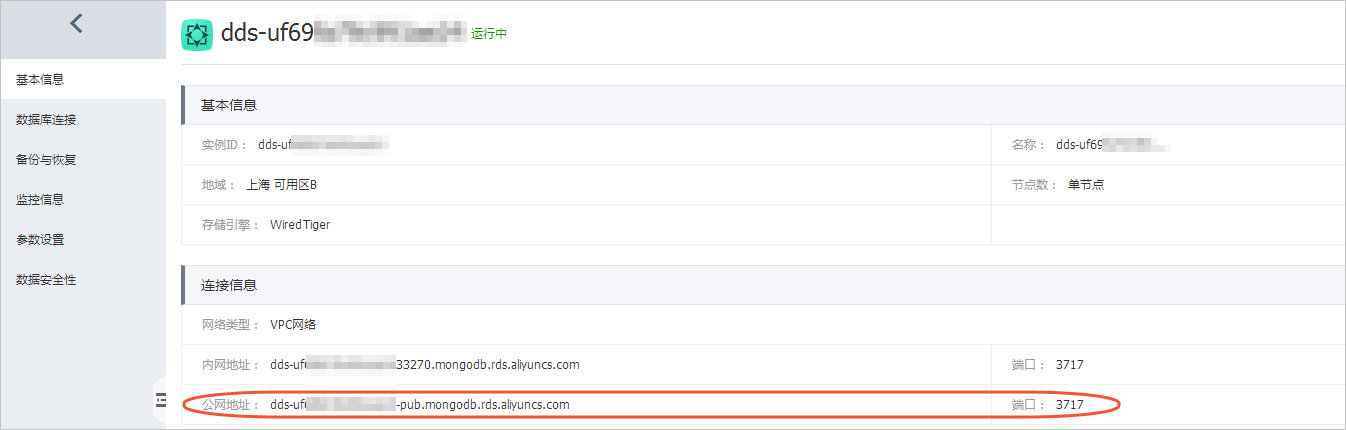
- 新建数据同步任务在DataWorks上新建数据同步类型节点。

新建的同时,在DataWorks新建一个建表任务,用于存放JSON数据,本例中新建表名为mqdata。
表参数可以通过图形化界面完成。本例中mqdata表仅有一列,类型为string,列名为MQ data。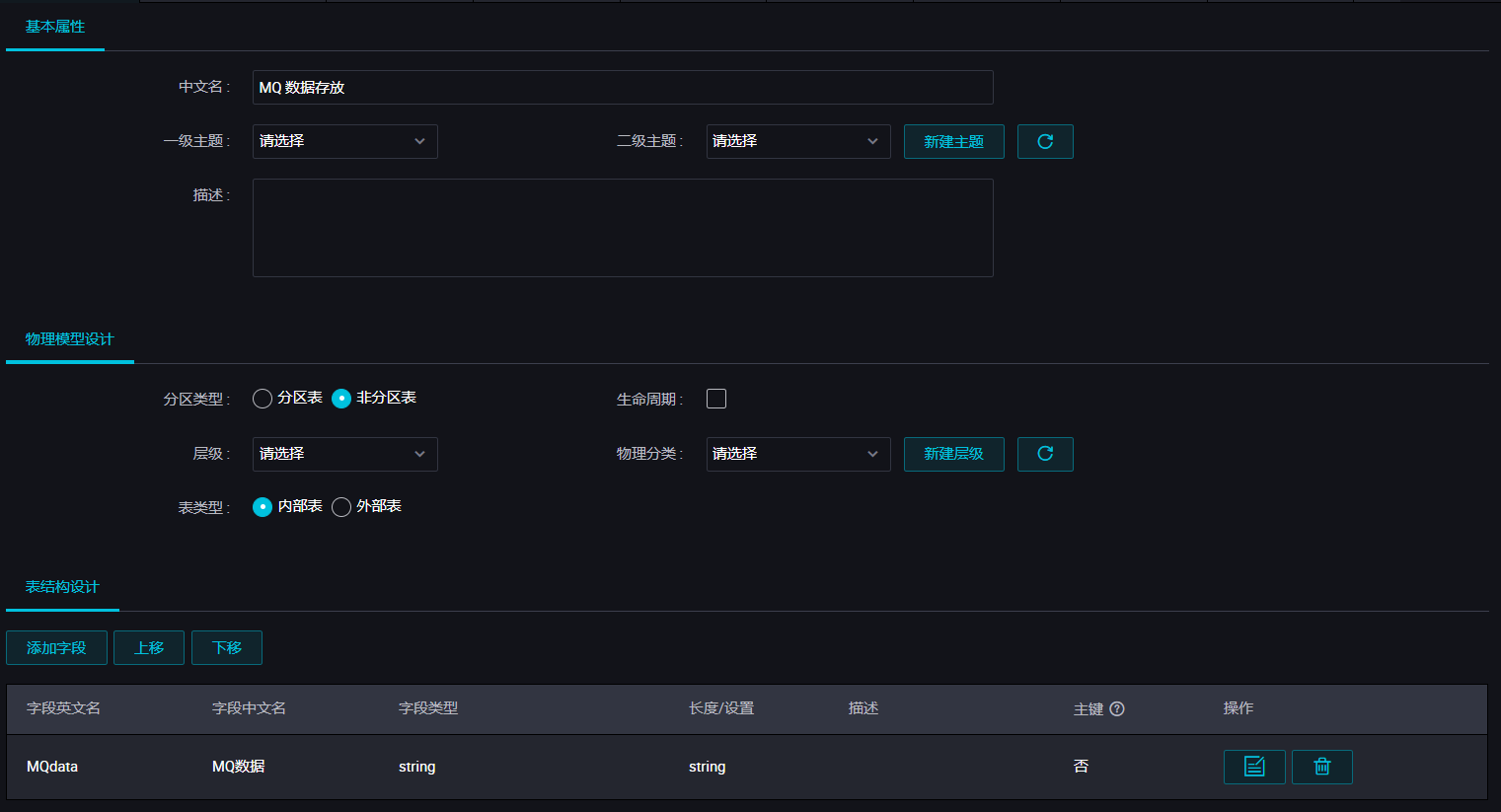
完成上述新建后,您可以在图形化界面进行数据同步任务参数的初步配置,如下图所示。选择目标数据源名称为odps_first,选择目标表为刚建立的mqdata。数据来源类型为MongoDB,选择我们刚创建的数据源mongodb_userlog。完成上述配置后, 点击转换为脚本,跳转到脚本模式。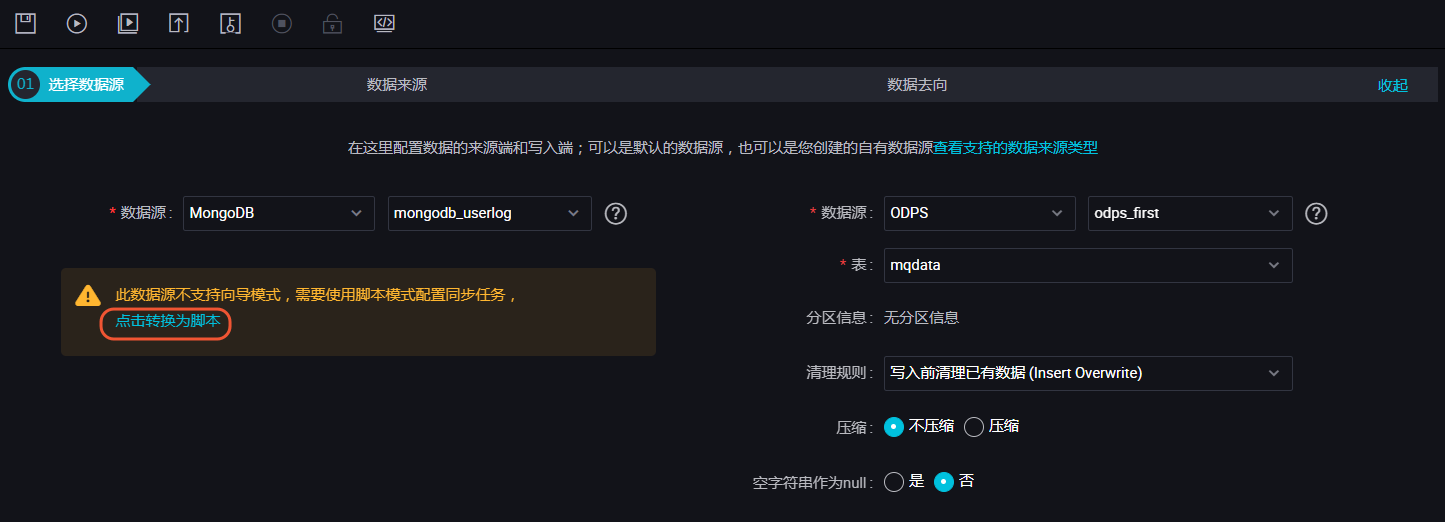
脚本模式代码示例如下。
完成上述配置后,点击运行接即可。运行成功日志示例如下所示。{ "type": "job", "steps": [ { "stepType": "mongodb", "parameter": { "datasource": "mongodb_userlog", //数据源名称 "column": [ { "name": "store.bicycle.color", //JSON字段路径,本例中提取color值 "type": "document.document.string" //本栏目的字段数需和name一致。假如您选取的JSON字段为一级字段,如本例中的expensive,则直接填写string即可。 } ], "collectionName //集合名称": "userlog" }, "name": "Reader", "category": "reader" }, { "stepType": "odps", "parameter": { "partition": "", "isCompress": false, "truncate": true, "datasource": "odps_first", "column": [ //MaxCompute表列名 "mqdata" ], "emptyAsNull": false, "table": "mqdata" }, "name": "Writer", "category": "writer" } ], "version": "2.0", "order": { "hops": [ { "from": "Reader", "to": "Writer" } ] }, "setting": { "errorLimit": { "record": "" }, "speed": { "concurrent": 2, "throttle": false, "dmu": 1 } } }
结果验证
在您的业务流程中新建一个ODPS SQL节点。 
您可以输入 SELECT * from mqdata;语句,查看当前mqdata表中数据。当然这一步您也可以直接在MaxCompute客户端中输入命令运行。 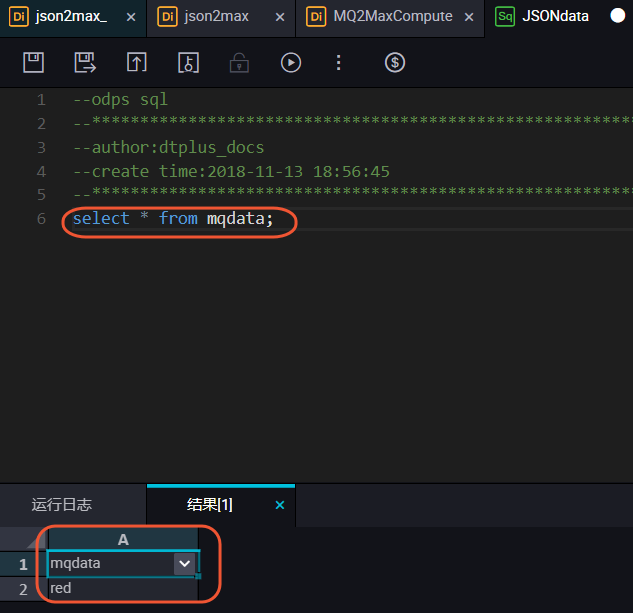
更多技术干货 请关注阿里云云栖社区微信号 :yunqiinsight

















 1140
1140

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









