




 本文介绍Lucene和Solr的原理及应用,包括数据分类、全文检索实现、索引与搜索流程、开发环境配置等内容。同时,还详细介绍了Solr的安装配置、schema.xml配置、中文分词器配置、后台管理页面操作、数据导入及SolrJ的使用。
本文介绍Lucene和Solr的原理及应用,包括数据分类、全文检索实现、索引与搜索流程、开发环境配置等内容。同时,还详细介绍了Solr的安装配置、schema.xml配置、中文分词器配置、后台管理页面操作、数据导入及SolrJ的使用。
文章目录
1.数据分类
- 结构化数据
- 指具体固定格式或有限长度的数据,如数据库,元数据等。
- 非结构数据:指不定长或无固定格式的数据,如邮件,word文档等磁盘上的文件。
- 查询方法:
- 顺序扫描法:就一个个文档看
- 全文检索: 将非结构的数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的,这部分从非结构化的数据中提取出来的然后重新组织的信息,我们称之为
索引。这种先建立索引,再对索引进行搜索的过程就叫全文检索
- 查询方法:
2.如何实现全文检索
Lucene可以实现全文检索,它是为软件开发人员提供的简单易用的工具包,以方便的再目标系统中实现全文检索的功能。
3.索引和搜索流程
-
索引过程:对要搜索的原始内容进行索引构建一个索引库
确定原始内容(搜索的内容) → \to →采集文档 → \to →创建文档 → \to →分析文档 → \to →索引文档- 创建文档对象:获取原始内容的目的是为例索引,在索引前需要将原始内容创建文档,文档中包括一个个的域(Field),域中包括存储内容。
注意:每个Doucument可以有多个Field,不同的Document可以有不同的Field,同一个Document可以有相同的Field(域值和域名都相同);每个文档都有一个唯一的编号,就是文档的id. - 分析文档:将原始内容创建为包含域(Field)的文档(document),需要再对域中的内容进行分析,分析的过程是经过对原始文档提取单词,将字母转为小写、去除停用词的过程生成最终的语汇单元,可以将语汇单元理解为一个个的单词;每个单词叫做一个Term,不同的域中拆分出来的相同的单词是不同的term,term中包含两部分,一部分是文档的域名,另一部分是单词的内容。
- 创建索引: 对所有文档分析得出的语汇单元进行索引,索引的目的是为了搜索,最终要实现只索被索引的语汇单元从而找到Document(文档);
注意:创建索引是对语汇单元索引,通过词语找文档,这种索引结构叫做倒排索引结构,也叫反向索引结构,包括索引和文档两部分,索引即词汇表,它的规模较小,而文档集合较大。
- 创建文档对象:获取原始内容的目的是为例索引,在索引前需要将原始内容创建文档,文档中包括一个个的域(Field),域中包括存储内容。
-
搜索过程:从索引库中搜索内容搜素界面 → \to →创建查询 → \to →执行搜索 → \to →从索引库搜索 t o to to渲染搜索结果
- 用户查询接口: 全文检索系统提供用户搜索的界面供用户提交搜索的关键字,搜索完成展示搜索结果
- 创建查询:用户输入查询关键字执行搜索之前需要先构建一个查询对象,查询对象中可以指定查询要搜索的Field文档域,查询关键字等,查询对象会生成具体的查询语法。
- 执行查询:根据查询语法在倒排索引词典表中分别找出对应的搜索词的索引,从而找到索引所链接的文档链表。
- 渲染结果:
4.配置开发环境
- 创建索引库
- 创建一个java过程,并导入jar包
- 创建一个indexwriter对象
1.) 指定索引库的存放位置Directory对象
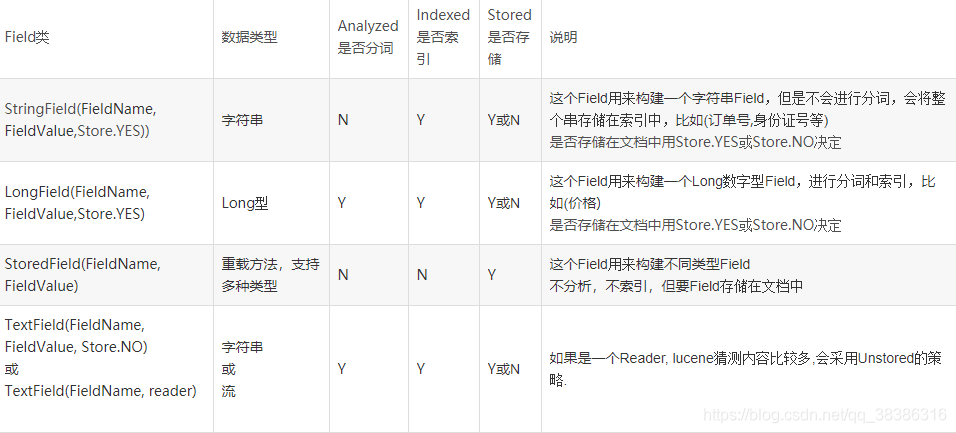
2.) 指定一个分析器,对文档内容进行分析 - 创建document对象
- 创建field对象,将field添加到document对象中
- 使用indexwriter对象将document对象写入索引库,此过程进行索引创建,并将索引和document对象写入索引库.
- 关闭IndexWriter对象
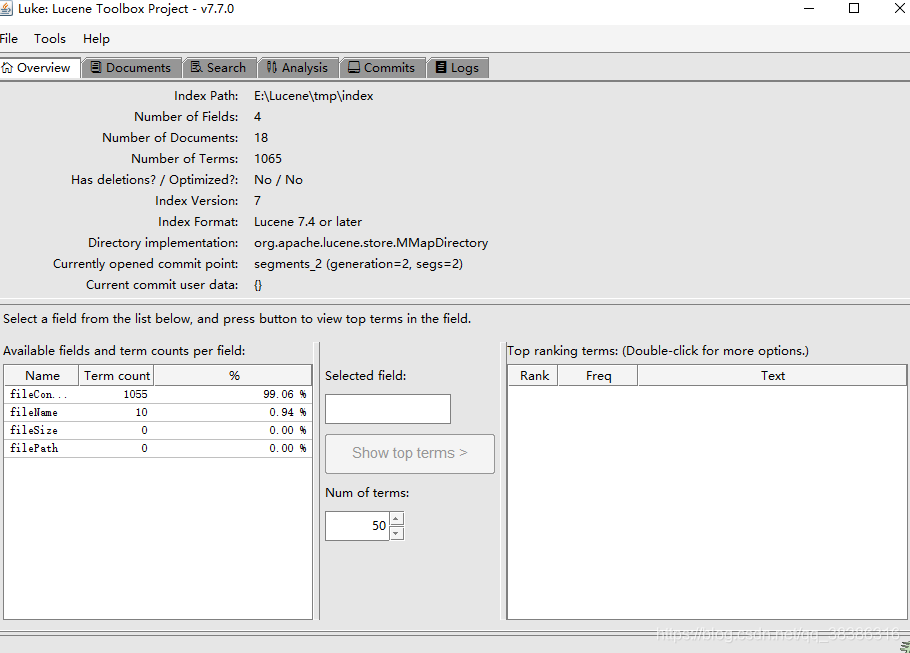
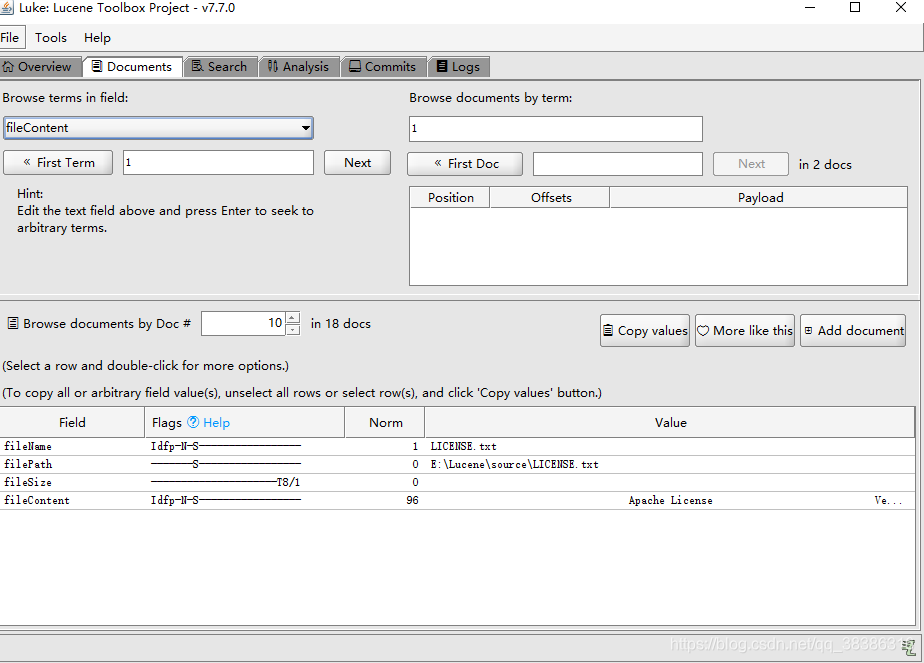
- 建立索引库的部分就结束了,可以使用luke工具产看索引库的内容。
下载地址: https://github.com/DmitryKey/luke/tags
需要下载合适自己的lucene的版本对应才可以;打开方式:解压后打开luke.bat,选择自己的索引库地址,显示如下:
- 搜索过程
| 方法 | 说明 |
|---|---|
| indexSearcher.search(query, n) | 根据Query搜索,返回评分最高的n条记录 |
| indexSearcher.search(query, filter, n) | 根据Query搜索,添加过滤策略,返回评分最高的n条记录 |
| indexSearcher.search(query, n, sort) | 根据Query搜索,添加排序策略,返回评分最高的n条记录 |
| indexSearcher.search(query,filter ,n, sort) | 根据Query搜索,添加过滤策略,添加排序策略,返回评分最高的n条记录 |
- 创建一个Directory对象,也就是索引库存放的位置
- 创建一个indexReader对象,需要指定Directory对象
- 创建一个indexsearch对象,需要指定IndexReader对象
- 创建一个TermQuery对象,指定查询的域和查询的对象
- 执行查询。
- 返回查询的结果,遍历查询的 结果并输出
- 关闭IndexReader对象
- 添加额外的分词器IKAnalyzer
- 下载地址:https://storage.googleapis.com/google-code-archive-downloads/v2/code.google.com/ik-analyzer/IK Analyzer 2012FF_hf1.zip
- 高版本的lucene使用IKAnalyzer会报错:
java.lang.AbstractMethodError,可以百度一下 - 高版本的lunece需要对其作相应的改动,但我不会改,可以在github找大佬们改好的jar包:https://github.com/magese/ik-analyzer-solr
- 7.7.x版本的lucene对应的IKAnalyzer版本 https://dl-download.youkuaiyun.com/down11/20190102/ae646f97baf1b8dccc85620cc7b9377f.jar?response-content-disposition=attachment%3Bfilename%3D"ik-analyzer-7.6.0.jar"&OSSAccessKeyId=9q6nvzoJGowBj4q1&Expires=1563450007&Signature=2qM44XsnDa%2FOY%2FVDW%2Fze1L5TFNg%3D&user=qq_38386316&sourceid=10890903&sourcescore=0&isvip=0
- 除了在工程中添加IKAnalyzer对应的jar包,还要在src下添加如下两个文件。
package com.zcs;
/*
* 查询索引
*/
import java.io.File;
import java.nio.file.Paths;
import java.util.concurrent.ExecutionException;
import org.apache.commons.io.FileUtils;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.LongPoint;
import org.apache.lucene.document.NumericDocValuesField;
import org.apache.lucene.document.StoredField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
import org.junit.Test;
import org.wltea.analyzer.lucene.IKAnalyzer;
public class FirstLucene{
@Test
public void testIndex() throws Exception {
// 1. 创建一个java过程,并导入jar包
// 2. 创建一个indexwriter对象
Directory directory = FSDirectory.open(Paths.get("E:\\Lucene\\tmp\\index"));
Analyzer analyzer = new IKAnalyzer();//官方推荐
//获得
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);
IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig);
// 1.) 指定索引库的存放位置Directory对象
// 2.) 指定一个分析器,对文档内容进行分析
// 3. 创建document对象
// 4. 创建field对象,将field添加到document对象中
File f = new File("E:\\Lucene\\source");
File[] listFiles = f.listFiles();
for(File file : listFiles) {
Document document = new Document();
//文件名称
String file_name = file.getName();
Field fileNameField = new TextField("fileName", file_name, Store.YES);
//文件路径
String file_path = file.getPath();
Field filePathField = new StoredField("filePath", file_path);
//文件大小
long file_size = FileUtils.sizeOf(file);
//同时添加排序支持
// doc.add(new NumericDocValuesField("fileSize",file.length()));
Field fieSizeField = new LongPoint("fileSize", file_size);
//文件内容
String file_content = FileUtils.readFileToString(file);
Field fileContenTextField = new TextField("fileContent", file_content, Store.YES);
document.add(fileNameField);
document.add(filePathField);
document.add(fieSizeField);
//同时添加存储支持
document.add(new StoredField("fileSize",file_size));
document.add(new NumericDocValuesField("fileSize",file_size));
document.add(fileContenTextField);
indexWriter.addDocument(document);
}
// 5. 使用indexwriter对象将document对象写入索引库,此过程进行索引创建,并将索引和document对象写入索引库
// 6.关闭IndexWriter对象
indexWriter.close();
}
@Test
public void testSearch() throws Exception {
//1.创建一个Directory对象,也就是索引库存放的位置
Directory directory = FSDirectory.open(Paths.get("E:\\Lucene\\tmp\\index"));
//2.创建一个indexReader对象,需要指定Directory对象
IndexReader indexReader = DirectoryReader.open(directory);
//3.创建一个indexsearch对象,需要指定IndexReader对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//4.创建一个TermQuery对象,指定查询的域和查询的对象
Query query = new TermQuery( new Term("fileName", "txt") );
//5.执行查询。
TopDocs topDocs = indexSearcher.search(query, 2);
//6.返回查询的结果,遍历查询的 结果并输出
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for(ScoreDoc scoreDoc : scoreDocs) {
int doc = scoreDoc.doc;
Document document = indexSearcher.doc(doc);
//文件名字
String fileName = document.get("fileName");
System.out.println(fileName);
//文件路径
String filePath = document.get("filePath");
System.out.println(filePath);
//文件大小
String fileSize = document.get("fileSize");
System.out.println(fileSize);
//文件内容
String fileContent = document.get("fileContent");
System.out.println(fileContent);
System.out.println("----------------------");
}
//7.关闭IndexReader对象
indexReader.close();
}
}
4. 索引库的维护
- 添加
- 删除
- 全删
- 条件删除
- 修改
5.索引库的查询
-
使用query的子类查询
- MatchAllDocsQuery
- TermQuery
- NumericRangeQuery
- BooleanQuery
-
使用queryparse查询
- QueryParse
- MultiFieldQueryParser
- 解析语法参考文档: http://lucene.apache.org/core/2_9_4/queryparsersyntax.html
package com.zcs;
import java.io.IOException;
import java.nio.file.Paths;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.LongPoint;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.queryparser.classic.MultiFieldQueryParser;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.BooleanClause;
import org.apache.lucene.search.BooleanQuery;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.MatchAllDocsQuery;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.junit.Test;
import org.wltea.analyzer.lucene.IKAnalyzer;
public class LuceneManager {
public IndexWriter getIndexWriter() throws IOException {
// 1. 创建一个java过程,并导入jar包
// 2. 创建一个indexwriter对象
Directory directory = FSDirectory.open(Paths.get("E:\\Lucene\\tmp\\index"));
Analyzer analyzer = new IKAnalyzer();//官方推荐
//获得
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);
return new IndexWriter(directory, indexWriterConfig);
}
//删除
@Test
public void testAllDelete() throws IOException {
IndexWriter indexWriter = getIndexWriter();
indexWriter.deleteAll();
indexWriter.close();
}
//条件删除
@Test
public void testDelete() throws IOException {
IndexWriter indexWriter = getIndexWriter();
Query query = new TermQuery(new Term("fileName", "spring"));
indexWriter.deleteDocuments(query);
indexWriter.close();
}
//修改
@Test
public void testUpdate() throws IOException {
IndexWriter indexWriter = getIndexWriter();
Document document = new Document();
document.add(new TextField("fileA", "测试修改文件名",Store.YES));
document.add(new TextField("fileB", "测试修改文件名",Store.YES));
indexWriter.updateDocument(new Term("filename", "springboot"), document);
indexWriter.close();
}
//查询
public IndexSearcher getIndexSearcher() throws IOException {
//1.创建一个Directory对象,也就是索引库存放的位置
Directory directory = FSDirectory.open(Paths.get("E:\\Lucene\\tmp\\index"));
//2.创建一个indexReader对象,需要指定Directory对象
IndexReader indexReader = DirectoryReader.open(directory);
//3.创建一个indexsearch对象,需要指定IndexReader对象
return new IndexSearcher(indexReader);
}
//执行查询的 结果
public void printResult(IndexSearcher indexSearcher, Query query) throws IOException {
TopDocs topDocs = indexSearcher.search(query, 12);
//6.返回查询的结果,遍历查询的 结果并输出
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for(ScoreDoc scoreDoc : scoreDocs) {
int doc = scoreDoc.doc;
Document document = indexSearcher.doc(doc);
//文件名字
String fileName = document.get("fileName");
System.out.println(fileName);
//文件路径
String filePath = document.get("filePath");
System.out.println(filePath);
//文件大小
String fileSize = document.get("fileSize");
System.out.println(fileSize);
//文件内容
String fileContent = document.get("fileContent");
System.out.println(fileContent);
System.out.println("----------------------");
}
}
//查询所有
@Test
public void testMatchAllDocsQuery() throws IOException {
IndexSearcher indexSearcher = getIndexSearcher();
Query query = new MatchAllDocsQuery();
printResult(indexSearcher, query);
//关闭资源
indexSearcher.getIndexReader().close();
}
//根据数值范围查询
@Test
public void testNumericRangeQuery() throws IOException {
IndexSearcher indexSearcher = getIndexSearcher();
Query query = LongPoint.newRangeQuery("fileSize", 100L, 300L);
printResult(indexSearcher, query);
indexSearcher.getIndexReader().close();
}
//组合查询
@Test
public void testBooleanQuery() throws IOException {
IndexSearcher indexSearcher = getIndexSearcher();
Query query1 = new TermQuery(new Term("fileName", "spring"));
Query query2 = new TermQuery(new Term("fileContent", "java"));
BooleanQuery.Builder builder = new BooleanQuery.Builder();
builder.add(query1, BooleanClause.Occur.MUST);
builder.add(query2, BooleanClause.Occur.MUST);
BooleanQuery query = builder.build();
printResult(indexSearcher, query);
indexSearcher.getIndexReader().close();
}
//条件解析查询
@Test
public void testQueryParser() throws IOException, ParseException {
IndexSearcher indexSearcher = getIndexSearcher();
QueryParser queryParser = new QueryParser("fileName", new IKAnalyzer());
//*:* ->查询所有
Query query = queryParser.parse("fileSize:[200 TO 300]");
printResult(indexSearcher, query);
indexSearcher.getIndexReader().close();
}
//条件解析的对象查询多个默认域
@Test
public void testMultiFieldQueryParser() throws IOException, ParseException {
IndexSearcher indexSearcher = getIndexSearcher();
String[] fields = {"fileName", "fileContent"};
MultiFieldQueryParser queryParser = new MultiFieldQueryParser(fields, new IKAnalyzer());
//*:* ->查询所有
Query query = queryParser.parse("fileName: spring AND fileContent: java");
printResult(indexSearcher, query);
indexSearcher.getIndexReader().close();
}
}
6 solr的介绍
Lucene是一个开放源代码的全文检索引擎工具包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎.
Solr是一个高性能,采用Java5开发,基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Solr Get操作提出查找请求,并得到XML格式的返回结果;
Solr和Lucene的本质区别有以下三点:搜索服务器,企业级和管理。Lucene本质上是搜索库,不是独立的应用程序,而Solr是。Lucene专注于搜索底层的建设,而Solr专注于企业应用。Lucene不负责支撑搜索服务所必须的管理,而Solr负责。所以说,一句话概括Solr: Solr是Lucene面向企业搜索应用的扩展
7. solr7.7.2的安装与tomcat的配置
- 系统环境准备:
- win10 x64
- tomcat 9.0.22 下载地址:https://tomcat.apache.org/download-90.cgi
- jdk 1.8
- solr 7.7.2 下载地址 https://lucene.apache.org/solr/downloads.html
- 在tomcat下的webapps目录下创建solr目录,将
solr-7.7.2/server/solr-webapp/webapp/目录下的所有文件复制到刚才创建的solr目录。 - 将solr的依赖jar包复制到
tomcat下的webapps目录下创建solr目录的WEB-INF/lib/下solr-7.7.2\server\lib\ext的jar复制过去,如果有冲突的,跳过solr-7.7.2\server\lib下的jar复制过去。
- 在任意目录下创建
solrhome目录,并将solr-7.7.2server/solr/*下的内容复制过去。 - 修改
tomcat下的webapps目录下创建solr目录的WEB-INF/web.xml文件内容,指定刚才的solrhome的位置,(如果web.xml里面没有修改路径的这部分代码,就添加进去)并注释security-constraint权限内容。
<!-- 修改solrhome路径 -->
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>D:\GIS\apache-tomcat-7.0.86-windows-x64\solrhome</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>
<!-- 把这个注释了
<security-constraint>
<web-resource-collection>
<web-resource-name>Disable TRACE</web-resource-name>
<url-pattern>/</url-pattern>
<http-method>TRACE</http-method>
</web-resource-collection>
<auth-constraint/>
</security-constraint>
<security-constraint>
<web-resource-collection>
<web-resource-name>Enable everything but TRACE</web-resource-name>
<url-pattern>/</url-pattern>
<http-method-omission>TRACE</http-method-omission>
</web-resource-collection>
</security-constraint>
-->
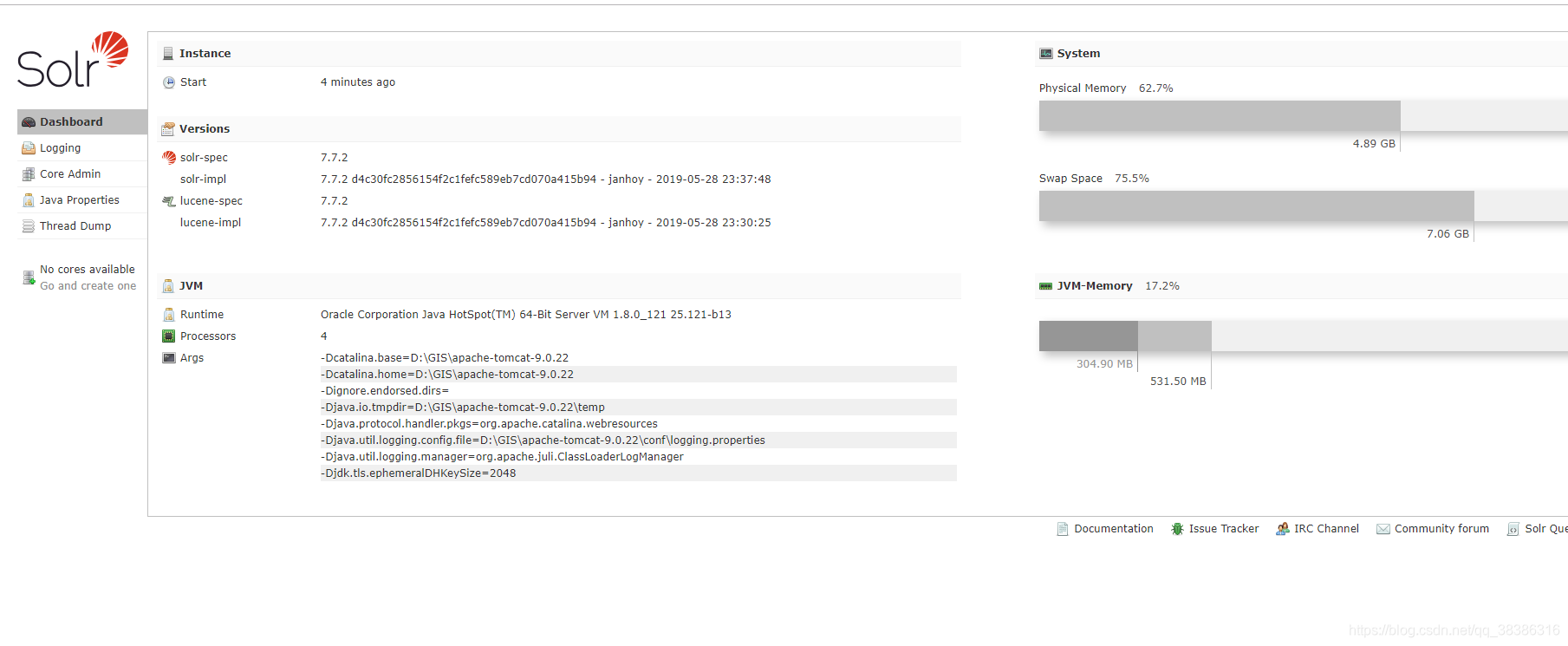
- 由于,在windows上, 所以直接点击
tomcat/bin/start.bat就启动tomcat服务了,然后再浏览器中输入http://localhost:8080/solr,就进入solr的管理页面。
- 相关问题:
- tomcat9.0启动时,控制台的中文信息显示乱码。
- 解决办法:在
tomcat/conf/loggin.properties,将java.util.logging.ConsoleHandler.encoding = UTF-8修改为
java.util.logging.ConsoleHandler.encoding = GBK - solr+tomcat配置完成后出现404问题,启动tomcat后找不到solr的资源。
- 解决办法: 检查版本问题:tomcat、jdk、solr之间版本问题;检查solr的依赖的jar包是否添加正确;检查web.xml中指定的solrhome的路径是否正确。
8. solr 中的schema.xml
- FieldType域的类型
- Field 定义
- uniqueKey 组键
- dynamicField 动态域
- copyField 复制域
9. solr中的中文分词器ik-analyzer 的配置
- 下载地址:https://search.maven.org/search?q=g:com.github.magese AND a:ik-analyzer&core=gav
- 在
solrhome/${collection}/conf/managed-schema文件 中添加如下配置:
<!-- IK分词 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory" useSmart="false"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory" useSmart="false"/>
</analyzer>
</fieldType>
<!-- 配置某个域使用,IK分词 -->
<field name="title_ik" type="text_ik" indexed="true" stored="false"/>
<field name="content_ik" type="text_ik" indexed="true" stored="false"/>
- 在
webapps\solr\WEB-INF\lib添加刚才下载的jar包 - 在
webapps\solr\WEB-INF创建文件夹classes,在其下面添加ik-analyzer 的配置文件如下:
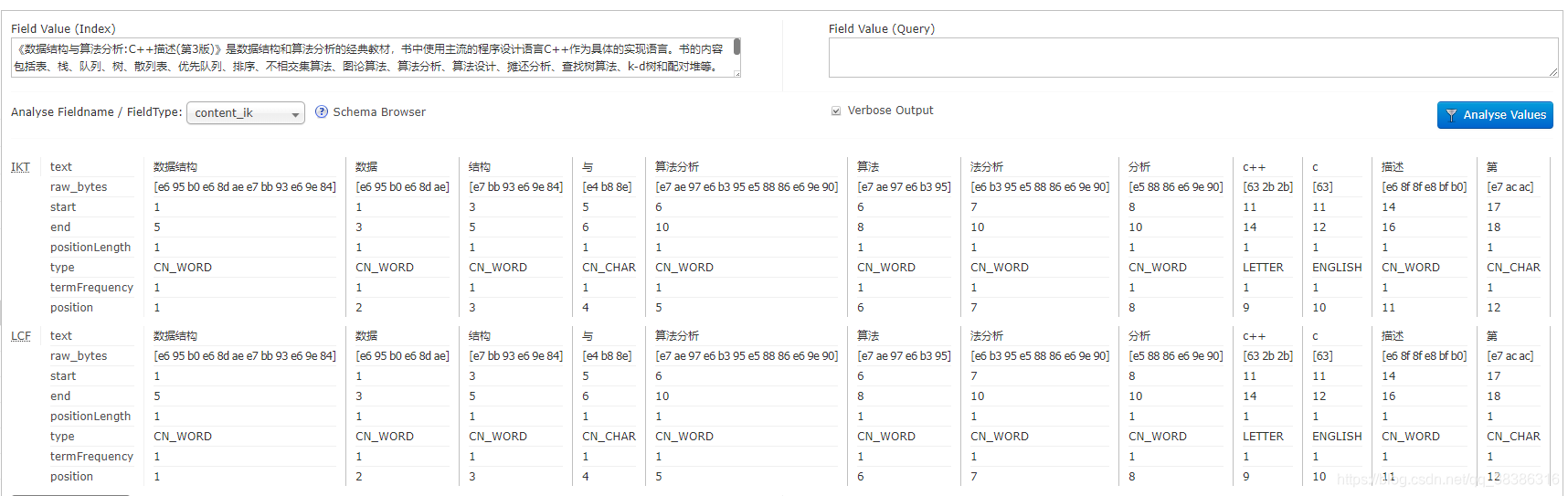
- 分词效果:
10.solr的后台管理页面的操作
- 添加
- 更新
- 删除
- 查询
11.solr的后台数据导入
- 我的mysql里的数据结构与内容:
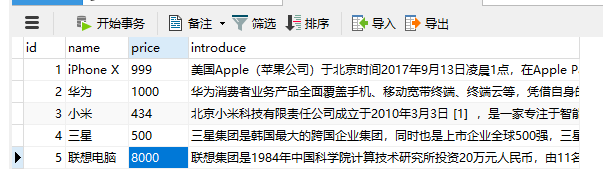
- 在
tomcat\webapps\solr\WEB-INF\lib添加依赖的jar包- mysql-connector-java-5.1.15-bin.jar
- solr-dataimporthandler-7.7.2.jar(
solr-7.7.2\dist) - solr-dataimporthandler-extras-7.7.2.jar (
solr-7.7.2\dist)
- 将
solr-7.7.2\example\example-DIH\solr\solr\conf\solr-data-config.xml移动到solr\solr\solrhome\new_core\conf`下并编辑
<dataConfig>
<dataSource type="JdbcDataSource"
driver="com.mysql.jdbc.Driver"
url="jdbc:mysql://172.21.3.210:3306/solr"
user="MHadoop"
password="12345678" />
<document>
<entity name="goods"
query="select id,name,price,introduce from goods">
<field column="id" name="id" />
<field column="name" name="name" />
<field column="price" name="price" />
<field column="introduce" name="introduce" />
</entity>
</document>
</dataConfig>
- 打开此目录的solrconfig.xml文件,在1000行左右添加如下内容:
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">solr-data-config.xml</str>
</lst>
</requestHandler>
- 在managed-schema文件中添加相应的域
<!-- 配置字段 -->
<field name="name" type="text_ik" indexed="true" stored="true" multiValued="false" />
<field name="price" type="pdouble" indexed="false" stored="true" multiValued="false" />
<field name="introduce" type="text_ik" indexed="true" stored="true" multiValued="false" />
- 然后再页面进行导入
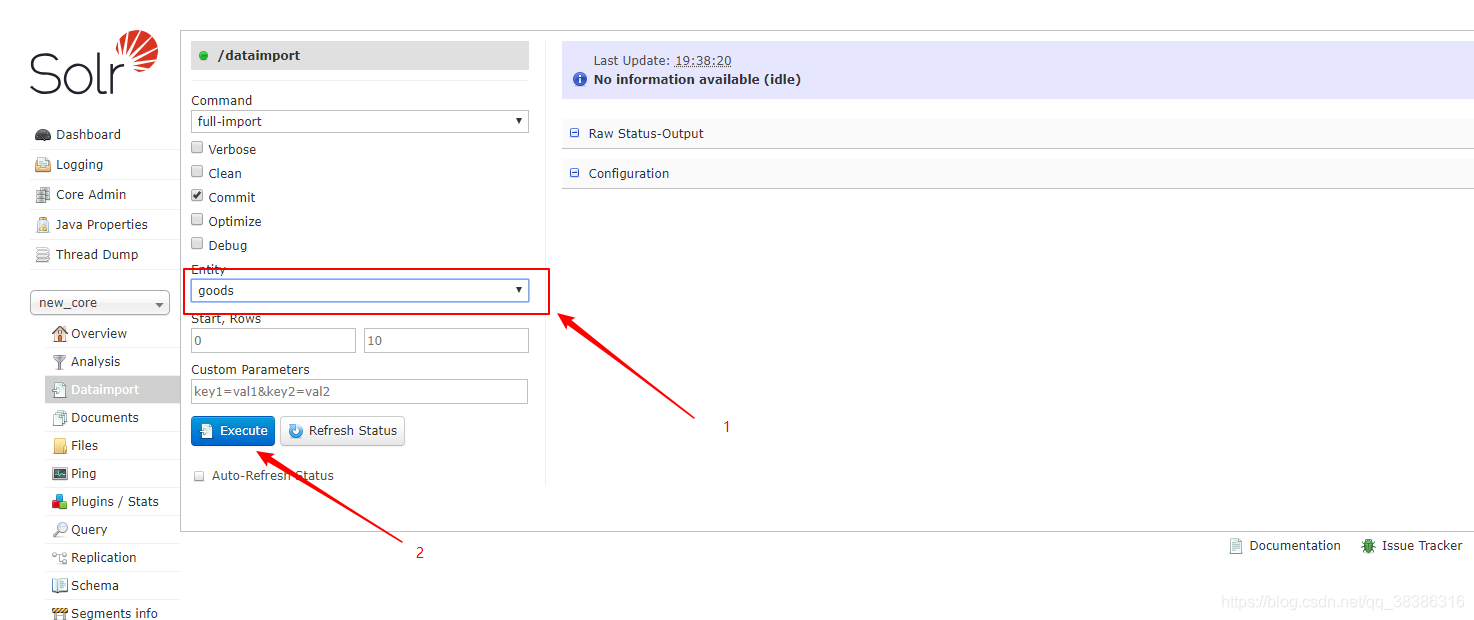
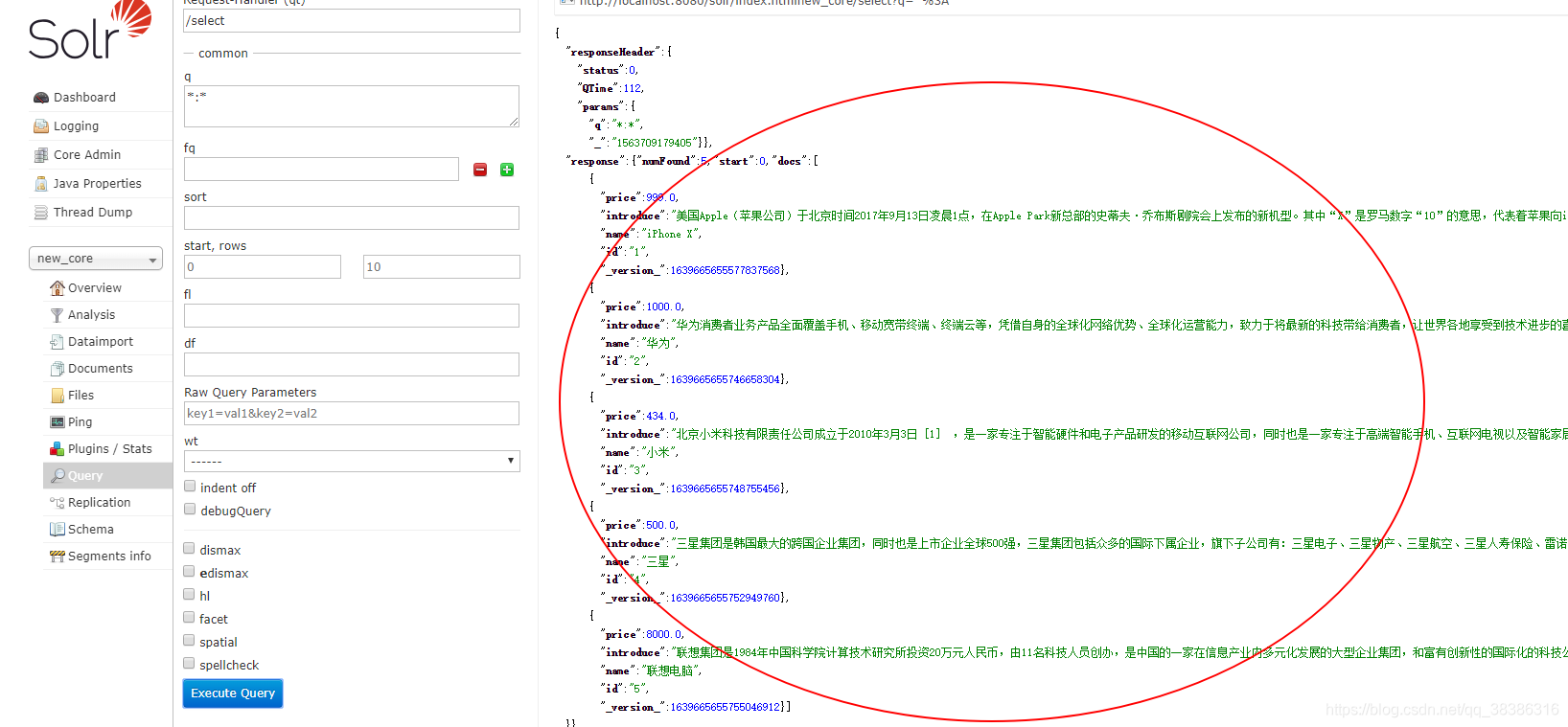
- 如果导入成功,则在下面查询页面查到。
12. solrJ 的增、删、改、查
- 添加jar包到工程中
- 将solr-7.7.2/dist/solrj-lib文件夹下的所有jar包复制到工程lib文件夹下
- 将solr-7.7.2/dist中solr-solrj-7.7.2.jar复制到工程lib文件夹下
- demo 如下:
- com.zcs.entity
package com.zcs.entity;
public class Goods {
private int id;
private String name;
private double price;
private String introduce;
//无参的构造方法
// getter setter
public int getId() {
return id;
}
public Goods() {
super();
}
public Goods(int id, String name, double price, String introduce) {
super();
this.id = id;
this.name = name;
this.price = price;
this.introduce = introduce;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
public String getIntroduce() {
return introduce;
}
public void setIntroduce(String introduce) {
this.introduce = introduce;
}
//重写的toString的方法
@Override
public String toString() {
return "Goods [id=" + id + ", name=" + name + ", price=" + price + ", introduce=" + introduce + "]";
}
}
- com.zcs.solrDao
package com.zcs.solrDao;
import static org.hamcrest.CoreMatchers.nullValue;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import javax.sound.sampled.LineListener;
import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.impl.HttpSolrClient;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.common.SolrDocument;
import org.apache.solr.common.SolrDocumentList;
import org.apache.solr.common.SolrInputDocument;
import com.zcs.entity.Goods;
public class GoodsSolrDao{
//添加或更新
public void insertOrUpdate(Goods goods) {
//创建solrClient同时指定超时时间
HttpSolrClient client = new HttpSolrClient.Builder("http://localhost:8080/solr/new_core").withConnectionTimeout(5000).build();
//创建文档
SolrInputDocument document = new SolrInputDocument();
document.addField("id", goods.getId());
document.addField("name", goods.getName());
document.addField("price", goods.getPrice());
document.addField("introduce", goods.getIntroduce());
//添加到client,并且添加commit
try {
client.add(document);
client.commit();
} catch (Exception e) {
e.printStackTrace();
}
}
//删除
public void delete(int id) {
//获取链接
HttpSolrClient client = new HttpSolrClient.Builder("http://localhost:8080/solr/new_core").withConnectionTimeout(5000).build();
try {
client.deleteById(String.valueOf(id));
client.commit();
client.close();
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
}
//根据关键字查询
public List<Goods> search(String keyword, boolean isHighLight) {
//创建solrClient同时指定超时时间
HttpSolrClient client = new HttpSolrClient.Builder("http://localhost:8080/solr/new_core").withConnectionTimeout(5000).build();
//创建solrquery
SolrQuery solrQuery = new SolrQuery();
//设置关键词
solrQuery.setQuery(keyword);
//过滤条件
// solrQuery.set("fq", "price:[0 TO *]");
//分页
// solrQuery.setStart(0);
// solrQuery.setRows(10);
//默认搜索字段
solrQuery.set("df", "name");
// 只查询指定域 相当于select id,name,price,introduce from goods.
solrQuery.set("fl", "id, name, price, introduce");
//打开高亮的开关
solrQuery.setHighlight(true);
//指定高亮域
solrQuery.addHighlightField("name");
// 关键词前缀
solrQuery.setHighlightSimplePre("<font color='red'>");
// 关键词后缀
solrQuery.setHighlightSimplePost("</font>");
//执行查询
QueryResponse response = null;
try {
response = client.query(solrQuery);
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
//普通结果集
SolrDocumentList docs = response.getResults();
// 获取高亮结果集
// 1.Map<String, Map<String, List<String>>>的key是id,
// value是查询到的数据
// 2.Map<String, List<String>>的key是字段名,value是值,
// 如果支持多值,它的值就是集合,不支持值就是该集合的第一个元素
Map<String, Map<String, List<String>>> highlighting = response.getHighlighting();
//总条数
long totalNum = docs.getNumFound();
System.out.println("totalNum: " + totalNum);
//普通查询对象
List<Goods> goods = new ArrayList<Goods>();
//高亮查询对象
List<Goods> highListGoods = new ArrayList<Goods>();
//遍历结果集
for(SolrDocument document : docs) {
Goods _good = new Goods();
Goods _highLightGood = new Goods();
//设置普通结果到_good中
_good.setId(Integer.valueOf((String)document.get("id")));
_good.setName((String)document.get("name"));
_good.setPrice((double)document.get("price"));
_good.setIntroduce((String)document.get("introduce"));
// 设置高亮结果到_highLightGood中
// 得到该条数据
Map<String, List<String>> map =
highlighting.get((String)document.get("id"));
// 设置各个字段 不支持多值的字段,
// 其值就是List<String>中的第一个值
// 如果被搜索的字段不包含搜索的关键字,则会被置为空,
// 所以需要判定是否为空,为空则使用普通结果
_highLightGood.setId(_good.getId());
String name = map.get("name").get(0);
_highLightGood.setName(name == null ? _good.getName() : name);
_highLightGood.setPrice(_good.getPrice());
_highLightGood.setIntroduce(_good.getIntroduce());
//将_good与_highLightGood分别添加到普通对象列表与高亮对象列表中
goods.add(_good);
highListGoods.add(_highLightGood);
}
if(isHighLight) {
return highListGoods;
}
return goods;
}
}
- com.zcs.TestSolrDao
package com.zcs.TestSolrDao;
import java.util.List;
import org.junit.Test;
import com.zcs.entity.Goods;
import com.zcs.solrDao.GoodsSolrDao;
public class TestGoodsSolrDao{
@Test
public void TestInsertOrUpdate() {
GoodsSolrDao goodsSolrDao = new GoodsSolrDao();
Goods goods = new Goods(6, "meizu", 2333, "公司以设计研发优雅、简单易用的智能设备和系统为依托,致力于打造开放共赢的移动互联网生态,为用户创造融合设计和技术的新价值,打磨「人、科技、自然和谐互动」的未");
goodsSolrDao.insertOrUpdate(goods);
}
@Test
public void Testdelete() {
GoodsSolrDao goodsSolrDao = new GoodsSolrDao();
goodsSolrDao.delete(6);
}
@Test
public void testSearch() {
GoodsSolrDao goodsSolrDao = new GoodsSolrDao();
List<Goods> goods = goodsSolrDao.search("小米", false);
System.out.println(goods);
}
}
FAQ

















 886
886

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









