






 本文深入解析反向传播算法的原理,通过实例演示计算流程,并提供Python代码实现。涵盖BP算法核心公式,助您理解神经网络训练过程。
本文深入解析反向传播算法的原理,通过实例演示计算流程,并提供Python代码实现。涵盖BP算法核心公式,助您理解神经网络训练过程。
摘要:给出反向传播算法的具体推导,并通过一个例子对反向传播的计算流程进行介绍。最后利用python从零实现一个神经网络。代码仅作为公式的理解,不具备重复使用能力。
目录
- BP算法原理
- 简单实例
- python从零实现
- 各资料中的BP算法公式
参考
【1】“Neural Networks and Deep Learning”. Michael A. Nielsen.
【2】“Pattern Classification”.
【3】“Neural Networks and Deep Learning”. 邱锡鹏.
1. BP算法原理
有关多层感知器、神经网络的具体内容在各参考文献中均有详细介绍。
对于前馈网络,前向传播接收输入数据xxx,计算输出y^\hat{y}y^。在训练时通过输出y^\hat{y}y^计算损失J(θ)J(\theta)J(θ)。反向传播算法通过计算J(θ)J(\theta)J(θ)的梯度,允许信息从输出层反向传输,如图1。下面开始介绍反向传播的具体过程,并通过一个例子加深理解。
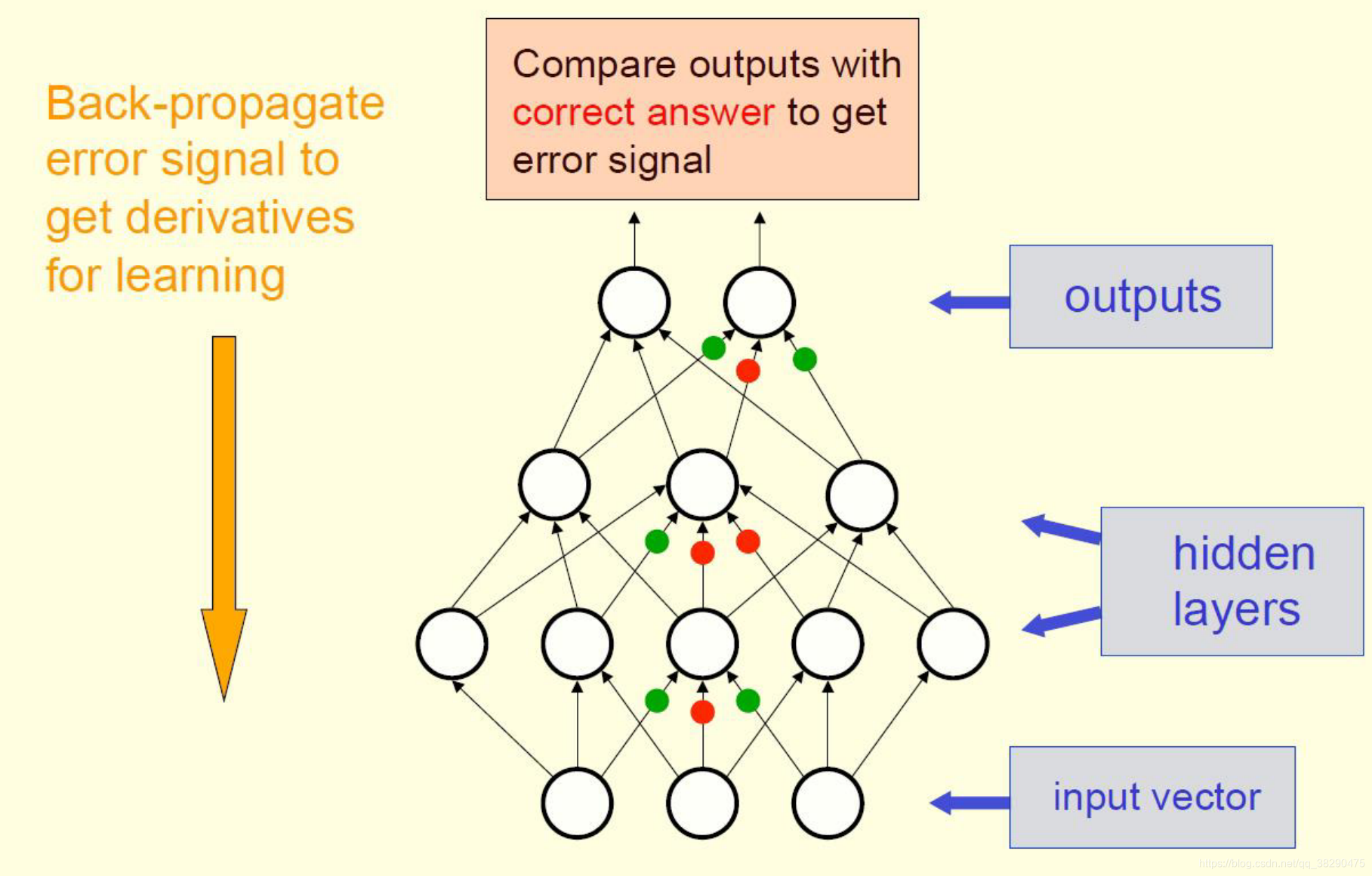
首先给出Hinton报告中的几点说明:
- 从输入数据,我们并不知道隐层单元时如何工作的;
- 但我们能知道当隐层激活改变时,损失减少的快慢程度(通过梯度);
- 每一个隐层单元能影响多个输出节点,并且对误差有不同的影响;
- 通过微分链式法则,损失函数每个权重的梯度很容易计算。
接下去就重点分析一下这个很容易计算的过程。
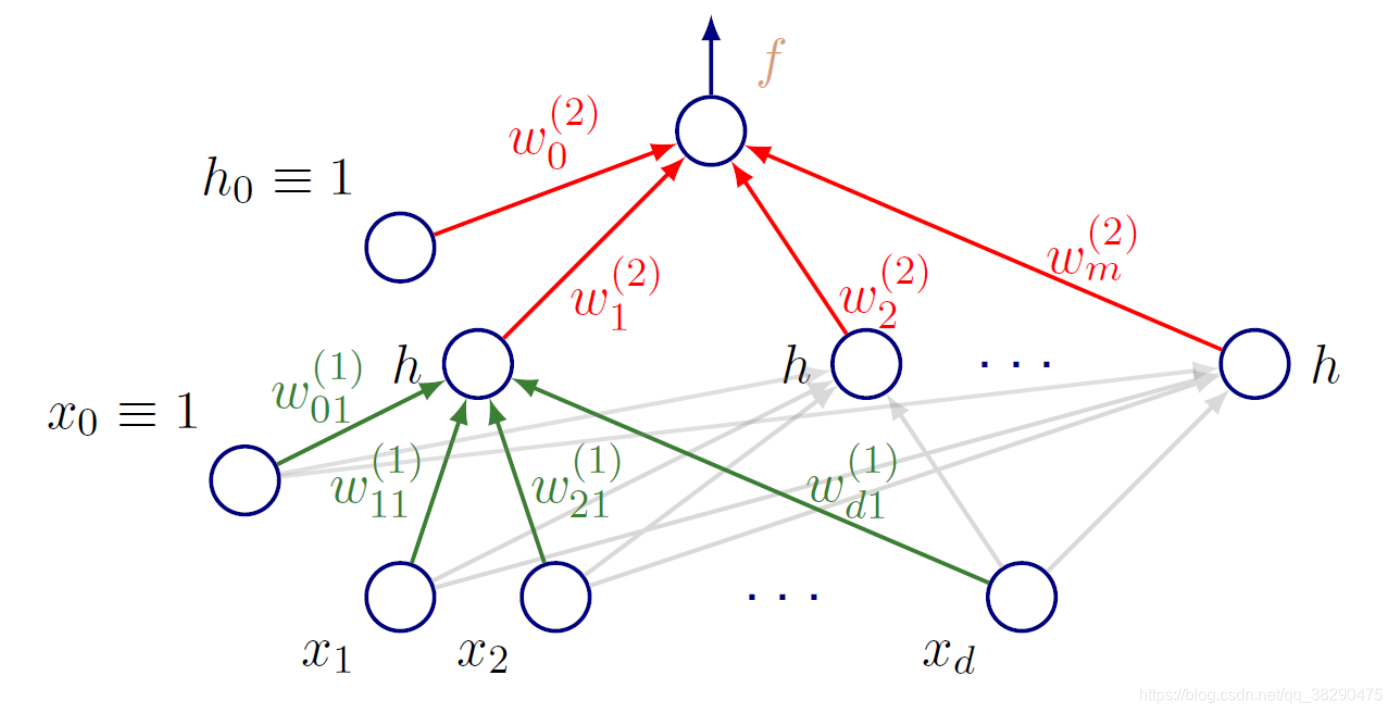
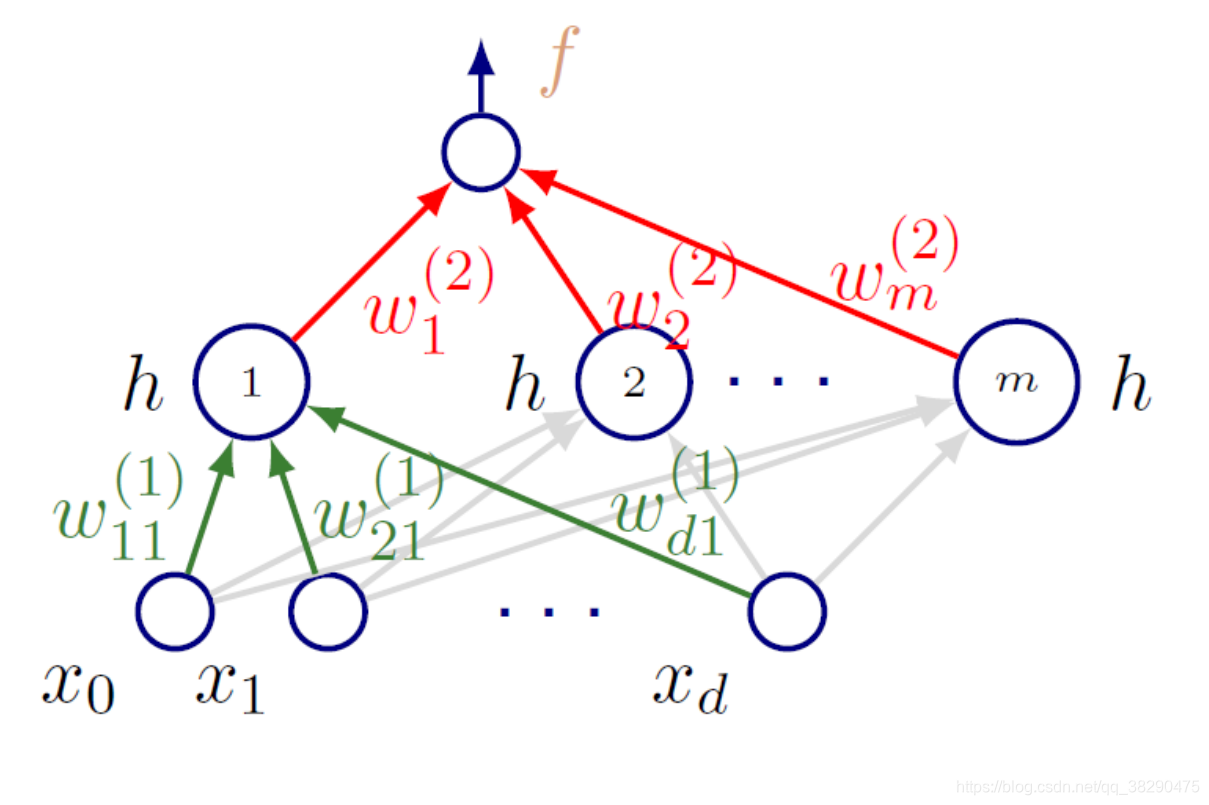
上图即一个常见的全连接网络结构,输入向量xxx有ddd个维度,单隐层有m个单元m个单元m个单元,单输出模型,并且包括下标为000的偏置项。
根据前向操作,从输入xxx到输出y^\hat{y}y^,我们有如下公式:
y^(x;w)=f(∑j=1mwj(2)h(∑i=1dwij(1)xi+w0j(1))+w0(2))\hat{y}(x;w)=f\left(\sum_{j=1}^mw^{(2)}_jh\left(\sum_{i=1}^dw^{(1)}_{ij}x_i+w_{0j}^{(1)}\right)+w_{0}^{(2)}\right)y^(x;w)=f(j=1∑mwj(2)h(i=1∑dwij(1)xi+w0j(1))+w0(2))
公式即简单的线性操作加非线性激活,再进行线性操作和非线性激活,就得到估计的输出。
网络的误差同样很容易得到:
L(X;w)=∑i=1M12(yi−y^(x;w))2L(X;w)=\sum_{i=1}^M\frac{1}{2}\left(y_i-\hat{y}(x;w)\right)^2L(X;w)=i=1∑M21(yi−y^(x;w))2
这里用的就是常见的平方损失。
通常,由于非线性激活的存在,最小化上述误差都是没有闭式解的,因此需要用到梯度下降等优化算法。并且对每个样本,我们都要计算其梯度。
这里给出一个简单的线性模型:y^=∑jwjxij\hat{y}=\sum_jw_jx_{ij}y^=∑jwjxij,作为例子,观察梯度的特点。梯度计算如下:
∂L(xi)∂wj=(y^i−y)xij\frac{\partial L(x_i)}{\partial w_{j}}=(\hat{y}_{i}-y)x_{ij}∂wj∂L(xi)=(y^i−y)xij
即,梯度为误差乘输入。
对于如下图所示的多层神经网络的特定单元,其有sss个输入单元,我们分析它所连的第ttt个输出单元。
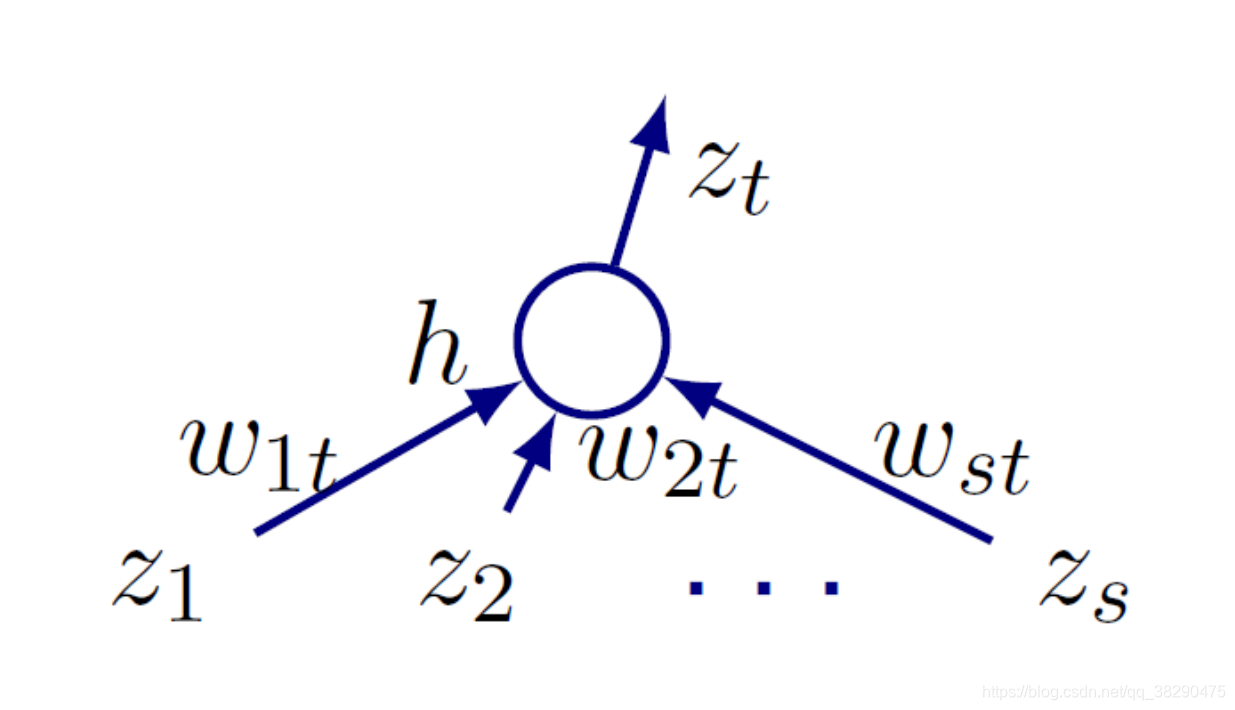
其输出ztz_tzt可以表示为
zt=h(∑jwjtzj)z_t=h\left(\sum_jw_{jt}z_j\right)zt=h(j∑wjtzj)
其中,记住我们的jjj是上一层的神经元号,ttt是当前层的神经元号。令线性组合∑jwjtzj=at\sum_jw_{jt}z_j=a_t∑jwjtzj=at,则zt=h(at)z_t=h(a_t)zt=h(at),ztz_tzt为激活值,ata_tat为线性组合值。
因此可以发现损失函数LLL对wjtw_{jt}wjt的依赖性全部都在ata_tat中,如下所示:
∂L∂wjt=∂L∂at∂at∂wjt=∂L∂atzj\frac{\partial L}{\partial w_{jt}}=\frac{\partial L}{\partial a_{t}}\frac{\partial a_t}{\partial w_{jt}}=\frac{\partial L}{\partial a_{t}}z_j∂wjt∂L=∂at∂L∂wjt∂at=∂at∂Lzj
类比前面线性模型的例子,zjz_jzj就是上一层第jjj个输出即当前层的第jjj个输入。
然后定义
∂L∂at=δt\frac{\partial L}{\partial a_{t}}=\delta_t∂at∂L=δt
δt\delta_tδt可以理解为误差对神经元ttt的敏感程度,反向传播过程就是该敏感程度沿着网络反向传播的过程。
对于当前神经元ttt,我们已经分析了它的输入,接下去分析它的输出。
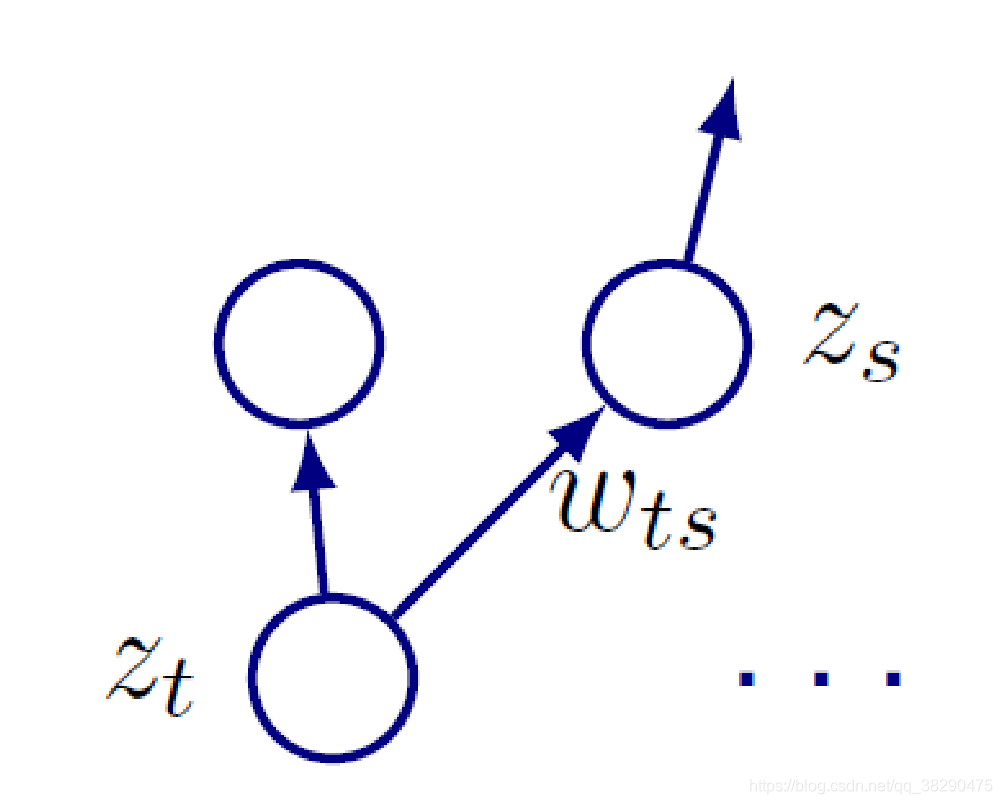
如图所示,神经元ttt会对其下一层的多个单元传递输入,令所有接收ttt输入的神经元所处的集合为SSS,可以得到下式:
as=∑j:j→s∈Swjsh(aj)a_s=\sum_{j:j\rightarrow s\in S}w_{js}h(a_j)as=j:j→s∈S∑wjsh(aj)
即,对于所属集合SSS的神经元sss,其输入为上一层所有指向它的神经元输出之和。
因此当j=tj=tj=t时,ata_tat就和asa_sas发生关系,而asa_sas更加接近输出,因而对LLL的影响更靠前,如下式:
δt=∑s∈S∂L∂as∂as∂at=∑s∈S∂L∂aswtsh′(at)=h′(at)∑s∈Swtsδs\begin{aligned} \delta_t&=\sum_{s\in S}\frac{\partial L}{\partial a_{s}}\frac{\partial a_s}{\partial a_{t}}\\ &=\sum_{s\in S}\frac{\partial L}{\partial a_{s}}w_{ts}h'(a_t)\\ &=h'(a_t)\sum_{s\in S}w_{ts}\delta_s \end{aligned}δt=s∈S∑∂as∂L∂at∂as=s∈S∑∂as∂Lwtsh′(at)=h′(at)s∈S∑wtsδs
到此,我们就将当前层的δt\delta_tδt和下一层的δs\delta_sδs联系在一起。
目前只是反向传播的过程,那在网络中反向传播具体是怎么表现的呢?又怎么和权值更新结合在一起呢?这两个问题将通过一个具体的例子进行解答。
2. 简单实例
简单算例,网络结构如上图,并假设:
- 输出:y^=f(a)=a\hat{y}=f(a)=ay^=f(a)=a
- 隐层激活函数:h(a)=tanh(a)h(a)=\tanh(a)h(a)=tanh(a),因此h′(a)=1−h(a)2h'(a)=1-h(a)^2h′(a)=1−h(a)2
反向传播求解开始!
对于一个输入样本xxx,首先是前向传播过程:
- 隐层输入:aj=∑i=0dwij(1)xia_j=\sum_{i=0}^dw^{(1)}_{ij}x_iaj=∑i=0dwij(1)xi
- 隐层输出:zj=tanh(aj)z_j=\tanh(a_j)zj=tanh(aj)
- 网络输出:y^=a=∑j=0mwj(2)zj\hat{y}=a=\sum_{j=0}^mw^{(2)}_jz_jy^=a=∑j=0mwj(2)zj
因此对每一个样本的误差为:
L=12(y−y^)2L=\frac{1}{2}\left(y-\hat{y}\right)^2L=21(y−y^)2
对于输出单元,直接计算其δ\deltaδ:
δ=∂L∂a=y−a=y−y^\delta=\frac{\partial L}{\partial a}=y-a=y-\hat{y}δ=∂a∂L=y−a=y−y^
然后计算隐层单元的δ\deltaδ:
δj=h′(aj)wj(2)δ=(1−zj)2wj(2)δ\delta_j=h'(a_j)w^{(2)}_j\delta=(1-z_j)^2w^{(2)}_j\deltaδj=h′(aj)wj(2)δ=(1−zj)2wj(2)δ
就是上面的传播公式,这里的集合SSS只有一个输出神经元。
下面就可以直接写出梯度:
∂L∂wij(1)=δjxi∂L∂wj(2)=δzj\begin{aligned} &\frac{\partial L}{\partial w^{(1)}_{ij}}=\delta_jx_i\\ &\frac{\partial L}{\partial w^{(2)}_{j}}=\delta z_j \end{aligned}∂wij(1)∂L=δjxi∂wj(2)∂L=δzj
带入梯度下降法的权值更新公式:
wij(1):=wij(1)−ηδjxiwj(2):=wj(2)−ηδzj\begin{aligned} &w^{(1)}_{ij}:=w^{(1)}_{ij}-\eta\delta_jx_i\\ &w^{(2)}_{j}:=w^{(2)}_{j}-\eta\delta z_j \end{aligned}wij(1):=wij(1)−ηδjxiwj(2):=wj(2)−ηδzj
通过上面的例子,大家都能自己编程推导反向传播算法了嘛,哪里有疑问或者没说清楚的欢迎评论~~
下面就按照上述例子直观的编写反向传播算法。
3. python从零实现BP网络
【1】中有比较详细的DNN从零搭建过程,这里没有按照那么复杂的方式来些,纯粹是为了配合公式,使代码和公式更好理解。
首先准备数据集,人工生成一个回归任务的数据。
import numpy as np
import matplotlib.pyplot as plt
num_train, num_test = 100, 100
num_features = 10
true_w, true_b = np.ones((num_features, 1)) * 5, 2
features = np.random.normal(0, 1, (num_train + num_test, num_features))
noises = np.random.normal(0, 1, (num_train + num_test, 1)) * 0.0
labels = np.dot(features, true_w) + true_b + noises
x_train, x_test = features[:num_train, :], features[num_train:, :]
y_train, y_test = labels[:num_train], labels[num_train:]
再选择模型,进行训练。代码比较简单,结合注释以及第二节的公式阅读。基本和公式是一样的。
# 选择模型类型
def sigmoid(x):
return 1.0 / (1.0 + np.exp(-x))
def sigmoid_prime(x):
return sigmoid(x) * (1 - sigmoid(x))
class Network(object):
def __init__(self, sizes):
self.num_layers = len(sizes)
self.sizes = sizes
self.biases = [np.random.randn(y) for y in self.sizes[1:]]
self.weights = [np.random.randn(x, y) / np.sqrt(x)
for (x, y) in zip(self.sizes[:-1], self.sizes[1:])]
self.delta = []
def feedforward(self, activation):
# 公式前向传播
a_hidden = np.dot(activation, self.weights[0]) + self.biases[0]
z = sigmoid(a_hidden)
a_out = np.dot(z, self.weights[1]) + self.biases[1]
y_hat = a_out
return y_hat
def backpropagation(self, x, y):
# -----------------------------前向传播开始-----------------------------------
# 依次计算隐层输入,隐层输出,网络输出
a_hidden = np.dot(x, self.weights[0]) + self.biases[0]
z = sigmoid(a_hidden)
a_out = np.dot(z, self.weights[1]) + self.biases[1]
y_hat = a_out
assert y_hat.all() == self.feedforward(x).all()
# -----------------------------前向传播完成-----------------------------------
# -----------------------------反向传播开始-----------------------------------
# 依次计算误差,输出单元delta和隐层delta
L = (y_hat - y) ** 2 / 2
delta_output = (y_hat - y)
delta_hidden = sigmoid_prime(a_hidden).reshape((-1,1)) * (self.weights[1] * delta_output)
# -----------------------------反向传播结束-----------------------------------
# -----------------------------权重更新开始-----------------------------------
# 更新输入-隐层的权重
delta1 = np.zeros_like(self.weights[0])
for j in range(self.weights[0].shape[1]):
for i in range(self.weights[0].shape[0]):
delta1[i, j] = delta_hidden[j] * x[i]
# print(delta1[i, j])
self.weights[0][i, j] -= 1 * delta1[i, j]
self.biases[0][j] -= 1 * delta_hidden[j]
# 更新隐层-输出的权重
delta2 = np.zeros_like(self.weights[1])
for j in range(self.weights[1].shape[1]):
for i in range(self.weights[1].shape[0]):
delta2[i, j] = delta_output[j] * z[i]
self.weights[1][i, j] -= 0.001 * delta2[i, j]
self.biases[1][j] -= 0.001 * delta_output[j]
def myloss(y_hat, y):
return (y_hat - y) ** 2
net = Network([10, 20, 1])
all_loss = []
for epoch in range(100):
loss = 0
for isample in range(x_train.shape[0]):
loss += myloss(net.feedforward(x_train[isample]), y_train[isample])
all_loss.append(loss)
for isample in range(x_train.shape[0]):
net.backpropagation(x_train[isample], y_train[isample])
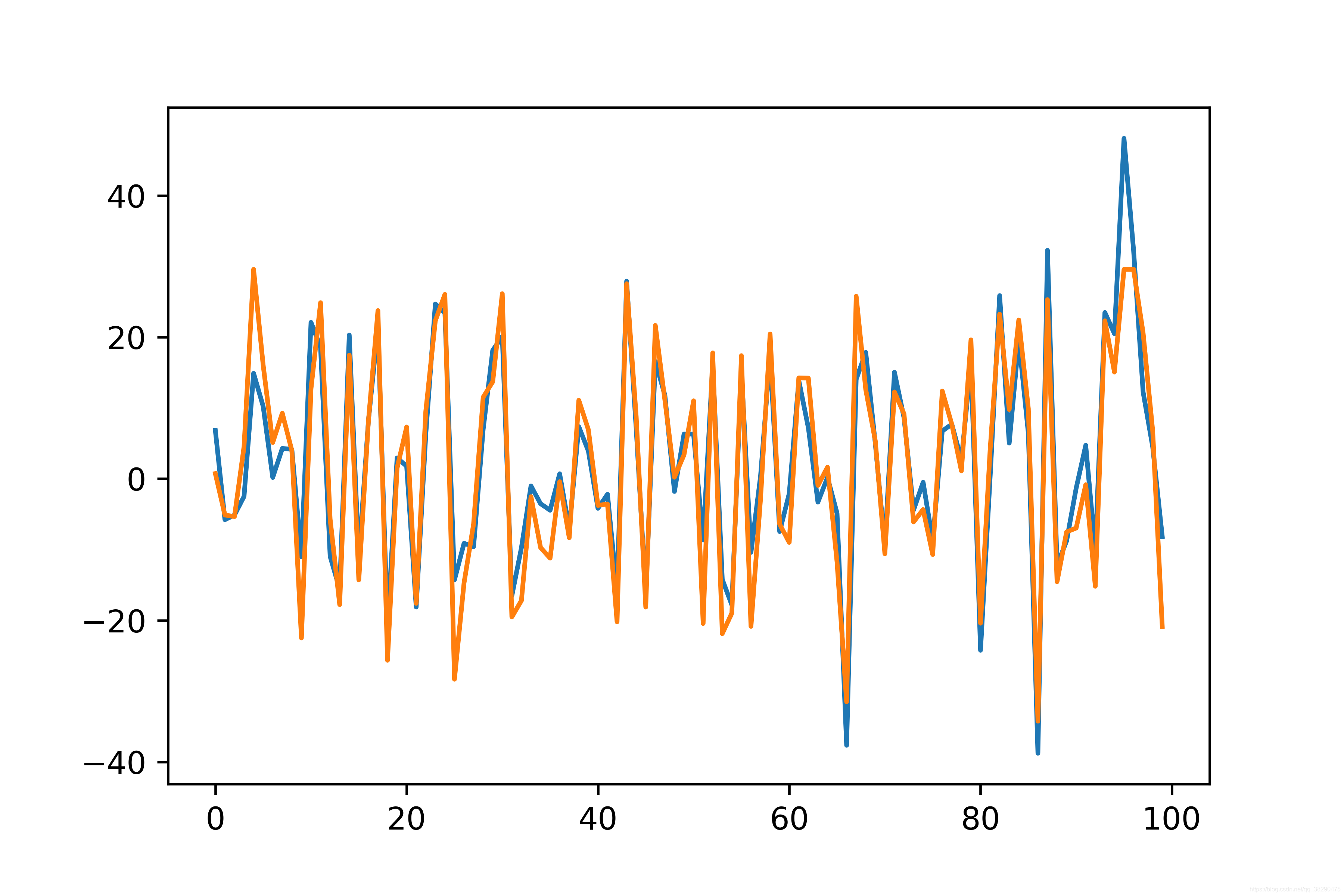
plt.plot(range(100), all_loss)
观察一下测试结果,基本拟合在一起了。表明上述推导以及比较低级的代码是有效的。
4. 总结BP算法公式
各资料的推导过程大同小异,很多都只有符号上的区别。
本文仅针对单个神经元进行推导,最终得到的几个公式如下,aaa为线性组合,zzz为激活值。
- δ\deltaδ法则:其中ttt为当前层的某个神经元,sss为下一层的某个神经元。
δt=h′(at)∑s∈Swtsδs\delta_t=h'(a_t)\sum_{s\in S}w_{ts}\delta_sδt=h′(at)s∈S∑wtsδs
- 权重更新:其中ttt为当前层的某个神经元,jjj为输入层的某个神经元。
∂L∂wjt=∂L∂at∂at∂wjt=∂L∂atzj=δtzj\frac{\partial L}{\partial w_{jt}}=\frac{\partial L}{\partial a_{t}}\frac{\partial a_t}{\partial w_{jt}}=\frac{\partial L}{\partial a_{t}}z_j=\delta_tz_j∂wjt∂L=∂at∂L∂wjt∂at=∂at∂Lzj=δtzj
后来发现这样的推导和《模式分类》【2】中的推导基本相同。
邱锡鹏老师的《神经网络与深度学习》【3】中对某层的神经元进行推导,最终得到的公式如下,aaa为激活值。
- δ\deltaδ法则:
δ(l)=fl′(z(l))∘((w(l+1))Tδ(l+1))\delta^{(l)}=f_l^{'}(z^{(l)})\circ(\left(w^{(l+1)})^T\delta^{(l+1)}\right)δ(l)=fl′(z(l))∘((w(l+1))Tδ(l+1))
- 权重更新:
∂L∂Wl=δ(l)(a(l−1))T\frac{\partial L}{\partial W^{l}}=\delta^{(l)}\left(a^{(l-1)}\right)^T∂Wl∂L=δ(l)(a(l−1))T
统一符号,并矩阵化以后,两者是完全相同的。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









