



本次课程设计中,采用传统的数字图像处理方法(边缘检测,透射变换,霍夫变换等)对视频中的电车轨道进行检测和标注,并标注轨道所处的ROI区域,基于此ROI区域使用当下较为流行的YOLOv5目标检测深度学习算法进行区域内的障碍物识别与检测并将其标注。算法最终效果较好,可准确的检测两种环境(白天和夜晚)下的电车轨道并对轨道附近障碍物进行识别。算法识别效率为17FPS,效果较好。
课程设计介绍
本次课程设计主要任务为完成有轨电车轨道与轨道上障碍物的检测。所给资料为6段长度为3分钟的有轨电车记录仪的录像,如图所示:
有轨电车记录仪固定在电车的固定位置,需要对其面前的两条轨道线进行提取,并对轨道线以及轨道先附近的障碍物进行检测,以方便轨道交通的后续运行。图像中的无关项以及干扰项较多,且提供的视频存在白天以及黑夜的两个场景片段,轨道存在直线和弯道两种形式。
课程设计要求
本次课程设计的具体要求如下:
- 自行对所提供的部分视频数据进行标注以用于模型的训练和测试,从而对视频中的轨道进行提取和轨道上障碍物检测;
- 设计相应的处理算法提取并检测有轨电车的轨道位置并通过恰当的方式进行有轨电车轨道位置的可视化展示;
- 在上述检测轨道算法的基础上设计相应的算法检测轨道上的障碍物并且加以区分,比如行人,车辆等;
- 选择1-2个视频中的截取相应的片段,将算法应用上去,将检测结果在视频上进行标注并提交。
相关算法介绍
本次课程设计需要用到的相关算法有Canny边缘检测算法,透视变换,霍夫变换的曲线拟合以及yolov5目标检测算法,以下分别介绍相关算法。
Canny边缘检测
Canny边缘检测算法是比较出色边缘检测的算法,使用双阈值处理大大降低了边缘分割错误的概率,它包含以下四个步骤:

 透视变换
透视变换
透视变换(Perspective Transformation)是指利用透视中心、像点、目标点三点共线的条件,按透视旋转定律使承影面(透视面)绕迹线(透视轴)旋转某一角度,破坏原有的投影光线束,仍能保持承影面上投影几何图形不变的变换。简而言之,就是将一个平面通过一个投影矩阵投影到指定平面上。
 霍夫变换
霍夫变换
霍夫(Hough)变换是一个非常重要的检测间断点边界形状的方法。它通过将图像坐标空间变换到参数空间,来实现直线和曲线的拟合。对于普通的霍夫变换检测图像中直线来说,其算法的主要流程如下:

这里是对直线进行拟合,同样的可以使用多项式对于曲线进行拟合,求解多项式参数,进而得到曲线方程。
YOLOv5目标检测
YOLOv5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路,使其速度与精度都得到了极大的性能提升。主要的改进思路如下所示:
- 输入端:在模型训练阶段,提出了一些改进思路,主要包括Mosaic数据增强、自适应锚框计算、自适应图片缩放;
- 基准网络:融合其它检测算法中的一些新思路,主要包括:Focus结构与CSP结构;
- Neck网络:目标检测网络在BackBone与最后的Head输出层之间往往会插入一些层,Yolov5中添加了FPN+PAN结构;
- Head输出层:输出层的锚框机制与YOLOv4相同,主要改进的是训练时的损失函数GIOU_Loss,以及预测框筛选的DIOU_nms。
YOLOv5的网络架构如图所示
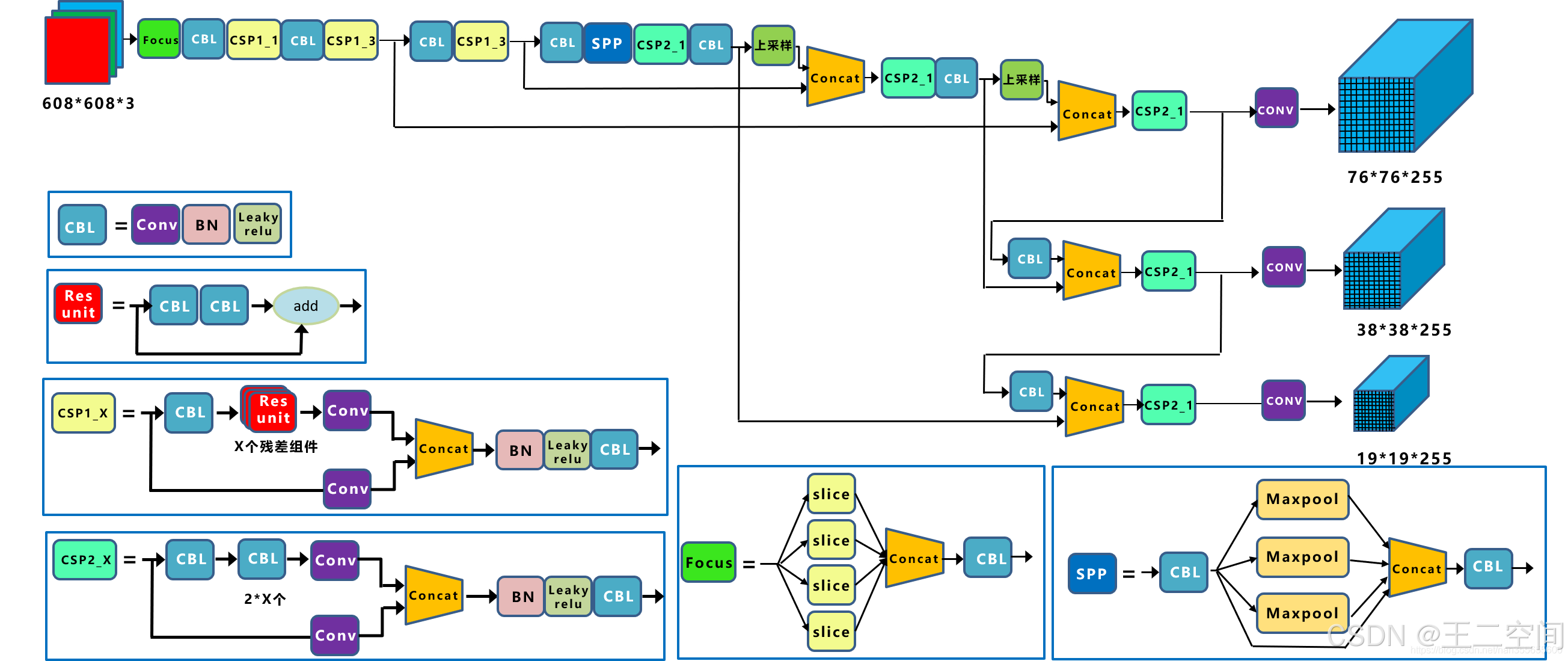
- 输入端-输入端表示输入的图片。该网络的输入图像大小为608*608,该阶段通常包含一个图像预处理阶段,即将输入图像缩放到网络的输入大小,并进行归一化等操作。在网络训练阶段,YOLOv5使用Mosaic数据增强操作提升模型的训练速度和网络的精度;并提出了一种自适应锚框计算与自适应图片缩放方法。
- 基准网络-基准网络通常是一些性能优异的分类器种的网络,该模块用来提取一些通用的特征表示。YOLOv5中不仅使用了CSPDarknet53结构,而且使用了Focus结构作为基准网络。
- Neck网络-Neck网络通常位于基准网络和头网络的中间位置,利用它可以进一步提升特征的多样性及鲁棒性。虽然YOLOv5同样用到了SPP模块、FPN+PAN模块,但是实现的细节有些不同。
- Head输出端-Head用来完成目标检测结果的输出。针对不同的检测算法,输出端的分支个数不尽相同,通常包含一个分类分支和一个回归分支。YOLOv4利用GIOU_Loss来代替Smooth L1 Loss函数,从而进一步提升算法的检测精度。
算法设计及实验结果展示
本次实验采用传统数字图像处理方法对视频中的轨道进行检测与标注,然后使用YOLOv5的预训练模型已检测的轨道区域进行障碍物检测与标注。算法的主要流程以及其中涉及的部分参数设定如下所述:
边缘检测
首先,将视频按帧读取,将每一帧保存为图像。如图所示:

对图像使用Canny边缘检测算法来检测图像的边缘。由于考虑图像中轨道部分并不明显且图像噪声较少,故不使用高斯算子对图像进行平滑处理以保持轨道边缘。Canny边缘检测的上下阈值设定为(25,80);检测后效果如图所示:

由上图可得,图像中不需要的额外信息过多,需要将其剔除。由于视频数据是由固定在电车上的摄像头获取,因此摄像头安装在固定的区域,可以选取感兴趣的ROI区域进行操作,且只要在一张图片上校准之后,就可以适用于这一个列车所对应的所有的铁轨检测。选取的轨道ROI区域如图中绿色部分所示:

对ROI区域进行Canny边缘检测得到图所示效果:

可以观察到,图像中检测出来得边缘主要为铁轨部分。紧接着,对图(7)进行3次三次闭运算(kernel=5)来连接边缘中得断线,修复图像边缘。修复后图像如图所示:

霍夫变换
边缘检测完成后,对图(8)得图像使用透视变换转换为鸟瞰图,然后使用霍夫变换拟合进行三次多项式拟合轨道曲线,透视变换后结果如图所示:

拟合完曲线后再将曲线进行上一步中相反方向的透视变换(即变换矩阵为上一步的逆矩阵),然后便可得到在原图中的曲线方程,在原图中对曲线方程用绿色线条进行标注即可得到轨道线的位置,标注后图像如图所示:

到此铁路轨道线的检测与标注工作已经完成,接下来进行轨道附近的障碍物检测工作。
YOLOv5障碍物检测
在得到上图中所述的轨道线过后,我们采用与图(6)相同的ROI区域进行障碍物的检测。实验中采用YOLOv5的预训练模型(yolov5s.pt)进行目标检测,而YOLOv5一般用于整幅图像的目标检测,直接检测效果如下图所示:

因此使用ROI区域制作掩膜,使得yolov5只对ROI区域内的目标进行检测,检测结果如图所示:

至此,所有针对图像每帧的检测工作已经完成,然后对每帧的图像进行合成视频,得到最终结果。统计可得每帧图片的轨道检测耗时50.2ms,yolov5目标检测耗时9.4ms,总效率为17FPS。
收获与展望
收获
直接对图像进行霍夫直线检测的效果并不一定好,转换为鸟瞰图之后在进行检测,效果会好很多;
可以通过设定ROI区域去除无效信息,进而获取纯净的只包含有效信息的图像;
对yolov5的使用可以灵活多变,使用掩膜使其只检测感兴趣区域。
展望
可以用上一帧图像检测到的轨迹对这一帧的轨迹进行矫正和优化。这里我也做实验测试了,发现效果并不好,因为一旦有一帧检测错误的现象发生,后续帧的检测很大概率全部出现问题,即影响太大;
在数据量充足且轨道训练数据标注完成的情况下,使用YOLOv5预训练模型进行微调训练后直接对轨道线进行实例分割和目标检测;
在GPU算力充足的条件下,使用更大的YOLOv5预训练模型进行障碍物的检测与识别,效果更好。


















 1432
1432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









