




 本文深入解析了进程作为现代分时系统工作单元的概念,探讨了进程的结构、状态、调度及上下文切换。同时,详细介绍了进程间的通信机制,包括共享内存和消息传递,以及同步策略。
本文深入解析了进程作为现代分时系统工作单元的概念,探讨了进程的结构、状态、调度及上下文切换。同时,详细介绍了进程间的通信机制,包括共享内存和消息传递,以及同步策略。
早期的计算机系统只允许一次执行一个程序。
进程是现代分时系统的工作单元
系统由一组进程组成:操作系统执行系统代码而用户进程执行用户代码
通过CPU多路复用,所有的这些进程可以并发的执行
通过在进程之间的切换,操作系统能使计算机更为高效
进程概念
- 进程是郑重的程序,这是一种非正式的说法。
- 进程不只是程序代码,程序代码有时称为文本段
- 进程通常还包括进程堆栈段和数据段
- 进程还可能包括堆,是在进程运行期间动态分配的内存
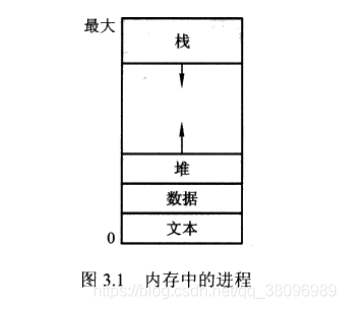
- 程序本身不是进程,程序只是被动实体。当一个可执行文件被装入内存时,一个程序才能成为进程
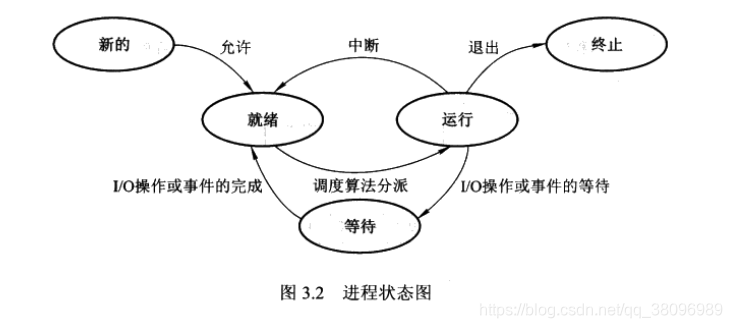
进程状态
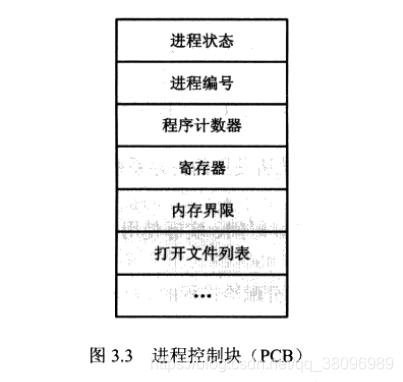
进程控制块
- 每个进程在操作系统内用进程控制块(PCB,Process Control Block)来表示
- PCB是用来存储进程信息的
- 进程状态:上面讲过
- 程序计数器:表示进程要执行的下一个指令的地址
- CPU寄存器:中断是保存,用以恢复进程
- CPU调度信息:这类信息包括进程优先级,调度队列的指针和其他调度参数
- 内存管理信息:基址和界限寄存器的值,页表或段表
- 记账信息:CPU时间,实际使用时间,时间界限,记账数据,作业或进程数量
- I/O状态信息:分配给进程的I/O设备列表,打开的文件列表等
进程调度
多道程序设计的目的是无论何时都有进程在运行,从而使CPU利用率达到最大化
单处理器系统,从来不会有超过一个进程在运行
- 调度队列
- 通常对于批处理系统,进程更多的是被提交,而不是马上执行。这些进程被方法到用量存储设备的缓冲池中,保存在那里,以便以后执行
- 长期调度程序或作业调度程序从该池中选择进程,并装入内存以准备执行
- 短期调度程序或CPU调度程序从准备执行的进程中选择进程,并为之分配CPU
- 两个调度程序的主要差别是他们执行的频率。
- 短期调度程序必须频繁的为CPU选择新进程,通常每100ms至少执行一次,调度程序必须要快,否则,如果花了10ms的时间来调度,那么就是10/(100+10)的CPU时间被用来调度
- 长期调度程序必须仔细选择。绝大多数进程可分为I/O为主或CPU为主,如果进程均是I/O为主的,那么就绪队列几乎为空,从而短期调度程序没有什么事情可做。如果都是CPU为主的,那么I/O等待队列几乎总为空,从而几乎不使用设备。因而系统会不平衡
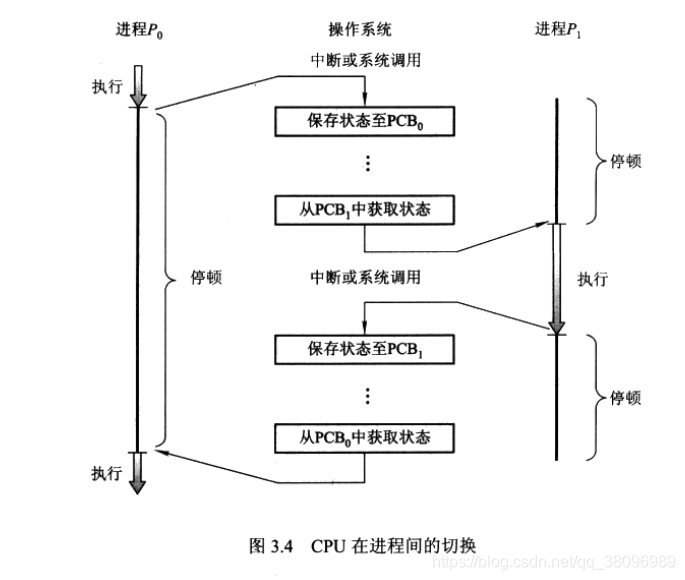
- 上下文切换
- 当系统发生一个中断时,系统需要保存当前运行在CPU中进程的上下文,从而在其处理完后,能恢复上下文
- 进程上下文,用PCB表示。当发生上下文切换时,内核会将旧进程的状态保存在其PCB中
进程操作
- 通常,进程需要一定的资源来完成其任务
- 在一个进程创建子进程时,子进程可能从操作系统哪里直接获得资源,也可能只从其父进程那里获得资源
- 限制子进程只能使用父进程的资源,能防止创建过多的进程带来的系统超载
- 当进程创建新进程时,有两种执行可能:
- 1.父进程与子进程并发执行
- 2.父进程等待,直到某个或全部子进程执行完
- 新进程的地址空间也有两种可能
- 1.子进程是父进程的复制品
- 2.子进程装入另一个新程序
- 进程终止
- 当进程完成执行最后的语句并使用系统调用exit()请求操作系统删除自身时,进程终止
- 这时进程返回状态值到父进程,所有进程资源会被操作系统释放
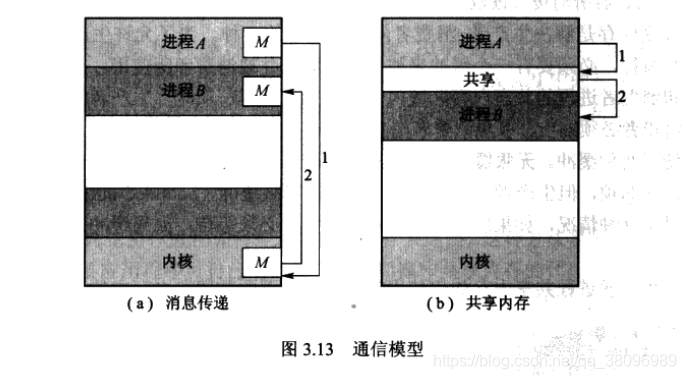
进程间通信
- 共享内存
- 允许以最快的速度进程方便的通信,可以达到内存的速度,比消息传递快。
- 仅在建立共享内存区时需要系统调用,一旦建立了共享内存,所有的访问都被处理为常规的内存访问,不需要来自内核的帮助
- 消息传递
- 比上者更容易实现,对于交换少量数据很有用,因为不需要避免冲突
- 消息传递系统通常用系统调用来实现,因而需要更多的内核介入的时间消耗
共享内存系统
- 一块共享内存区域驻留在生成共享内存段进程的地址空间,其他希望使用这个共享内存段进行通信的进程,必须将此放到他们自己的地址空间上
- 通常操作系统试图阻止一个进程访问另一个进程内存。
- 共享内存需要两个或更多的进程取消这个限制
- 他们通过在共享内存中读或写来完成信息交换
- 采用共享内存,是解决消费者生产者问题方法的一种:
- 可以使用两种缓冲,无限缓冲,对缓冲的大小没有限制。消费者可能会因为缓存为空而不得不等待,但生产者总是可以生产新项
- 有限缓冲,如果缓冲为空,消费者必须等待,如果为满,生产者必须等待
消息传递系统
-
直接通信
-
一个线路只与两个进程相关
-
每对进程之间只有一个线路
-
对称寻址
-
每个进程必须明确的命名通信的接受者或发送者,定义如下:
-
send(P,message):发送消息到进程P
-
receive(Q,message):接收来自进程Q的消息
-
非对称寻址
-
只需要发送者命名接收者,如下
-
send(P,message):发送消息到进程P
-
receive(id,message):接收来自进程任何的消息,只需将ID对应即可
-
间接通信
-
只有在两个进程共享一个邮箱时,才能建立通信线路
-
一个线路可以与两个或更多的进程相关联
-
send(A,message):发送消息到邮箱A
-
receive(A,message):接收来自邮箱A的消息
- 同步
- 阻塞send:发送进程阻塞,直到消息被接收进程或邮箱所接收
- 非阻塞send:发送进程发送消息并再继续操作
- 阻塞receive:接受者阻塞,直到有消息可用
- 非阻塞receive:接收者收到一个有效消息或空消息
- 缓冲
- 不管通信是直接的或是间接地,通信进程所交换的消息都驻留在临时队列中
- 零容量:队列的最大长度为0;因此线路中不能有任何消息处于等待,对于这种情况,必须阻塞发送
- 有限容量:队列的长度为有限的n,因此最多智能有n个消息驻留其中。未满时,消息可以放入,如果线路满,就必须阻塞发送,知道队列中的空间可用为止
- 无限容量:队列长度可以无线,因此不管多少消息都可在其中等待,从不阻塞发送者

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









