




 本文介绍了JDBC数据提供器的执行流程,重点讲解了`execute`方法中服务端聚合与本地执行的区别,以及`executeLocalQuery`在内存数据库中的应用。通过`getDataProviderService`和`DataProviderAdapter`,展示了如何处理不同源类型的数据并执行SQL查询。
本文介绍了JDBC数据提供器的执行流程,重点讲解了`execute`方法中服务端聚合与本地执行的区别,以及`executeLocalQuery`在内存数据库中的应用。通过`getDataProviderService`和`DataProviderAdapter`,展示了如何处理不同源类型的数据并执行SQL查询。
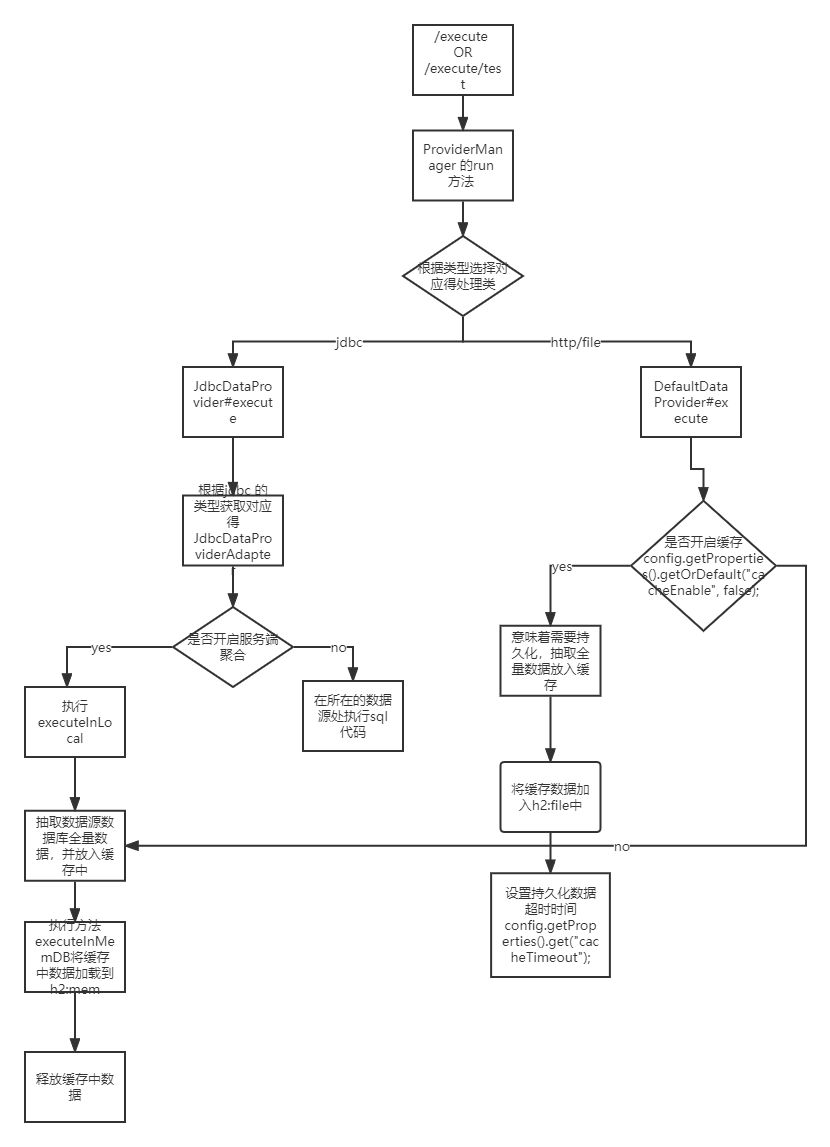
-执行 execute 或者 /execute/test都会执行到ProviderManager 的run 方法
public Dataframe run(DataProviderSource source, QueryScript queryScript, ExecuteParam param) throws Exception {
//source 的 type 为 jdbc 或者http 、file
Dataframe dataframe = getDataProviderService(source.getType()).execute(source, queryScript, param);
excludeColumns(dataframe, param.getIncludeColumns());
return dataframe;
}
- 如果是jdbc 调用JdbcDataProvider#execute
public Dataframe execute(DataProviderSource source, QueryScript script, ExecuteParam executeParam) throws Exception {
JdbcDataProviderAdapter adapter = matchProviderAdapter(source);
//If server aggregation is enabled, query the full data before performing server aggregation
//如果开启服务端聚合
if (executeParam.isServerAggregate()) {
return adapter.executeInLocal(script, executeParam);
} else {
//如果不开启则调用原始的数据库执行
return adapter.executeOnSource(script, executeParam);
}
}
public Dataframe executeInLocal(QueryScript script, ExecuteParam executeParam) throws Exception {
SqlScriptRender render = new SqlScriptRender(script
, executeParam
, getSqlDialect());
//生成原始的sql
String sql = render.render(false, false, false);
//执行sql 获取结果
Dataframe data = execute(sql);
if (!CollectionUtils.isEmpty(script.getSchema())) {
for (Column column : data.getColumns()) {
column.setType(script.getSchema().getOrDefault(column.getName(), column).getType());
}
}
data.setName(script.toQueryKey());
return LocalDB.executeLocalQuery(null, executeParam, Dataframes.of(script.getSourceId(), data));
}
//此方法仅为jdbc调用
public static Dataframe executeLocalQuery(QueryScript queryScript, ExecuteParam executeParam, Dataframes dataframes) throws Exception {
//复用下面一个方法 persistent 传false
return executeLocalQuery(queryScript, executeParam, dataframes, false, null);
}
public static Dataframe executeLocalQuery(QueryScript queryScript, ExecuteParam executeParam, Dataframes dataframes, boolean persistent, Date expire) throws Exception {
if (queryScript == null) {
// 直接以指定数据源为表进行查询,生成一个默认的SQL查询全部数据
queryScript = new QueryScript();
queryScript.setScript(String.format(SELECT_START_SQL, dataframes.getDataframes().get(0).getName()));
queryScript.setVariables(Collections.emptyList());
queryScript.setSourceId(dataframes.getKey());
}
//获取url 如果persistent 是true 则 使用h2:file 否则 使用h2:mem
String url = getConnectionUrl(persistent, dataframes.getKey());
synchronized (url.intern()) {
//根据persistent 判断使用那种方式 ,jdbc 只会传false
return persistent ? executeInLocalDB(queryScript, executeParam, dataframes, expire) : executeInMemDB(queryScript, executeParam, dataframes);
}
}
- 基于mem
private static Dataframe executeInMemDB(QueryScript queryScript, ExecuteParam executeParam, Dataframes dataframes) throws Exception {
Connection connection = getConnection(false, dataframes.getKey());
try {
for (Dataframe dataframe : dataframes.getDataframes()) {
//调用h2保存
registerDataAsTable(dataframe, connection);
}
return execute(connection, queryScript, executeParam);
} finally {
try {
connection.close();
} catch (Exception e) {
log.error("connection close error ", e);
}
for (Dataframe df : dataframes.getDataframes()) {
unregisterData(df.getId());
}
}
}

















 1012
1012

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









