







https://www.cnblogs.com/IvyWong/p/9203981.html
1、索引
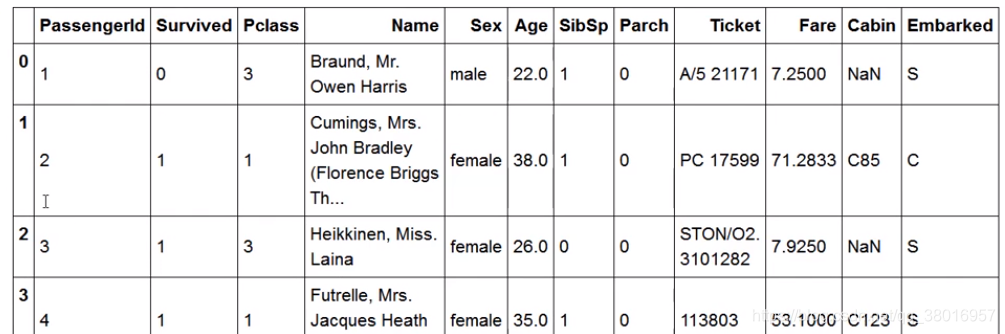
原数据:
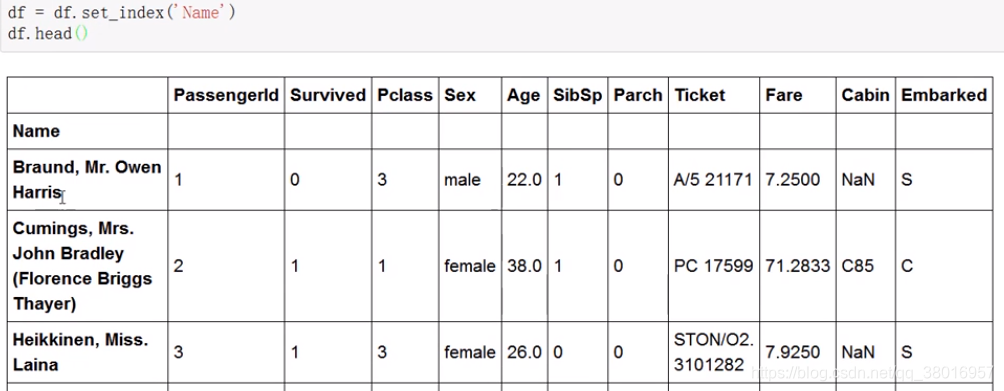
将‘name’设置为索引:
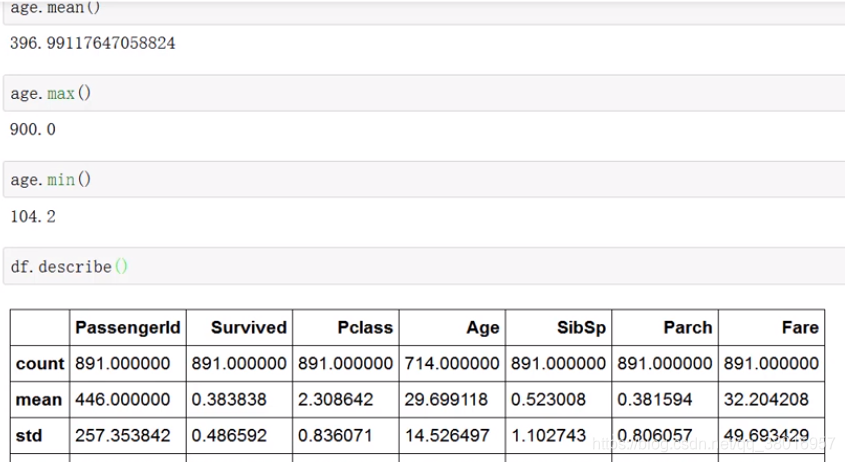
对age进行加法操作:
-加减乘除
- 求mean
- max
- min
- describe()


describe():得到数据统计特性
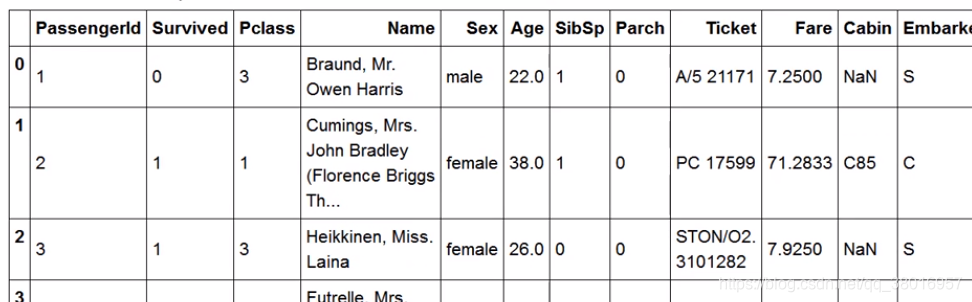
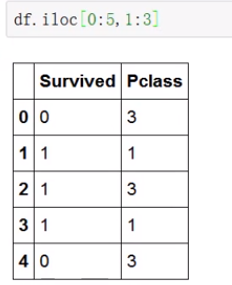
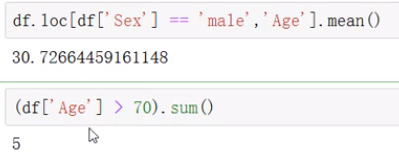
df.iloc[]:根据索引值(数值)查找
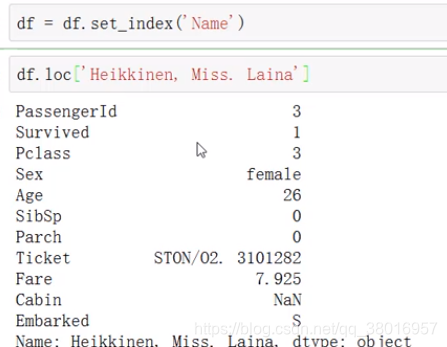
df.loc[]:以标签作为索引查找
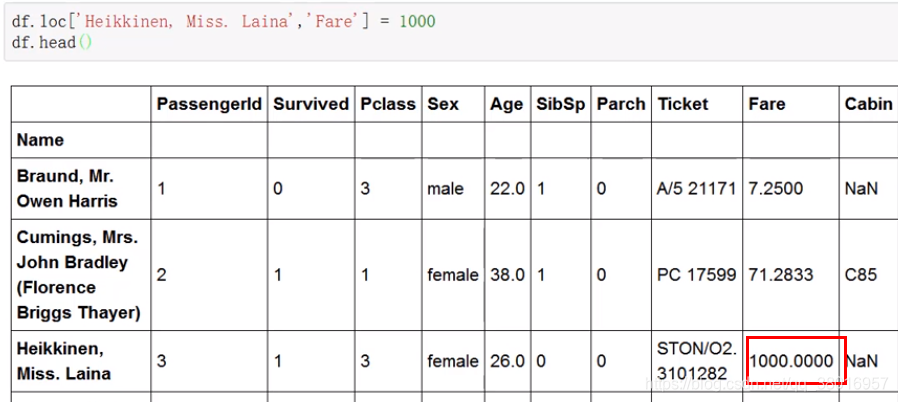
更改某个值:
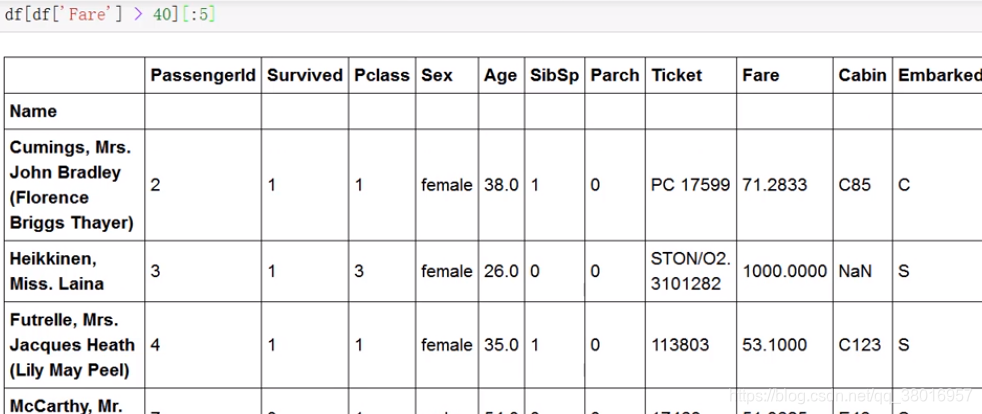
数据筛选:

再将Turn的索引取出:
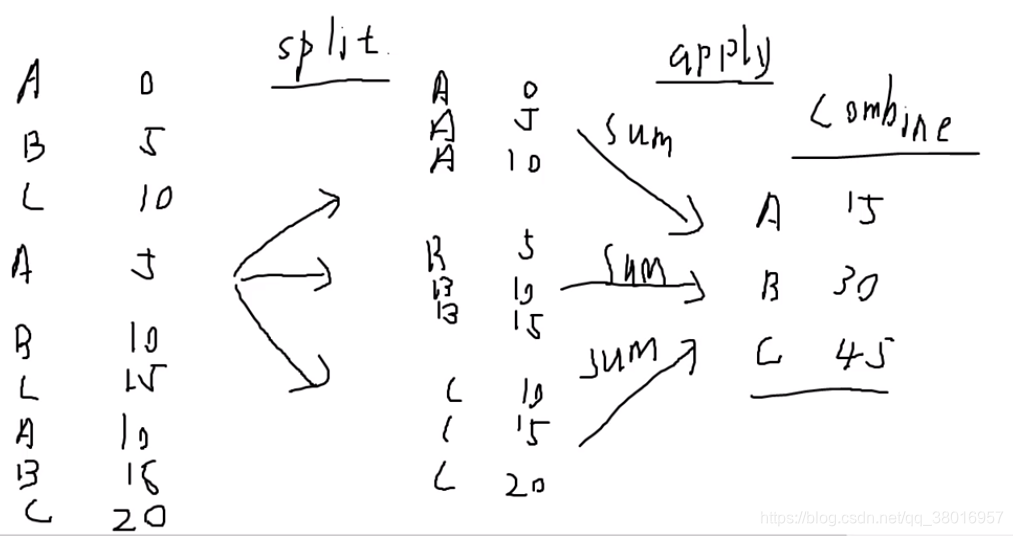
2、groubpy
groubpy原理:
求A、B、C各类的统计特性
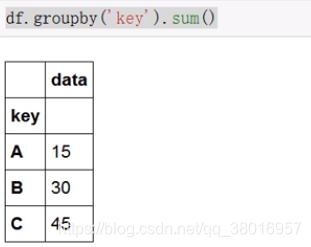
groubpy第一张方法:
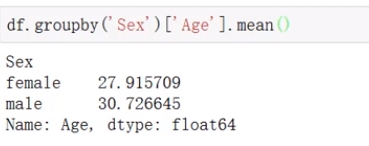
groubpy第二种方法:

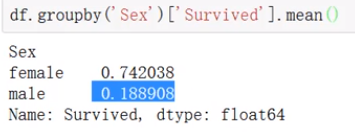
3、数值运算
创建:
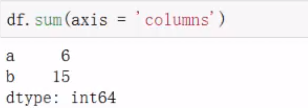
按行列求和:

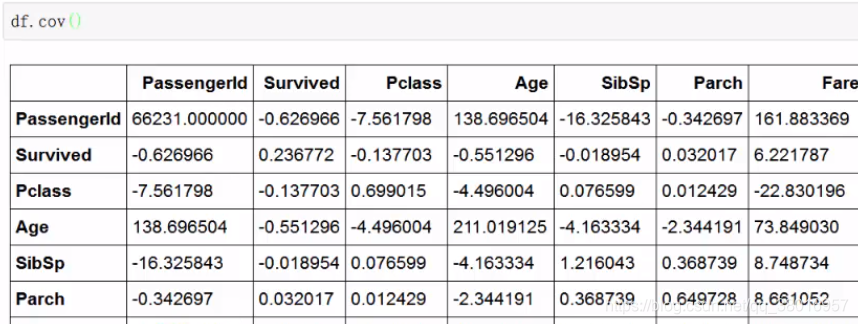
协方差:(对称)
相关系数:

统计每个值的个数:(按升序)
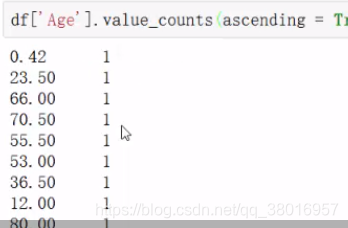
分组:在区域内的数量
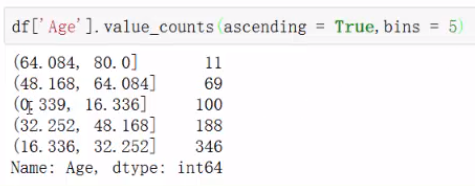
列的个数(值不为0)

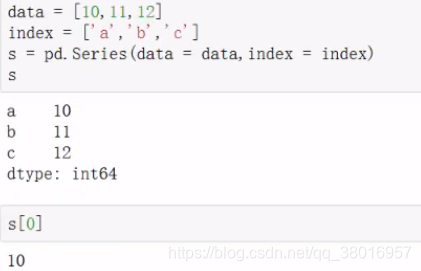
4、series对象的增删改查
查
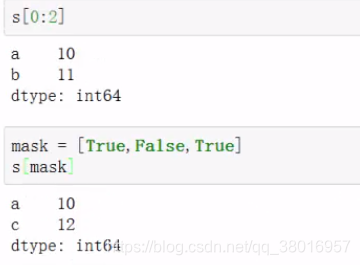

改
改数值:当inplace为False时,不在原数据上改
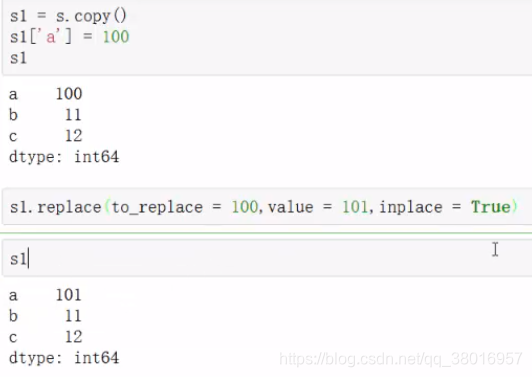
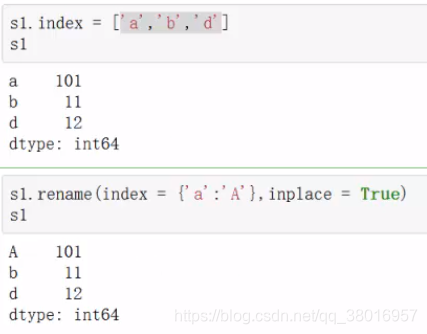
改索引:
增
append:
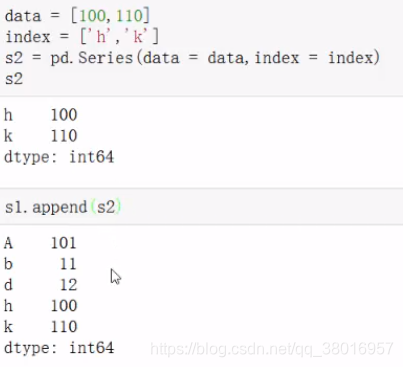
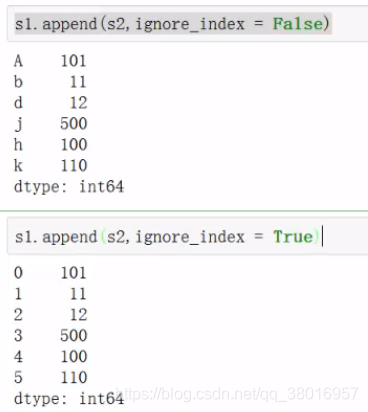
直接增加:

是否重新生成索引:
删
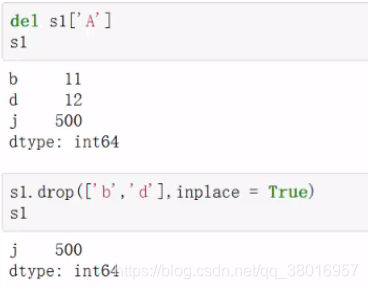
5、DataFrame的增删改查
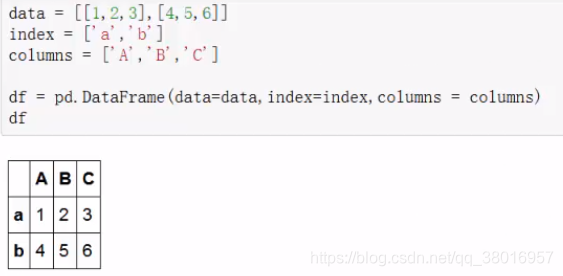
查
loc、iloc
改
改值:

改索引:

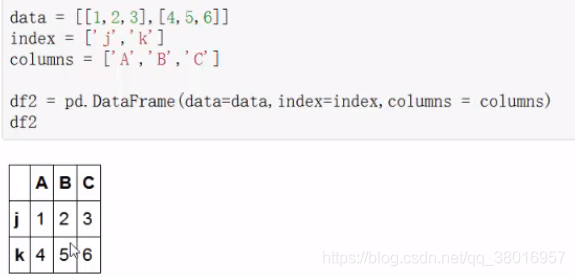
增

concat:
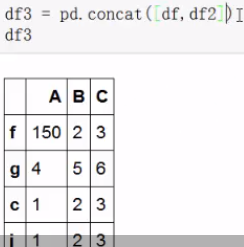
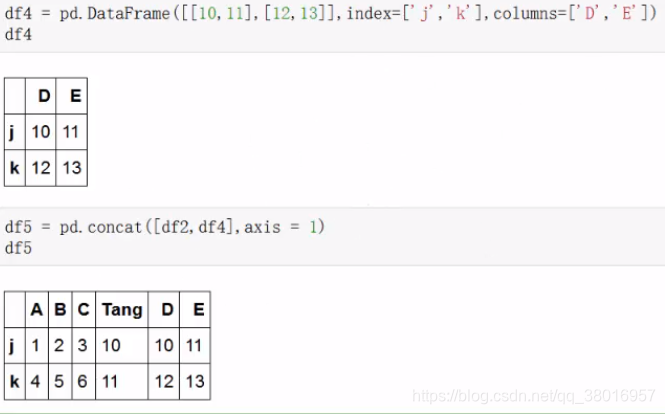
删
删除行:

删除列:

6、merge操作
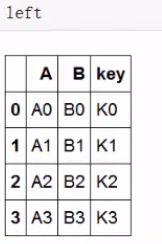
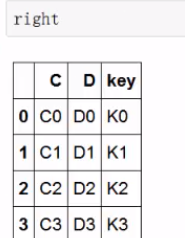
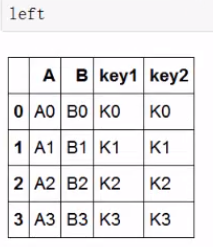
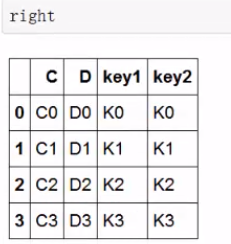
构建:

merge1
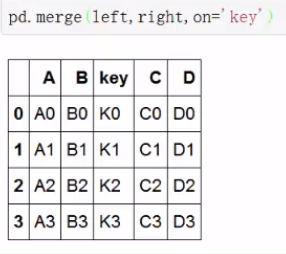
merge2
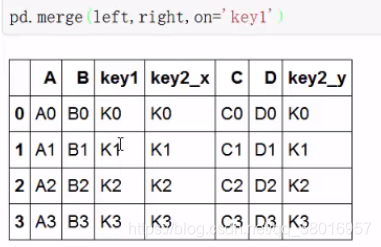
有重复字但不是merge的键时,多出后缀
若merge时,有一些列不一致,则不一样的被过滤,只会合并相同的列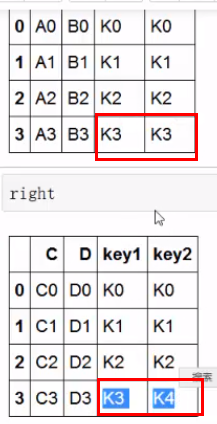

outer-全部合并

how-选择基准的表
*将表一和表二合并,且 hao的表 的全部留下


















 1073
1073

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









