







 本文详细介绍了如何在Linux环境下安装配置Hadoop,包括单机版、伪分布式和完全分布式,并解决了配置过程中遇到的找不到主类问题。此外,还展示了如何使用Visual Studio Code进行远程Java开发,包括设置环境、配置自动编译运行任务和测试Hadoop Java程序。
本文详细介绍了如何在Linux环境下安装配置Hadoop,包括单机版、伪分布式和完全分布式,并解决了配置过程中遇到的找不到主类问题。此外,还展示了如何使用Visual Studio Code进行远程Java开发,包括设置环境、配置自动编译运行任务和测试Hadoop Java程序。
Hadoop 安装
配置单机版和伪分布式
-
首先去各自官网下载jdk和hadoop,我这里下载的是oracle jdk 1.8 和 hadoop 3.3.0
-
配置环境变量
无论是编辑/etc/profile还是~/.bashrc都可以,只不过一个是系统环境变量一个是用户环境变量,一个配置好后各个用户下都会有配置的环境变量,一个只有当前用户有。
添加如下代码,记得替换/path/to/jdkexport JAVA_HOME=/path/to/jdk export JAVA_JRE=$JAVA_HOME/jre export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib: export HADOOP_HOME=/path/to/hadoop export HADOOP_MAPRED_HOME=$HADOOP_HOMR export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH -
这里请继续参照官方文档完成搭建
-
可能遇到的错误
我在自己的电脑上按照官方文档配置进行样例测试的时候遇到错误
找不到或无法加载主类 org.apache.hadoop.mapreduce.v2.app.MRAppMaster,但是帮同学配置的时候却没有这个问题。emmm…总之如果遇到这个问题可以按如下方法解决。。。
hadoop classpath输出
/home/beatback/hadoop/etc/hadoop:/home/beatback/hadoop/share/hadoop/common/lib/*:/home/beatback/hadoop/share/hadoop/common/*:/home/beatback/hadoop/share/hadoop/hdfs:/home/beatback/hadoop/share/hadoop/hdfs/lib/*:/home/beatback/hadoop/share/hadoop/hdfs/*:/home/beatback/hadoop/share/hadoop/mapreduce/*:/home/beatback/hadoop/share/hadoop/yarn:/home/beatback/hadoop/share/hadoop/yarn/lib/*:/home/beatback/hadoop/share/hadoop/yarn/*然后将输出内容按如下格式写入yarn-site.xml
<property> <name>yarn.application.classpath</name> <value>/home/beatback/hadoop/etc/hadoop:/home/beatback/hadoop/share/hadoop/common/lib/*:/home/beatback/hadoop/share/hadoop/common/*:/home/beatback/hadoop/share/hadoop/hdfs:/home/beatback/hadoop/share/hadoop/hdfs/lib/*:/home/beatback/hadoop/share/hadoop/hdfs/*:/home/beatback/hadoop/share/hadoop/mapreduce/*:/home/beatback/hadoop/share/hadoop/yarn:/home/beatback/hadoop/share/hadoop/yarn/lib/*:/home/beatback/hadoop/share/hadoop/yarn/*</value> </property >
配置完全分布式
-
修改配置文件
core-site.xml<property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property>mapred-site.xml
<property> <name>mapreduce.application.classpath</name> <value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value> </property>yarn-site.xml
<property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property>workers
worker1 worker2 worker3 -
配置hosts
192.168.37.140 master 192.168.37.141 worker1 192.168.37.142 worker2 192.168.37.143 worker3 -
修改各节点的主机名和IP地址以匹配hosts
sudo nano /etc/hostname -
删除各节点hdfs的tmp文件,默认在/tmp下
-
重新格式化hdfs并启动hadoop,在hdfs里创建用户目录,请将username换成你的用户名
hdfs namenode -format start-all.sh hdfs dfs -mkdir /user hdfs dfs -mkdir /user/username -
检验各节点是否正确工作
jps如果master节点只有namenode没有datanode而且worker节点只有datanode没有namenode就算配置成功了。
Visual Studio Code 远程编写编译运行hadoop java 程序
-
客户端 VS Code 安装 Java Extension Pack 和 Remote SSH 插件
-
安装 jdk 11
如果你本来装的就是高版本的JAVA 可以跳过这一步,因为VS Code的Java插件需要至少 Java 11 或者更新的版本,而我之前装的是Java 8。。。
如果需要安装Java 11请安装Oracle JDK 11。
如果你非要安装openjdk 11,请确保同时也安装了一个可用版本的Oracle JDK并将第8步tasks.json中的javac和jar使用你安装的Oracle JDK中对应的二进制文件的绝对路径替换。 -
客户端 VS Code 设置 SSH 密码登录
勾选 Show Login Terminal
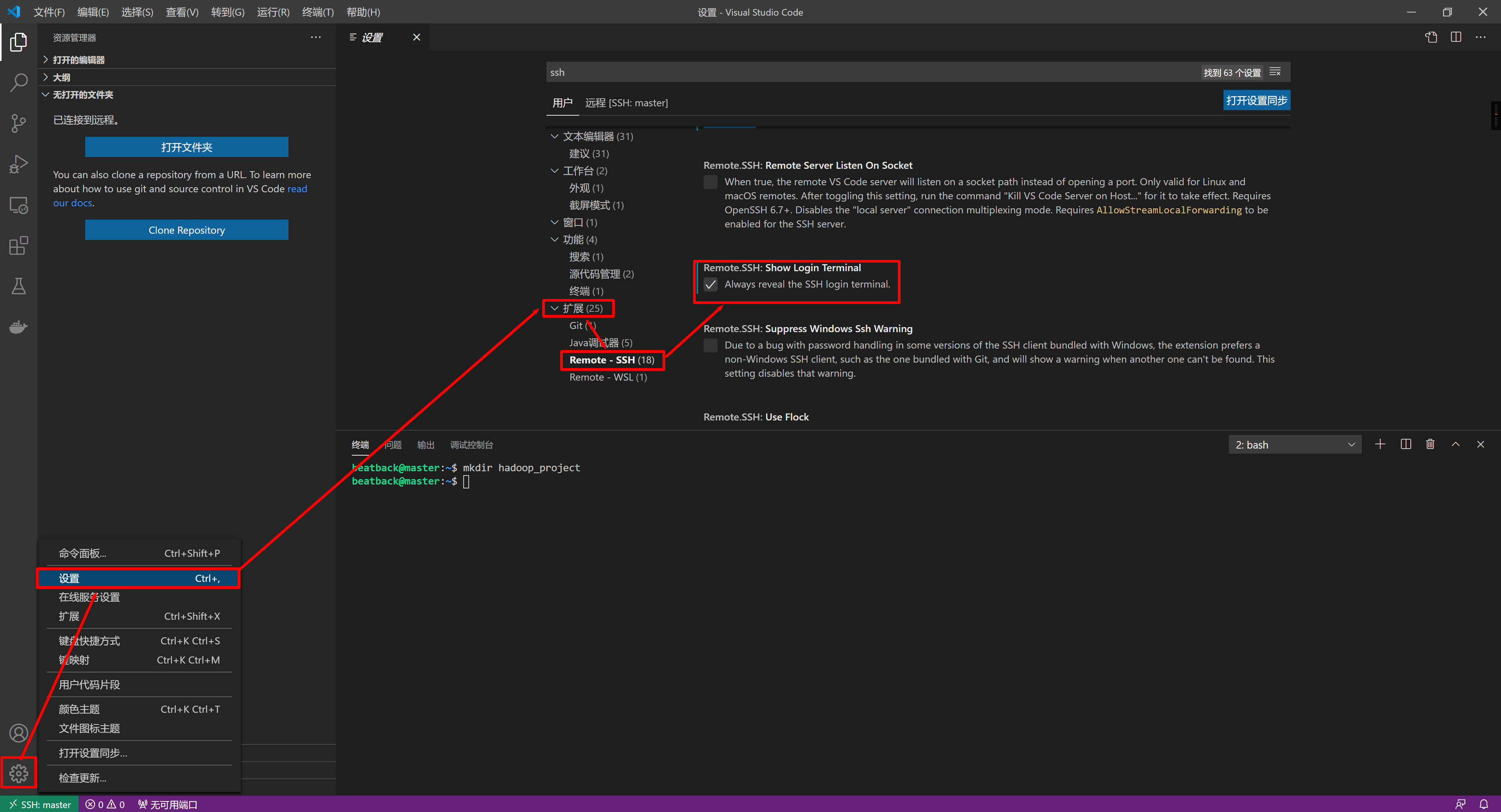
其实也可以设置无密码登录,将 master 的 ~/.ssh/id_rsa.pub 的内容 添加到 用户文件夹下的.ssh文件夹里的 authorized_keys -
客户端 VS Code 打开远程连接 并 输入密码完成SSH登陆

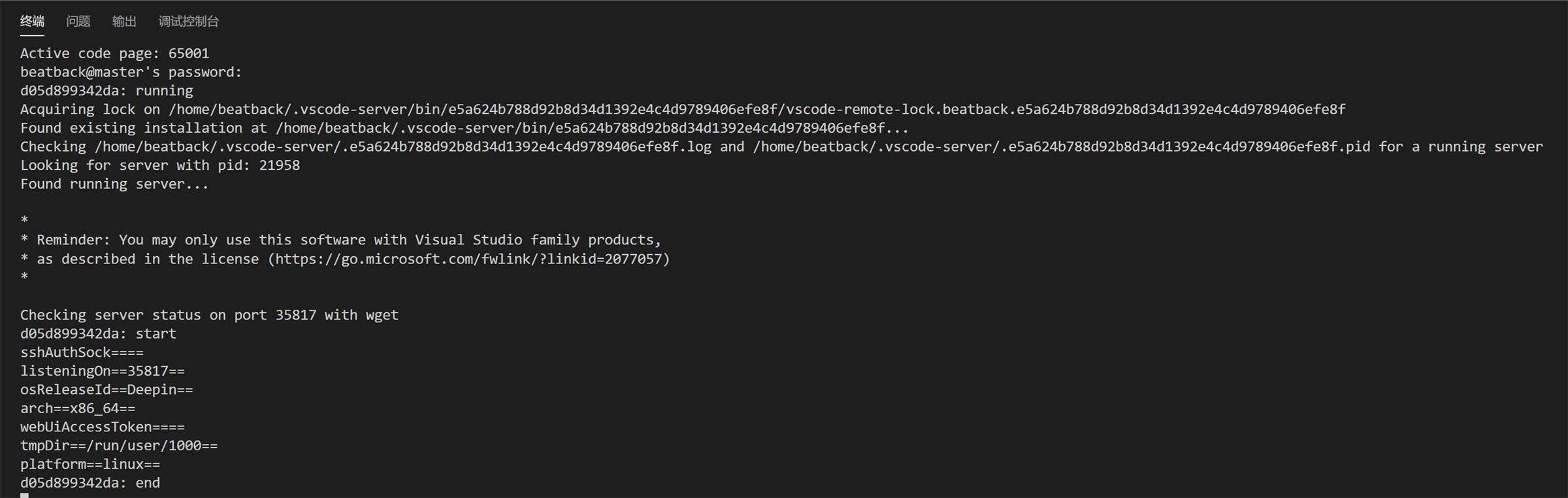
-
客户端 VS Code 在 master 上加载 Java Extension Pack 插件

-
在 master 上创建一个JAVA项目,项目名字随便取
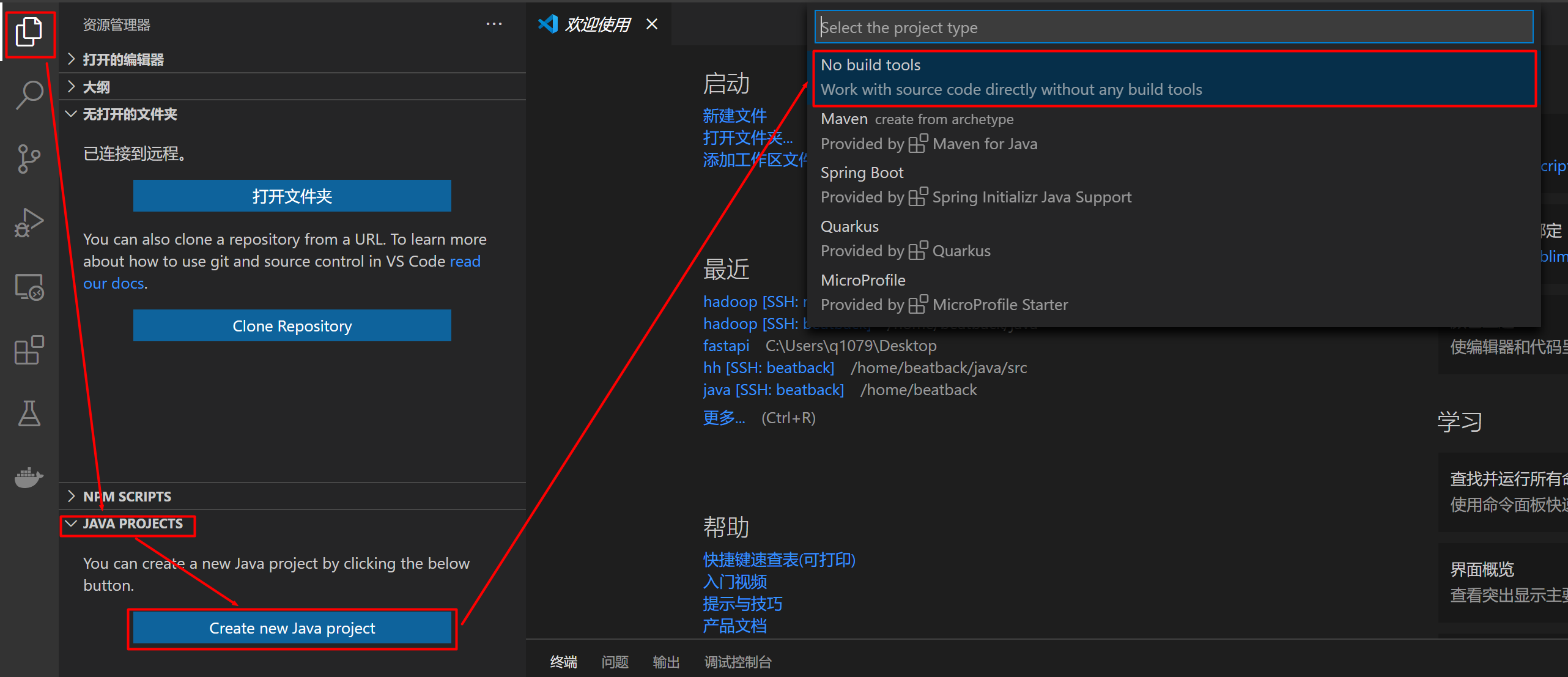

然后VS Code会重新打开编辑器,需要再输入一次SSH密码 -
在src目录下新建一个
WordCount.java,粘贴官方的WordCount示例代码进去
JAVA不熟悉的同学注意不要把package那行给复制进去了啊 -
载入hadoop依赖包(imports 以 WordCount 为例)
可以在.vscode 文件夹下新建一个settings.json并编辑如下{ "java.project.referencedLibraries": [ "lib/**/*.jar", "/home/beatback/hadoop/share/hadoop/common/hadoop-common-3.3.0.jar", "/home/beatback/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-common-3.3.0.jar", "/home/beatback/hadoop/share/hadoop/common/lib/commons-cli-1.2.jar", "/home/beatback/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-core-3.3.0.jar", "/home/beatback/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.3.0.jar" ], }其实也可以用图形界面一个一个添加依赖jar
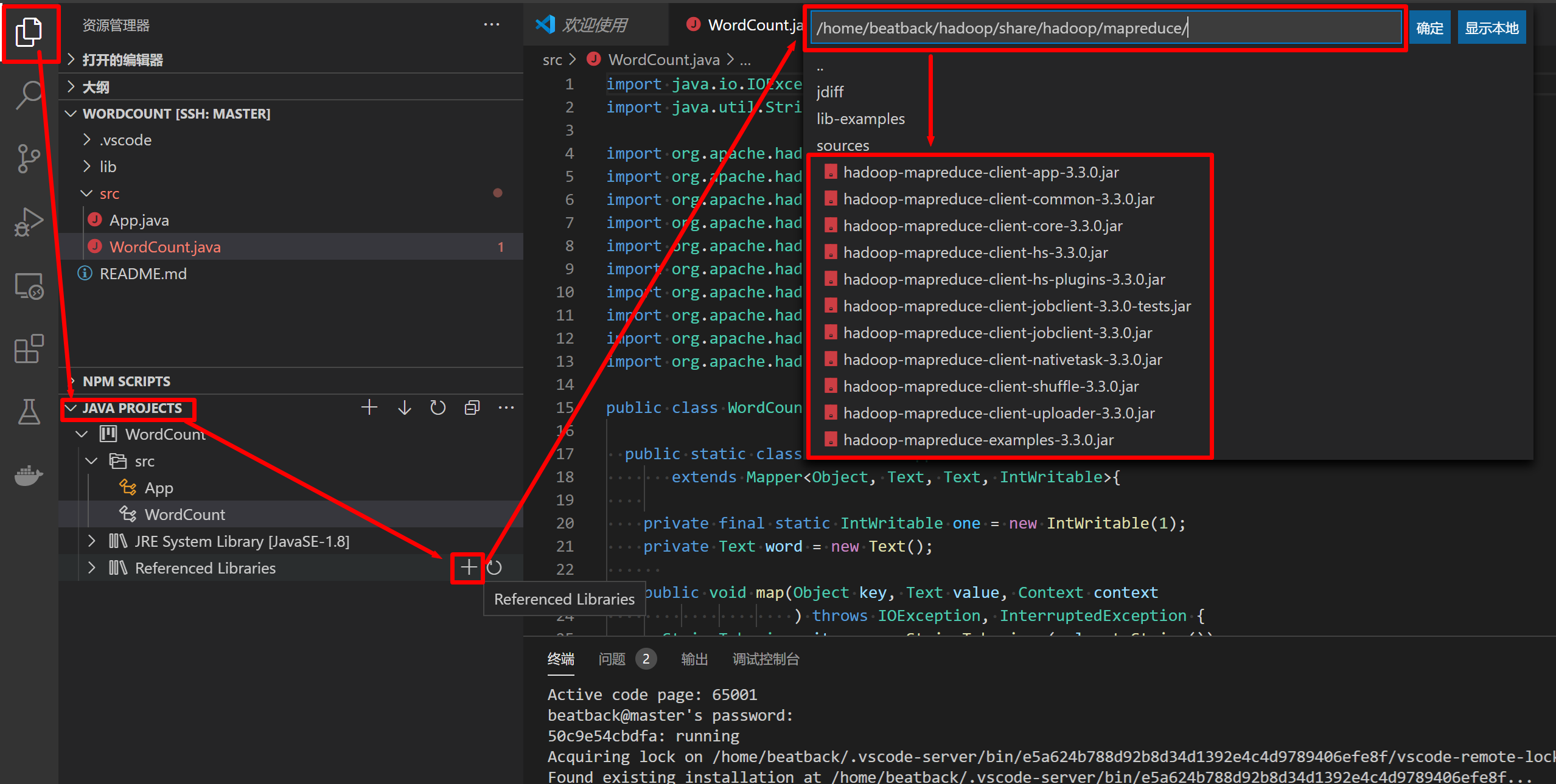
-
配置自动编译运行任务
在.vscode文件夹下新建task.json或者ctrl+shift+p调出命令面板选择配置生成任务如下所示
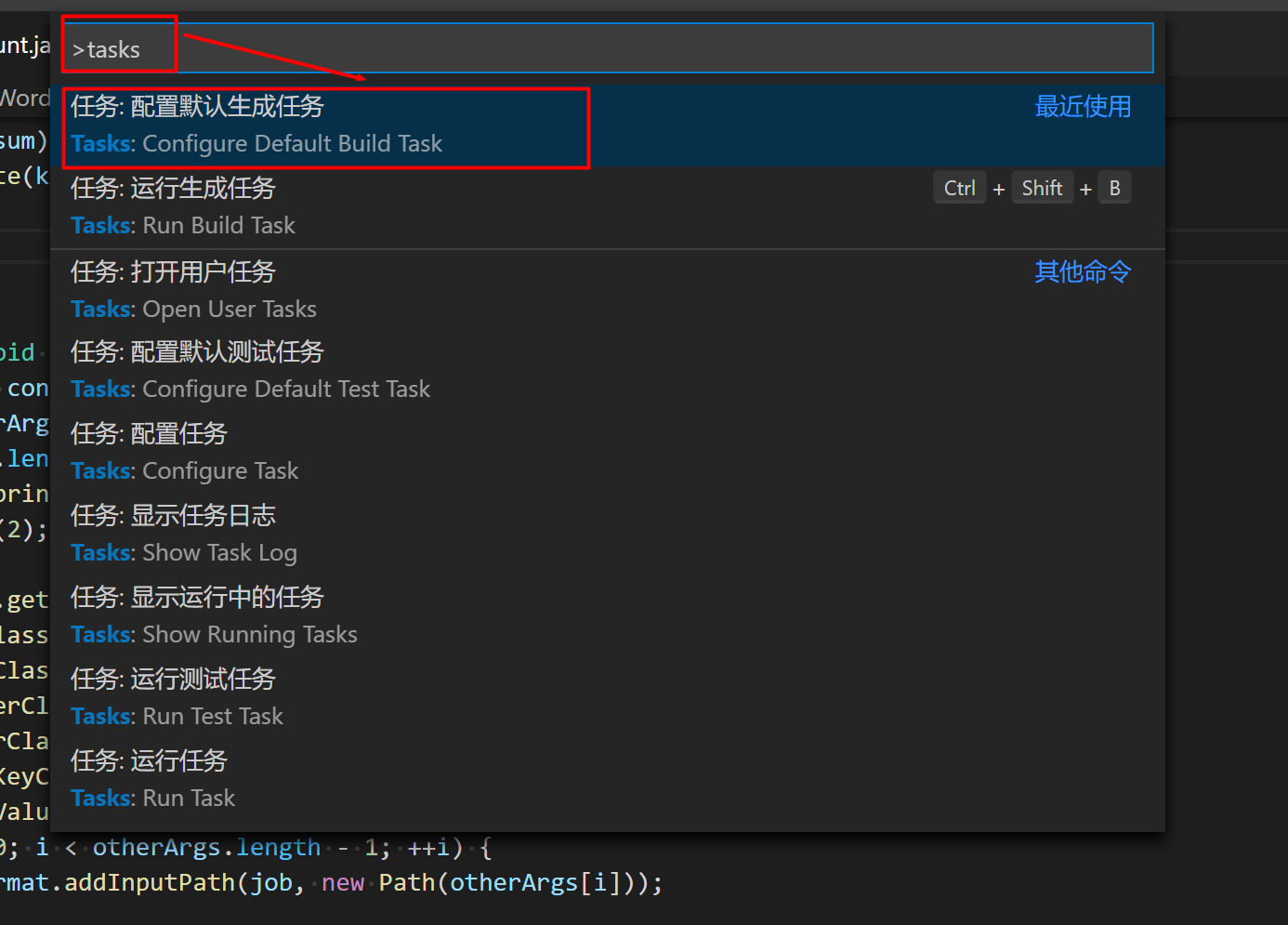
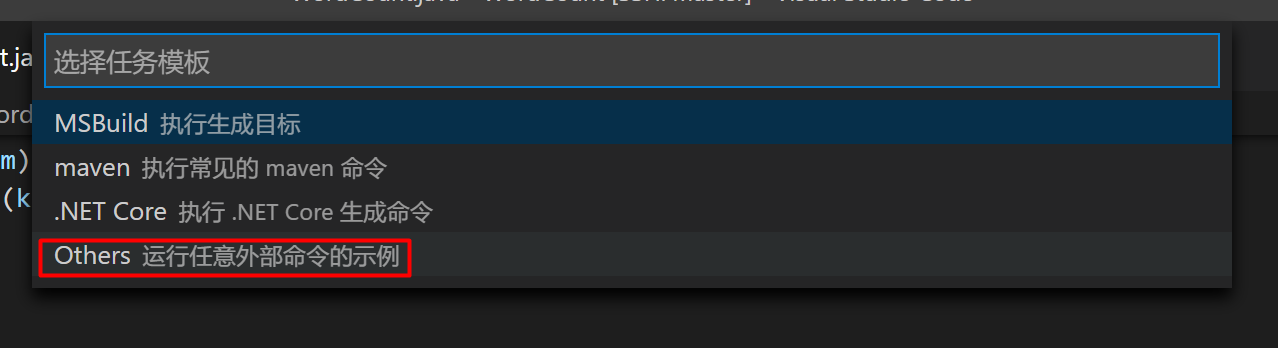
使用如下代码代替其中的内容{ // See https://go.microsoft.com/fwlink/?LinkId=733558 // for the documentation about the tasks.json format "version": "2.0.0", "tasks": [ { "label": "hadoop - start service", "type": "shell", "command": "start-all.sh", "options": { "cwd": "${workspaceFolder}" }, "group": "build" }, { "label": "hadoop - build & run", "type": "shell", "command": "mkdir /tmp/a2f2ed || : && javac -cp $(hadoop classpath) -d /tmp/a2f2ed ${file} && jar -cvf bin/test.jar -C /tmp/a2f2ed . && rm -rf /tmp/a2f2ed || :&& hdfs dfs -rm -r /input || : && hdfs dfs -put input / && hdfs dfs -rm -r /output || :&& hadoop jar bin/test.jar ${fileBasenameNoExtension} /input /output && hdfs dfs -cat /output/*", "options": { "cwd": "${workspaceFolder}" }, "group": "build" }, { "label": "hadoop - stop service", "type": "shell", "command": "stop-all.sh", "options": { "cwd": "${workspaceFolder}" }, "group": "build" }, ] } -
创建测试样例
项目下新建input文件夹,并放入一个test.txt,输入任意英文,比如HELLO WORLD THIS IS A HELLO WORLD DEMO IN HADOOP WORLD -
编译运行WordCount程序
如果项目下没有bin文件夹,请先建立bin文件夹
切换到WordCount.java文件
使用ctrl+shift+B调用tasks执行hadoop - start service启动hadoop
然后再次使用ctrl+shift+B调用tasks执行hadoop - build & run编译运行WordCount程序
在hadoop出现故障时可以使用使用ctrl+shift+B调用tasks执行hadoop - stop service关闭hadoop
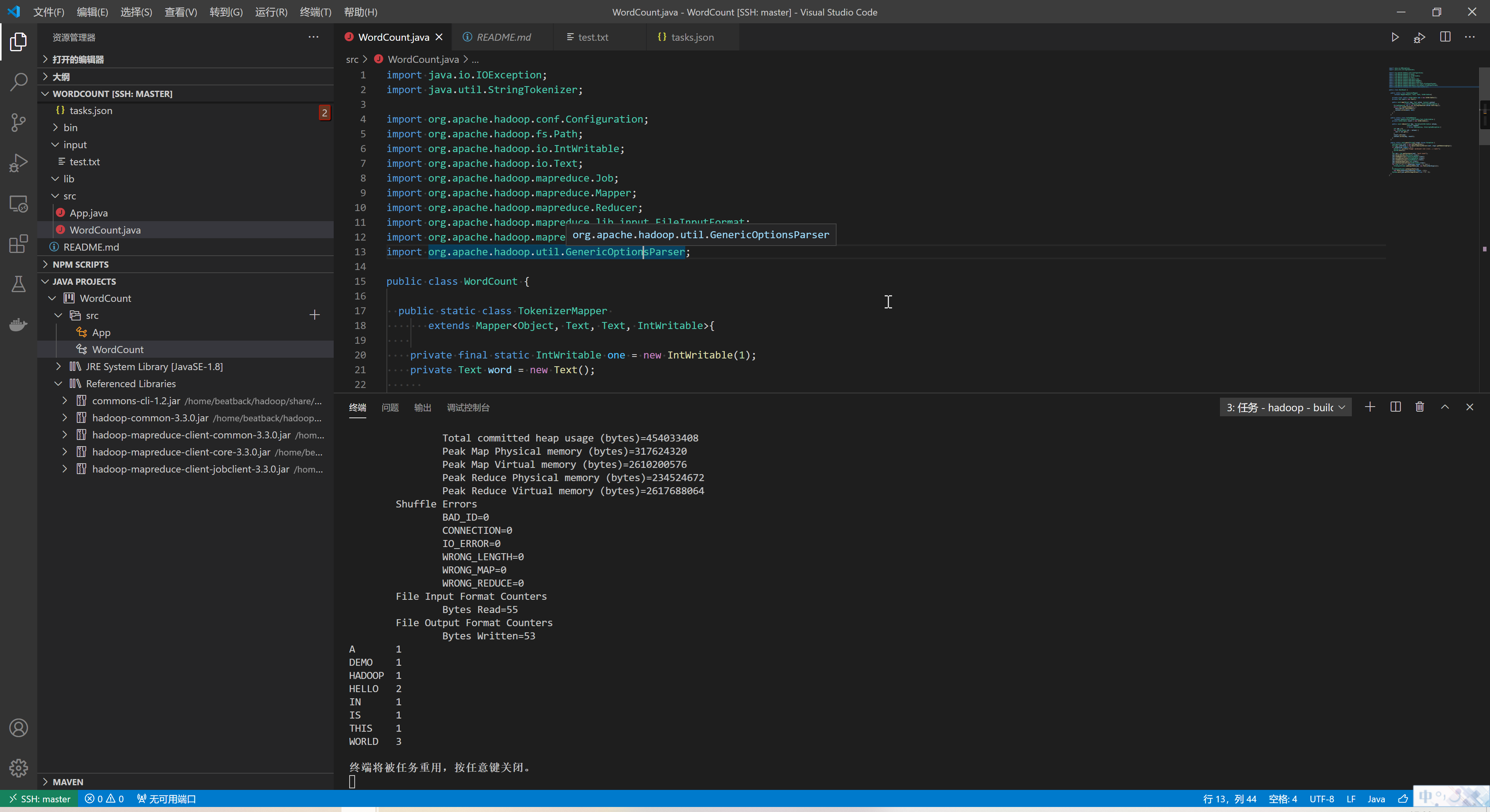
结语
因为自己没怎么编译过java,研究打包java花了不少时间
其次是第8步的自动编译执行脚本花费了我很多时间,因为java插件没法配置让编译出来的程序由hadoop执行,vscode也没有像eclipse那样的插件,并且google上也找不到有人配置过vscode的hadoop编程环境,因此我在vscode的官方文档找到发现tasks可能可以实现自动编译就花了好几个小时,在不停失败后实现了自动编译hadoop执行的功能

















 3317
3317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









