




Python自动化办公:openpyxl教程(基础)-优快云博客
https://zhuanlan.zhihu.com/p/342422919
https://openpyxl-chinese-docs.readthedocs.io/zh-cn/latest/tutorial.html
列标题,是这一列 对应的单元格的格式,默认是常规,设置之后,对已有的数据双击单元格才会生效,没有数据的写入后自动生效。没有数据就是None,文本是以字符串存储

# 导入openpyxl模块的 load_workbook类
import datetime
from openpyxl import load_workbook
wb = load_workbook('实例.xlsx')
ws = wb[wb.sheetnames[0]]
# 读取表格数据
for row in ws.rows:
print(row)
for cell in row:
print(type(cell.value),cell.value)
# 关闭文件
wb.close()
"""
(<Cell 'Sheet1'.A1>, <Cell 'Sheet1'.B1>, <Cell 'Sheet1'.C1>, <Cell 'Sheet1'.D1>, <Cell 'Sheet1'.E1>, <Cell 'Sheet1'.F1>, <Cell 'Sheet1'.G1>)
<class 'str'> 常规
<class 'str'> 数值
<class 'str'> 文本
<class 'str'> 日期
<class 'NoneType'> None
<class 'NoneType'> None
<class 'NoneType'> None
(<Cell 'Sheet1'.A2>, <Cell 'Sheet1'.B2>, <Cell 'Sheet1'.C2>, <Cell 'Sheet1'.D2>, <Cell 'Sheet1'.E2>, <Cell 'Sheet1'.F2>, <Cell 'Sheet1'.G2>)
<class 'float'> 1.32
<class 'float'> 1.32
<class 'str'> 1.32
<class 'datetime.datetime'> 2024-12-30 01:00:00
<class 'NoneType'> None
<class 'NoneType'> None
<class 'NoneType'> None
(<Cell 'Sheet1'.A3>, <Cell 'Sheet1'.B3>, <Cell 'Sheet1'.C3>, <Cell 'Sheet1'.D3>, <Cell 'Sheet1'.E3>, <Cell 'Sheet1'.F3>, <Cell 'Sheet1'.G3>)
<class 'int'> 15689
<class 'int'> 15689
<class 'str'> 15689
<class 'datetime.datetime'> 2024-12-28 01:00:00
<class 'NoneType'> None
<class 'NoneType'> None
<class 'NoneType'> None
(<Cell 'Sheet1'.A4>, <Cell 'Sheet1'.B4>, <Cell 'Sheet1'.C4>, <Cell 'Sheet1'.D4>, <Cell 'Sheet1'.E4>, <Cell 'Sheet1'.F4>, <Cell 'Sheet1'.G4>)
<class 'NoneType'> None
<class 'float'> 15689.01
<class 'str'> 123
<class 'NoneType'> None
<class 'NoneType'> None
<class 'NoneType'> None
<class 'NoneType'> None
(<Cell 'Sheet1'.A5>, <Cell 'Sheet1'.B5>, <Cell 'Sheet1'.C5>, <Cell 'Sheet1'.D5>, <Cell 'Sheet1'.E5>, <Cell 'Sheet1'.F5>, <Cell 'Sheet1'.G5>)
<class 'NoneType'> None
<class 'int'> 158
<class 'str'> 1.56
<class 'NoneType'> None
<class 'NoneType'> None
<class 'NoneType'> None
<class 'NoneType'> None
(<Cell 'Sheet1'.A6>, <Cell 'Sheet1'.B6>, <Cell 'Sheet1'.C6>, <Cell 'Sheet1'.D6>, <Cell 'Sheet1'.E6>, <Cell 'Sheet1'.F6>, <Cell 'Sheet1'.G6>)
<class 'NoneType'> None
<class 'NoneType'> None
<class 'NoneType'> None
<class 'NoneType'> None
<class 'NoneType'> None
<class 'NoneType'> None
<class 'NoneType'> None
(<Cell 'Sheet1'.A7>, <Cell 'Sheet1'.B7>, <Cell 'Sheet1'.C7>, <Cell 'Sheet1'.D7>, <Cell 'Sheet1'.E7>, <Cell 'Sheet1'.F7>, <Cell 'Sheet1'.G7>)
<class 'NoneType'> None
<class 'NoneType'> None
<class 'NoneType'> None
<class 'NoneType'> None
<class 'NoneType'> None
<class 'NoneType'> None
<class 'NoneType'> None
(<Cell 'Sheet1'.A8>, <Cell 'Sheet1'.B8>, <Cell 'Sheet1'.C8>, <Cell 'Sheet1'.D8>, <Cell 'Sheet1'.E8>, <Cell 'Sheet1'.F8>, <Cell 'Sheet1'.G8>)
<class 'NoneType'> None
<class 'NoneType'> None
<class 'NoneType'> None
<class 'NoneType'> None
<class 'NoneType'> None
<class 'NoneType'> None
<class 'NoneType'> None
"""
from openpyxl import load_workbook
book = load_workbook(filename='income.xlsx')
ws = book['Sheet1']
# 方法一
# 获取A2这个单元格
cell_A2 = ws['A2']
print(cell_A2) # <Cell 'Sheet1'.A2>
# 方法二:row 行;column 列
# 获取B2这个单元格
cell_B2 = ws.cell(row=2, column=2)
# 通过切片
cell_area = ws['A1':'B4']
print(cell_area)
"""
每一行的内容返回一个元组,最终是元组构成的元组
((<Cell 'Sheet1'.A1>, <Cell 'Sheet1'.B1>), (<Cell 'Sheet1'.A2>, <Cell 'Sheet1'.B2>),
(<Cell 'Sheet1'.A3>, <Cell 'Sheet1'.B3>), (<Cell 'Sheet1'.A4>, <Cell 'Sheet1'.B4>))
"""
cell_exact = ws.iter_rows(min_row=1, max_row=2, min_col=1, max_col=2) #即A1:B2
print(cell_exact) # <generator object Worksheet._cells_by_row at 0x0000021965587900>
for i in cell_exact:
print(i)
"""
每一行构成的元组
(<Cell 'Sheet1'.A1>, <Cell 'Sheet1'.B1>)
(<Cell 'Sheet1'.A2>, <Cell 'Sheet1'.B2>)
"""
cell_exact2 = ws.iter_cols(max_col=2, max_row=2)
print(cell_exact2) # <generator object Worksheet._cells_by_col at 0x000001F599352C10>
for col in cell_exact2: #即A1:B2
print(col)
"""
(<Cell 'Sheet1'.A1>, <Cell 'Sheet1'.A2>)
(<Cell 'Sheet1'.B1>, <Cell 'Sheet1'.B2>)
"""
# 通过行/列
col_A = ws['A'] # A列
print(col_A)
"""
列单元格构成的元组
(<Cell 'Sheet1'.A1>, <Cell 'Sheet1'.A2>,
<Cell 'Sheet1'.A3>, <Cell 'Sheet1'.A4>,
<Cell 'Sheet1'.A5>, <Cell 'Sheet1'.A6>)
"""
col_area = ws['A:B'] # A、B列
"""
A列是一个元组,B列是一个元组
((<Cell 'Sheet1'.A1>, <Cell 'Sheet1'.A2>, <Cell 'Sheet1'.A3>,
<Cell 'Sheet1'.A4>, <Cell 'Sheet1'.A5>, <Cell 'Sheet1'.A6>),
(<Cell 'Sheet1'.B1>, <Cell 'Sheet1'.B2>, <Cell 'Sheet1'.B3>,
<Cell 'Sheet1'.B4>, <Cell 'Sheet1'.B5>, <Cell 'Sheet1'.B6>))
"""
print(col_area)
row_2 = ws[2] # 第2行
print(row_2)
# (<Cell 'Sheet1'.A2>, <Cell 'Sheet1'.B2>, <Cell 'Sheet1'.C2>)
row_area = ws[2:3] # 2-3行
print(row_area)
"""
每一个单元格构成一个元组
((<Cell 'Sheet1'.A2>, <Cell 'Sheet1'.B2>, <Cell 'Sheet1'.C2>),
(<Cell 'Sheet1'.A3>, <Cell 'Sheet1'.B3>, <Cell 'Sheet1'.C3>))
"""
# 迭代所有行
all_by_row = ws.rows
print(all_by_row)
# <generator object Worksheet._cells_by_row at 0x00000213573C46D0>
print(list(all_by_row))
"""
[(<Cell 'Sheet1'.A1>, <Cell 'Sheet1'.B1>, <Cell 'Sheet1'.C1>),
(<Cell 'Sheet1'.A2>, <Cell 'Sheet1'.B2>, <Cell 'Sheet1'.C2>),
(<Cell 'Sheet1'.A3>, <Cell 'Sheet1'.B3>, <Cell 'Sheet1'.C3>),
(<Cell 'Sheet1'.A4>, <Cell 'Sheet1'.B4>, <Cell 'Sheet1'.C4>),
(<Cell 'Sheet1'.A5>, <Cell 'Sheet1'.B5>, <Cell 'Sheet1'.C5>),
(<Cell 'Sheet1'.A6>, <Cell 'Sheet1'.B6>, <Cell 'Sheet1'.C6>)]
"""
"""
Python 中的生成器(如 ws.rows, ws.columns)就像一个“流水线”,
每次读取就前进一格。读完一次后,这个生成器就“空”了,不能再次使用。
生成器只能遍历一次 所以使用tuple的时候需要在生成一次
"""
all_by_row2 = ws.rows
print(tuple(all_by_row2))
"""
((<Cell 'Sheet1'.A1>, <Cell 'Sheet1'.B1>, <Cell 'Sheet1'.C1>),
(<Cell 'Sheet1'.A2>, <Cell 'Sheet1'.B2>, <Cell 'Sheet1'.C2>),
(<Cell 'Sheet1'.A3>, <Cell 'Sheet1'.B3>, <Cell 'Sheet1'.C3>),
(<Cell 'Sheet1'.A4>, <Cell 'Sheet1'.B4>, <Cell 'Sheet1'.C4>),
(<Cell 'Sheet1'.A5>, <Cell 'Sheet1'.B5>, <Cell 'Sheet1'.C5>),
(<Cell 'Sheet1'.A6>, <Cell 'Sheet1'.B6>, <Cell 'Sheet1'.C6>))
"""
# 迭代所有列
all_by_col = ws.columns
print(all_by_col)
# <generator object Worksheet._cells_by_col at 0x00000213573E4430>
print(list(all_by_col))
"""
[(<Cell 'Sheet1'.A1>, <Cell 'Sheet1'.A2>, <Cell 'Sheet1'.A3>,
<Cell 'Sheet1'.A4>, <Cell 'Sheet1'.A5>, <Cell 'Sheet1'.A6>),
(<Cell 'Sheet1'.B1>, <Cell 'Sheet1'.B2>, <Cell 'Sheet1'.B3>,
<Cell 'Sheet1'.B4>, <Cell 'Sheet1'.B5>, <Cell 'Sheet1'.B6>),
(<Cell 'Sheet1'.C1>, <Cell 'Sheet1'.C2>, <Cell 'Sheet1'.C3>,
<Cell 'Sheet1'.C4>, <Cell 'Sheet1'.C5>, <Cell 'Sheet1'.C6>)]
"""
all_by_col2 = ws.columns
print(tuple(all_by_col2))
"""
((<Cell 'Sheet1'.A1>, <Cell 'Sheet1'.A2>, <Cell 'Sheet1'.A3>,
<Cell 'Sheet1'.A4>, <Cell 'Sheet1'.A5>, <Cell 'Sheet1'.A6>),
(<Cell 'Sheet1'.B1>, <Cell 'Sheet1'.B2>, <Cell 'Sheet1'.B3>,
<Cell 'Sheet1'.B4>, <Cell 'Sheet1'.B5>, <Cell 'Sheet1'.B6>),
(<Cell 'Sheet1'.C1>, <Cell 'Sheet1'.C2>, <Cell 'Sheet1'.C3>,
<Cell 'Sheet1'.C4>, <Cell 'Sheet1'.C5>, <Cell 'Sheet1'.C6>))
"""
print(ws.max_row, ws.max_column)
# 6 3 第六行虽然没数据 但是我设置了单元格格式。
#------
# row_dimensions 行的属性 column_dimensions 列的属性
# 如果你只想要工作薄的值,
# 你可以使用 Worksheet.values 属性。
# 这会遍历工作簿中所有的行但只返回单元格值:
print(ws.values) # <generator object Worksheet.values at 0x00000286C5054C10>
print(list(ws.values))
"""
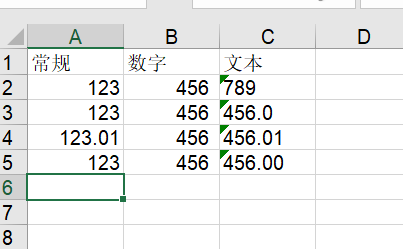
[('常规', '数字', '文本'), (123, 456, '789'),
(123, 456, '456.0'), (123.01, 456.01, '456.01'),
(123, 456, '456.00'), (None, None, None)]
"""
# Worksheet.iter_rows 和 Worksheet.iter_cols 可以用 values_only 参数来返回单元格值:
cell_areav = ws.iter_rows(min_row=1, max_row=2,
min_col=1, max_col=2, values_only=True) #即A1:B2
print(cell_areav)
# <generator object Worksheet._cells_by_row at 0x00000256DF983BA0>
print(list(cell_areav))
# [('常规', '数字'), (123, 456)]

















 5368
5368

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









