




 文章使用VGG19网络进行图像风格迁移训练,未用全连接层,以平均池化替代最大池化。通过多组内容和风格重构对比实验,确定内容层和风格层。还调整噪声比率,发现比率越接近1风格越明显。每次训练更新随机初始化输入x,生成合成画需重新训练,速度慢。
文章使用VGG19网络进行图像风格迁移训练,未用全连接层,以平均池化替代最大池化。通过多组内容和风格重构对比实验,确定内容层和风格层。还调整噪声比率,发现比率越接近1风格越明显。每次训练更新随机初始化输入x,生成合成画需重新训练,速度慢。
文章使用了VGG19网络来进行训练,(包含了16个卷积层和5个池化层,但是实际训练中未使用任何全连接层,并且是使用了平均池化average-pooling替代最大池化max-pooling)
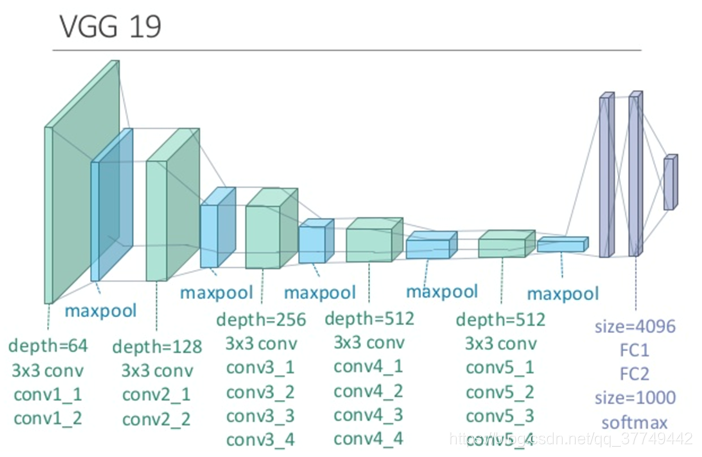
内容层和风格层的选择:将内容图像和风格图像分别输入到VGG网络中,并将网络各个层的特征图(feature map)进行可视化(重构)。
内容重构五组对比实验:
- conv1_1 (a)
- conv2_1 (b)
- conv3_1 ©
- conv4_1 (d)
- conv5_1 (e)
风格重构五组对比实验: - conv1_1 (a)
- conv1_1 and conv2_1 (b)
- conv1_1, conv2_1 and conv3_1 ©
- conv1_1, conv2_1, conv3_1 and conv4_1 (d)
- conv1_1, conv2_1, conv3_1, conv4_1 and conv5_1 (e)
通过实验发现:对于内容重构,(d)和(e)较好地保留了图像的高阶内容(high-level content)而丢弃了过于细节的像素信息;对于风格重构,(e)则较好地描述了艺术画的风格。如下图红色方框标记:

实际实验中,
内容层选择了conv4_2
风格层选择了conv1_1,conv2_1,conv3_1,conv4_1,conv5_1
(但是在我自己实验过程中,对内容层的选择似乎也可以得到风格迁移的结果,我自己用了内容层的conv2_2作为实验,同时对风格层的选择也进行了不同选择,结果也是一样的。只是在图像的风格上变得更加明显。)
在噪声比率上,我自己做了较大的调整,从noise=0.1-0.6-1。在等于1时,结果图只剩下风格图,看不到内容。比率越接近1,风格越明显。
**
1.5 总结
**
每次训练迭代,更新的参数并非VGG19网络本身,而是随机初始化的输入x;
由于输入x是随机初始化的,最终得到的“合成画”会有差异;
每生成一幅“合成画”,都要重新训练一次,速度较慢,难以做到实时。
博客中只要讲解了两篇风格迁移的论文


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









