




 这篇文章介绍了Wenet,一个专注于长音频处理的工具,包括音频分割、降噪和识别功能。它通过先进技术实现对长时间录音的精确转录,广泛应用于语音识别、语音转文字等领域。
这篇文章介绍了Wenet,一个专注于长音频处理的工具,包括音频分割、降噪和识别功能。它通过先进技术实现对长时间录音的精确转录,广泛应用于语音识别、语音转文字等领域。
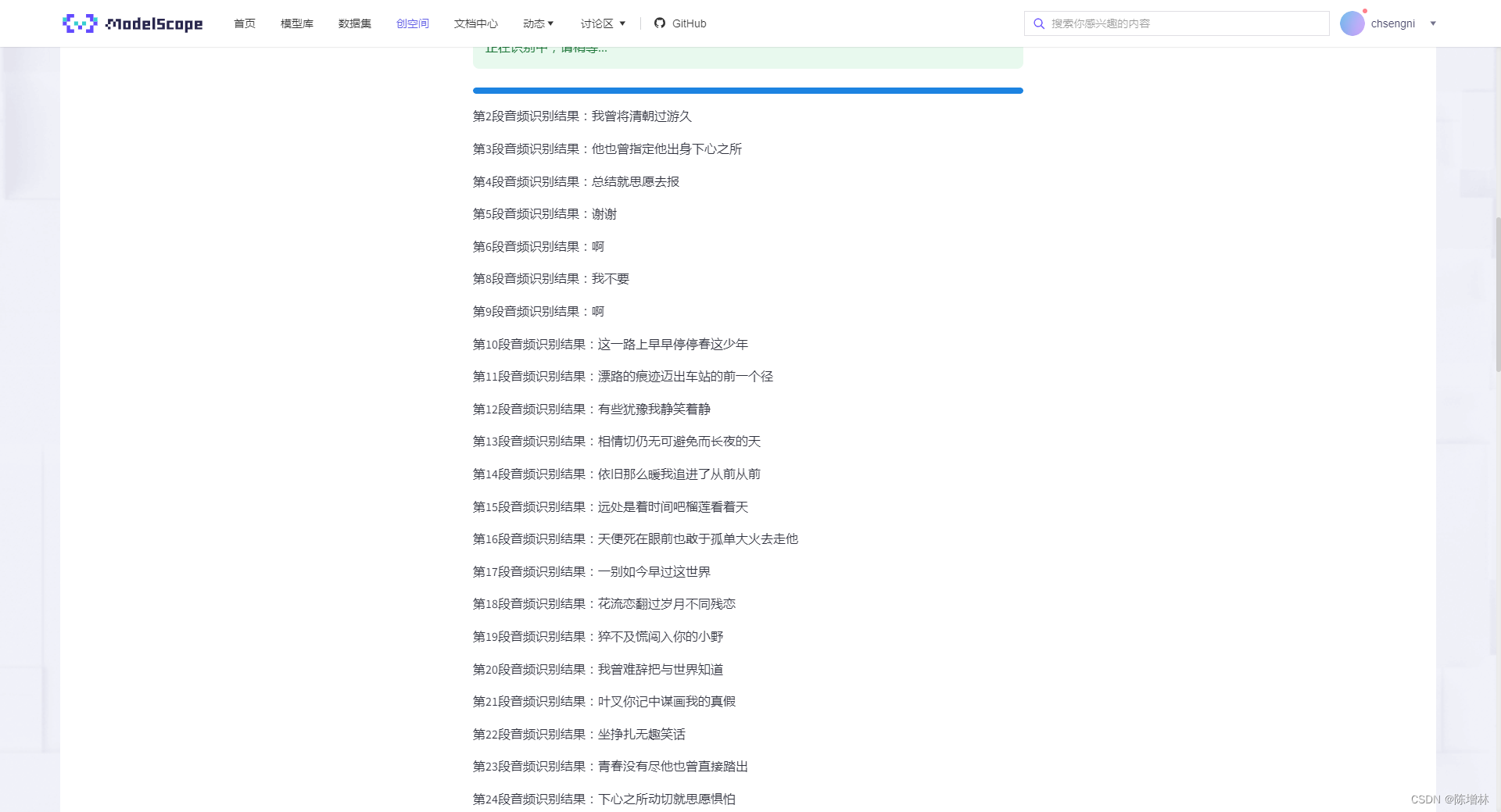
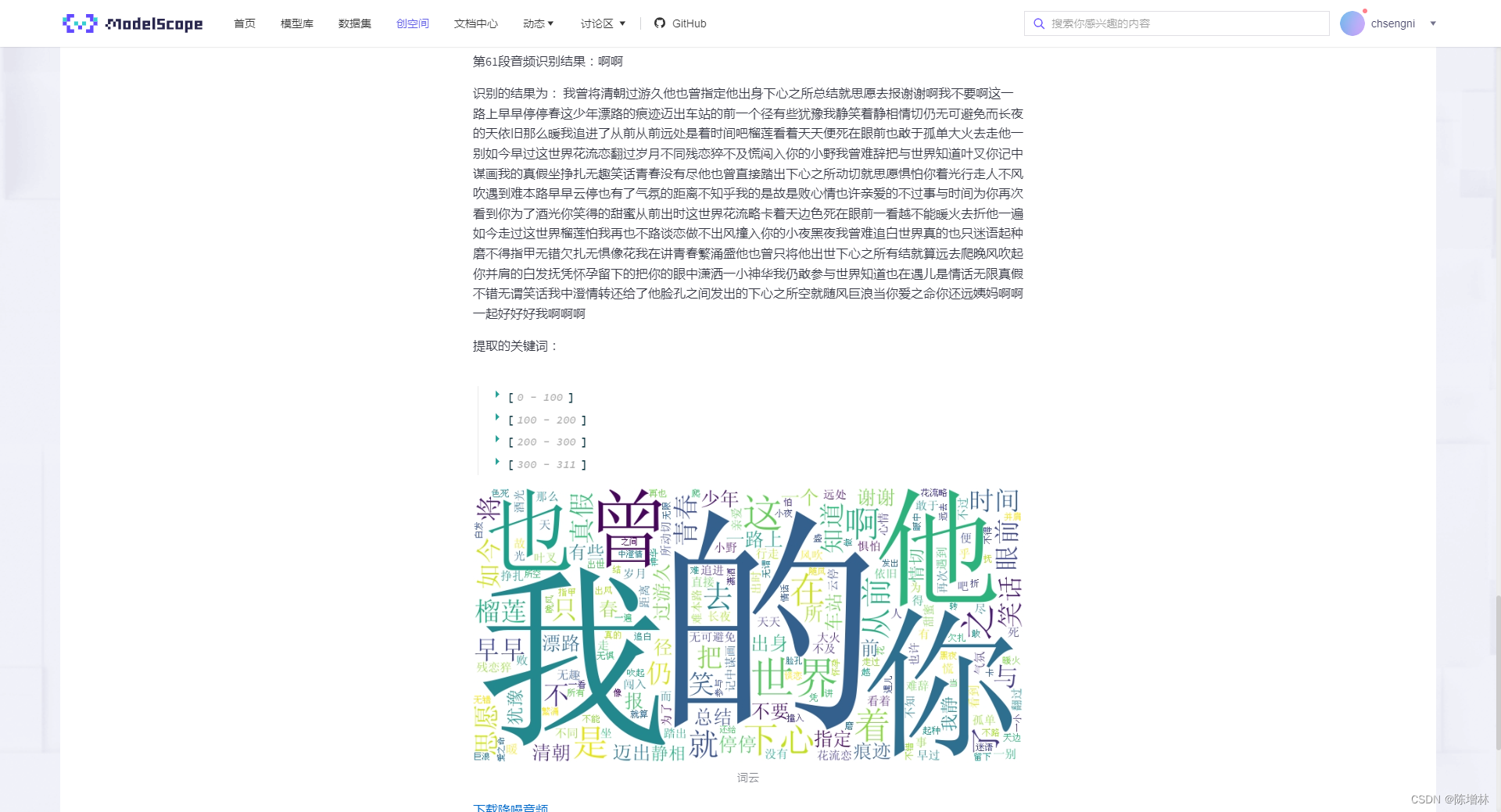
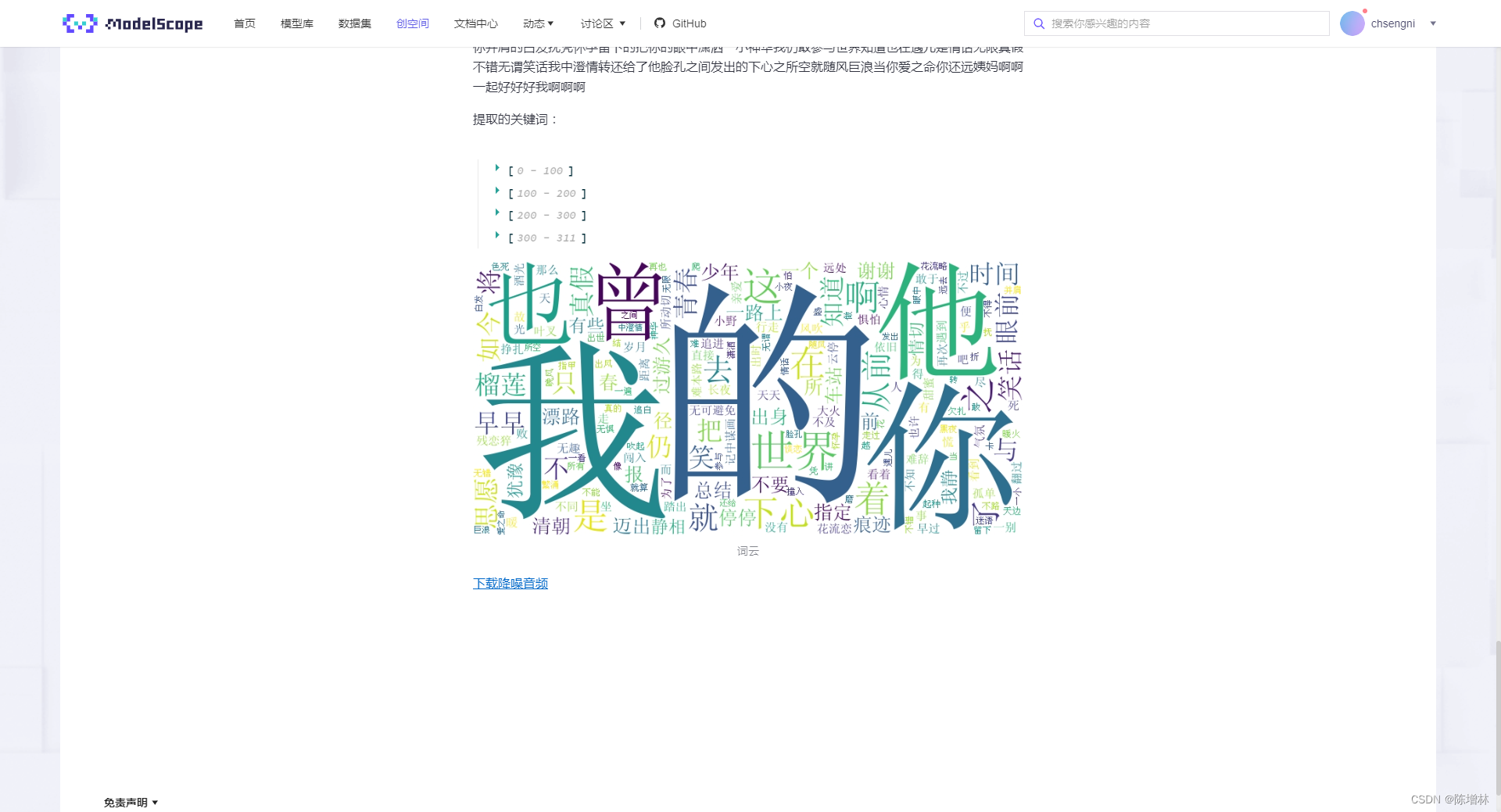
Wenet是一个流行的语音处理工具,它专注于长音频的处理,具备分割、降噪和识别功能。它的长音频分割降噪识别功能允许对长时间录制的音频进行分段处理,首先对音频进行分割,将其分解成更小的段落或语音片段。接着进行降噪处理,消除可能存在的噪音、杂音或干扰,提高语音质量和清晰度。最后,Wenet利用先进的语音识别技术对经过处理的音频段落进行识别,将其转换为文字或语音内容,从而实现对长音频内容的准确识别和转录。这种功能可以应用于许多领域,如语音识别、语音转文字、语音翻译以及音频内容分析等,为长音频数据的处理提供了高效而准确的解决方案。

支持上传(WAV、MP3、M4A、FLAC、AAC)
import streamlit as st
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from pydub import AudioSegment
from noisereduce import reduce_noise
import wenet
import base64
import os
import numpy as np
# 载入模型
chs_model = wenet.load_model('chinese')
en_model = wenet.load_model('english')
# 执行语音识别的函数
def recognition(audio, lang='CN'):
if audio is None:
return "输入错误!请上传音频文件!"
if lang == 'CN':
ans = chs_model.transcribe(audio)
elif lang == 'EN':
ans = en_model.transcribe(audio)
else:
return "错误!请选择语言!"
if ans is None:
return "错误!没有文本输出!请重试!"
txt = ans['text']
return txt
def reduce_noise_segmented(input_file,chunk_duration_ms,frame_rate):
try:
audio = AudioSegment.from_file(input_file,format=input_file.name.split(".")[-1])
# 将双声道音频转换为单声道 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1025
1025

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











