1、kafka
input {
kafka {
bootstrap_servers => "127.0.0.1:9092"
topics => ["SCHOOL_AQDL"]
group_id => "logstash-group"
consumer_threads => 3
codec => "json"
}
}
2、syslog
input {
syslog {
port => 12345
codec => cef
syslog_field => "syslog"
grok_pattern => "<%{POSINT:priority}>%{SYSLOGTIMESTAMP:timestamp} CUSTOM GROK HERE"
}
}
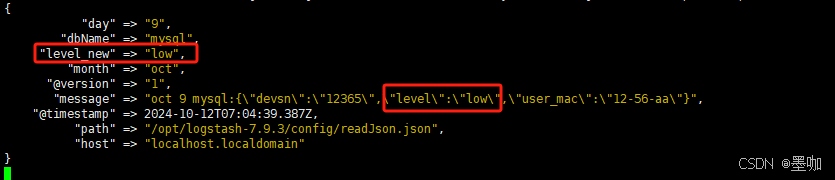
3、解析前面带key的json中指定字段值
1、原始数据:
oct 09 RADIUS:{"devsn":"12365","level":"low","user_mac":"12-56-aa"}
2、logstash解析level字段的值,并保存到level_new字段中
filter {
grok {
match => { "message" => "%{DATA:month} %{DATA:day} %{DATA:dbName}:.*?\"level\":\"%{DATA:level_new}\",.*?" }
}
}
4、# 转换@timestamp字段为时间戳,赋值给字段 [message][@timestamp]
ruby{
code => "event.set('[message][@timestamp]',(event.get('@timestamp').to_f.round(3)*1000).to_i)"
}
#将时间修改为东八区
ruby {
code => "event.set('timestamp', event.get('@timestamp').time.localtime + 8*60*60)"
}
# 格式化时间为年月日
ruby{
code => "event.set('day', (event.get('@timestamp').time.localtime + 8*60*60).strftime('%Y.%m.%d'))"
}
#转换数据类型为integer
mutate{
convert => ["time","integer"]
}
5、使用ruby正则解析content数据
mutate {
split => { "content" => "</br>" }
}
ruby {
code => '
event.get("content").each do |item|
if item.match(/^(\S+):\s*(.*)$/)
key = $1.strip
value = $2.strip
event.set(key, value)
end
end
event.remove("content")
'
}
6、使用k,v函数解析数据
# 解析 other_fields 中的键值对
kv {
source => "other_fields"
field_split => "," # 数据中两个字段之间的分隔符【name:黄大锤,add:七楼】
value_split => ":" # 数据中key和value的分隔符【name:黄大锤】
}
7、遍历删除多余的字段,保留指定字段
# 保留解析后的 name 字段,删除其他字段
ruby {
code => "
event.to_hash.each do |key, value|
if key != 'name' && key != 'message'
event.remove(key)
end
end
"
}
8、根据枚举值替换replace替换
# 根据枚举,修改为对应的值-行为类别:behaviour_type
if [behaviour_type] == "0" {
mutate {
replace => { "behaviour_type" => "违规行为" }
}
}
9、字段重命名
#重命名普通字段
mutate { rename => {"level" => "critical_level"} }
mutate { rename => ["ip", "host_ip"] }
#重命名对象嵌套字段
mutate { rename => ["[raw][user]", "host_user_name"] }
10、新增字段
# 如果s_id字段不存在,则新增字段并设置默认值
if ![s_id]{
mutate { add_field => { "[s_id]" => "" } }
}
11、使用Grok解析数据
# 原始数据
# 违规操作日志,日志内容:通过网卡连接互联网, 计算机(标识码:0100071003600010, IP:192.168.1.1, MAC:b8:b8:b8:b8:b8:b8, 网卡名:enaphyt4i0)违规连接互联网络!即将断开网络连接,审计时间:2024-02-19 16:37:13,操作用户:secadm,主机IP:192.168.1.1,主机MAC:ABB8B8,部门名称:cs,责任人:test,硬盘序列号:20240617
# grok解析语法
%{DATA:log_type},.*?计算机\((标识码:%{DATA:host_id}, .*? MAC:%{DATA:host_mac}, 网卡名:%{DATA:net_card})\).*?责任人:%{DATA:host_user_name},硬盘序列号:%{DATA:hd_code}$
【.*?】相当于通配符*,忽略中间其他内容;
【$】grok最后一个字符是占位符没有匹配到数据使用$或者\z标注行的结束。因为原数据序列号后面没有其他符号可以作为判断,所以使用$表名行的结束,这样hd_code=硬盘序列号的值
11.1、Grok获取不到最后一个字段的值
解决办法:最后一个字段后面加上$或者使用(?<add_value>.*)?解析
日志【name:黄大锤;add:七楼】
Grok解析
1、【name:%{DATA:name_value};add:%{DATA:add_value}】-解析后的add_value为空;
2、【name:%{DATA:name_value};add:%{DATA:add_value}$】-解析后的add_value为正确值(最后一个字段后面加$);
3、【name:%{DATA:name_value};add:(?<add_value>.*)?】-解析后的add_value为正确值
12、拼接字段
# 拼接 desc 字段内容,如果additional_info有值,则拼接【additional_info和action_type的值】,否则只拼接【action_type】的值
if [action_type] {
if [additional_info] {
mutate {
add_field => {
"desc" => "详细描述: %{additional_info},%{action_type}"
}
}
} else {
mutate {
add_field => {
"desc" => "详细描述: %{action_type}"
}
}
}
}

























 6656
6656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











