






 本文深入探讨Java中的字符串处理,包括字符串长度限制、常量池机制、intern方法的使用,以及不同场景下的字符串拼接策略。
本文深入探讨Java中的字符串处理,包括字符串长度限制、常量池机制、intern方法的使用,以及不同场景下的字符串拼接策略。
目录
未整理内容:大量制造String字符串导致内存溢出问题解决。
=============================================================>
Q1:String s = new String("hollis");定义了几个对象。(直面Java第025期)
Q2:如何理解String的intern方法?(直面Java第031期)
测试:
String s1 = "Hollis";
String s2 = new String("Hollis");
String s3 = new String("Hollis").intern();
System.out.println(s1 == s2);
System.out.println(s1 == s3);但是,以上代码输出结果为(base jdk1.8.0_73):
false
true
字面量和运行时常量池
JVM为了提高性能和减少内存开销,在实例化字符串常量的时候进行了一些优化。为了减少在JVM中创建的字符串的数量,字符串类维护了一个字符串常量池。
在JVM运行时区域的方法区中,有一块区域是运行时常量池,主要用来存储编译期生成的各种字面量和符号引用。
了解Class文件结构或者做过Java代码的反编译的朋友可能都知道,在java代码被javac编译之后,文件结构中是包含一部分Constant pool的。比如以下代码:
public static void main(String[] args) {
String s = "Hollis";
}经过编译后,常量池内容如下:
Constant pool:
#1 = Methodref #4.#20 // java/lang/Object."<init>":()V
#2 = String #21 // Hollis
#3 = Class #22 // StringDemo
#4 = Class #23 // java/lang/Object
...
#16 = Utf8 s
..
#21 = Utf8 Hollis
#22 = Utf8 StringDemo
#23 = Utf8 java/lang/Object上面的Class文件中的常量池中,比较重要的几个内容:
#16 = Utf8 s
#21 = Utf8 Hollis
#22 = Utf8 StringDemo上面几个常量中,s就是前面提到的符号引用,而Hollis就是前面提到的字面量。而Class文件中的常量池部分的内容,会在运行期被运行时常量池加载进去。关于字面量,详情参考Java SE Specifications
说完了编译期的事儿了,该到运行期了,在运行期,new String("Hollis");执行到的时候,是要在Java堆中创建一个字符串对象的,而这个对象所对应的字符串字面量是保存在字符串常量池中的。但是,String s = new String("Hollis");,对象的符号引用s是保存在Java虚拟机栈上的,他保存的是堆中刚刚创建出来的的字符串对象的引用。
所以,你也就知道以下代码输出结果为false的原因了。
String s1 = new String("Hollis");
String s2 = new String("Hollis");
System.out.println(s1 == s2);因为,==比较的是s1和s2在堆中创建的对象的地址,当然不同了。但是如果使用equals,那么比较的就是字面量的内容了,那就会得到true。
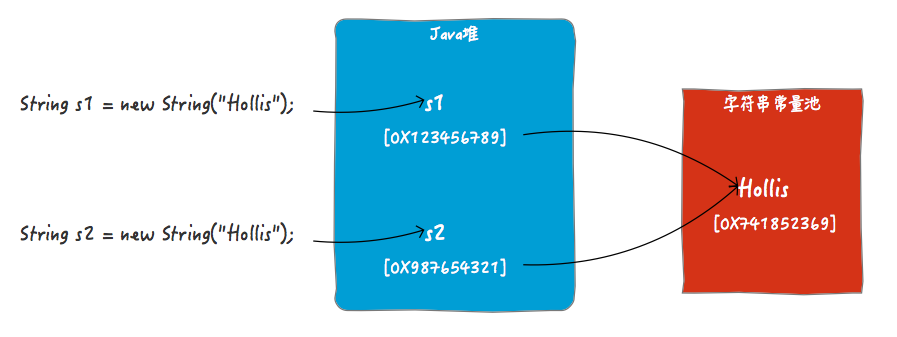
在不同版本的JDK中,Java堆和字符串常量池之间的关系也是不同的,这里为了方便表述,就画成两个独立的物理区域了。具体情况请参考Java虚拟机规范。
所以,String s = new String("Hollis");创建几个对象的答案你也就清楚了。
常量池中的“对象”是在编译期就确定好了的,在类被加载的时候创建的,如果类加载时,该字符串常量在常量池中已经有了,那这一步就省略了。堆中的对象是在运行期才确定的,在代码执行到new的时候创建的。
运行时常量池的动态扩展
编译期生成的各种字面量和符号引用是运行时常量池中比较重要的一部分来源,但是并不是全部。那么还有一种情况,可以在运行期像运行时常量池中增加常量。那就是String的intern方法。
当一个String实例调用intern()方法时,Java查找常量池中是否有相同Unicode的字符串常量,如果有,则返回其的引用,如果没有,则在常量池中增加一个Unicode等于str的字符串并返回它的引用;
intern()有两个作用,第一个是将字符串字面量放入常量池(如果池没有的话),第二个是返回这个常量的引用。
我们再来看下开头的那个让人产生疑惑的例子:
String s1 = "Hollis";
String s2 = new String("Hollis");
String s3 = new String("Hollis").intern();
System.out.println(s1 == s2);
System.out.println(s1 == s3);你可以简单的理解为String s1 = "Hollis";和String s3 = new String("Hollis").intern();做的事情是一样的(但实际有些区别,这里暂不展开)。都是定义一个字符串对象,然后将其字符串字面量保存在常量池中,并把这个字面量的引用返回给定义好的对象引用。
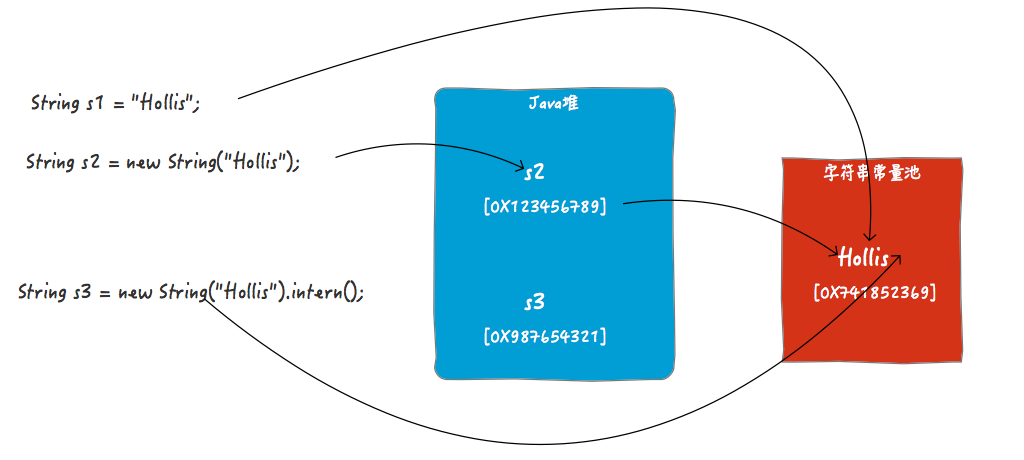
对于String s3 = new String("Hollis").intern();,在不调用intern情况,s3指向的是JVM在堆中创建的那个对象的引用的(如图中的s2)。但是当执行了intern方法时,s3将指向字符串常量池中的那个字符串常量。
由于s1和s3都是字符串常量池中的字面量的引用,所以s1==s3。但是,s2的引用是堆中的对象,所以s2!=s1。
在解释这个之前,我们先来看下以下代码:
String s1 = "Hollis";
String s2 = "Chuang";
String s3 = s1 + s2;
String s4 = "Hollis" + "Chuang";在经过反编译后,得到代码如下:
String s1 = "Hollis";
String s2 = "Chuang";
String s3 = (new StringBuilder()).append(s1).append(s2).toString();
String s4 = "HollisChuang";可以发现,同样是字符串拼接,s3和s4在经过编译器编译后的实现方式并不一样。s3被转化成StringBuilder及append,而s4被直接拼接成新的字符串。
如果你感兴趣,你还能发现,String s3 = s1 + s2; 经过编译之后,常量池中是有两个字符串常量的分别是 Hollis、Chuang(其实Hollis和Chuang是String s1 = "Hollis";和String s2 = "Chuang";定义出来的),拼接结果HollisChuang并不在常量池中。
如果代码只有String s4 = "Hollis" + "Chuang";,那么常量池中将只有HollisChuang而没有”Hollis” 和 “Chuang”。
究其原因,是因为常量池要保存的是已确定的字面量值。也就是说,对于字符串的拼接,纯字面量和字面量的拼接,会把拼接结果作为常量保存到字符串池。
如果在字符串拼接中,有一个参数是非字面量,而是一个变量的话,整个拼接操作会被编译成StringBuilder.append,这种情况编译器是无法知道其确定值的。只有在运行期才能确定。
那么,有了这个特性了,intern就有用武之地了。那就是很多时候,我们在程序中得到的字符串是只有在运行期才能确定的,在编译期是无法确定的,那么也就没办法在编译期被加入到常量池中。
这时候,对于那种可能经常使用的字符串,使用intern进行定义,每次JVM运行到这段代码的时候,就会直接把常量池中该字面值的引用返回,这样就可以减少大量字符串对象的创建了。
而intern中说的“如果有的话就直接返回其引用”,指的是会把字面量对象的引用直接返回给定义的对象。
这个过程是不会在Java堆中再创建一个String对象的。
String s = new String("Hollis").intern();以上代码的写法其实是使用intern是没什么意义的。因为字面量Hollis会作为编译期常量被加载到运行时常量池。
==================================================================================>
原文:我说我精通字符串,面试官竟然问我Java中的String有没有长度限制!?
https://www.hollischuang.com/archives/3916
原文:Java 8中字符串拼接新姿势:StringJoiner
https://www.hollischuang.com/archives/3283
public String(char value[], int offset, int count)的定义,count是int类型的,
所以,char value[]中最多可以保存Integer.MAX_VALUE个,即2147483647字符。(jdk1.8.0_73)
(记得数据库的时间戳类型底层也是Integer最大值,因此不能超过2038年)
实际测试:
String s = “”;中,最多可以有65534个字符。如果超过这个个数。就会在编译期报错
当我们使用字符串字面量直接定义String的时候,是会把字符串在常量池中存储一份的。那么上面提到的65534其实是常量池的限制。
常量池中的每一种数据项也有自己的类型。Java中的UTF-8编码的Unicode字符串在常量池中以CONSTANT_Utf8类型表示。
u2是无符号的16位整数,因此理论上允许的的最大长度是2^16=65536。而 java class 文件是使用一种变体UTF-8格式来存放字符的,null 值使用两个 字节来表示,因此只剩下 65536- 2 = 65534个字节。
也就是说,在Java中,所有需要保存在常量池中的数据,长度最大不能超过65535,这当然也包括字符串的定义咯。
运行期间:
结果如下3.9GB
2^31-1 =2147483647 个 16-bit Unicodecharacter
2147483647 * 16 = 34359738352 位
34359738352 / 8 = 4294967294 (Byte)
4294967294 / 1024 = 4194303.998046875 (KB)
4194303.998046875 / 1024 = 4095.9999980926513671875 (MB)
4095.9999980926513671875 / 1024 = 3.99999999813735485076904296875 (GB)
Java 8中字符串拼接:StringJoiner
StringBuilder builder = new StringBuilder();
if (!list.isEmpty()) {
builder.append(list.get(0));
for (int i = 1, n = list.size(); i < n; i++) {
builder.append(",").append(list.get(i));
}
}
builder.toString();粗略方式2:
list.stream().reduce(new StringBuilder(), (sb, s) -> sb.append(s).append(','), StringBuilder::append).toString();但是输出结果稍有些不同,需要进行二次处理:
Hollis,hollischuang,Java干货,还可以使用”+”进行拼接:
list.stream().reduce((a,b)->a + "," + b).toString();以上几种方式,要么是代码复杂,要么是性能不高,或者无法直接得到想要的结果。
为了满足类似这样的需求,Java 8中提供的StringJoiner就派上用场了。以上需求只需要一行代码:
list.stream().collect(Collectors.joining(":"))如果日常开发中中,需要进行字符串拼接,如何选择?
1、如果只是简单的字符串拼接,考虑直接使用”+”即可。
2、如果是在for循环中进行字符串拼接,考虑使用StringBuilder和StringBuffer。
3、如果是通过一个List进行字符串拼接,则考虑使用StringJoiner。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









