




 本文介绍Python Django中的分页实现方法,包括后端逻辑与前端展示代码,并通过Ajax实现局部页面刷新,提升用户体验。
本文介绍Python Django中的分页实现方法,包括后端逻辑与前端展示代码,并通过Ajax实现局部页面刷新,提升用户体验。
今日语:积少成多,积水成渊
一、分页代码,我想不管在什么网站上都避免不了分页,那我就简单介绍一下python中的分页代码吧~~
1.先看后台的代码:(在apps的views中实现)
from django.core.paginator import Paginator, PageNotAnInteger, EmptyPage
# 用GET方式请求页面
pagenum = request.GET.get('pagenum', 1)
#括号中的“2”指的是一页放几块内容
pa = Paginator(all_courses, 2)
#用try...except捕获翻页时出现的一些错误,包括小数页
try:
page_list = pa.page(pagenum)
except PageNotAnInteger:
page_list = pa.page(1)
# 捕获最后一页
except EmptyPage:
page_list = pa.page(pa.num_pages)2.接下来看前端页面的分页代码~~
<div class="pageturn">
<ul class="pagelist">
{% if page_list.has_previous %}
<li class="long"><a href="?pagenum={{ page_list.previous_page_number }}&sort={{ sort_type }}">上一页</a>
</li>
{% else %}
<li class="long"><a href="?pagenum=1&sort={{ sort_type }}">上一页</a></li>
{% endif %}
{% for num in page_list.paginator.page_range %}
<li {% if num == page_list.number %}class="active"{% endif %}><a href="?pagenum={{ num }}&sort={{ sort_type }}">{{ num }}</a></li>
{% endfor %}
{% if page_list.has_next %}
<li class="long"><a
href="?pagenum={{ page_list.next_page_number }}&sort={{ sort_type }}">下一页</a>
</li>
{% else %}
<li class="long"><a
href="?pagenum={{ page_list.paginator.num_pages }}&sort={{ sort_type }}">下一页</a>
</li>
{% endif %}
</ul>
</div>总结一下:此分页器做的是简单的少数分页,并不是我们在大网站上见到的那样中间有省略号的;效果如下:(感觉这样看起来还事蛮不错的呢~)

3.使用scrapy框架,将爬取出的数据存入数据库中(mongodb)
配置思路
1、不遵循爬虫协议;
2、配置mongo相关配置;
3、禁用cookie;
4、配置浏览器身份;a.首先要配置settings.py
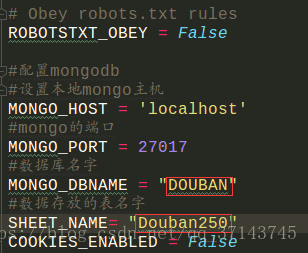

b.pipelines.py
配置思路
1)在init方法中得到mongo配置信息
2)根据配置信息创建数据库和表,并且连接
3)在process_item插入数据,插入前转成字典(dict),并且一定要注意返回item,否则级别低的管道建会没有数据

import pymongo
from pymongo import MongoClient
from scrapy.conf import settings
from DouBan.settings import MONGO_HOST
from DouBan.settings import MONGO_PORT
from DouBan.settings import MONGO_DBNAME
from DouBan.settings import SHEET_NAME
class DoubanMongodbPipeline(object):
def __init__(self):
print("DoubanMongodbPipeline.__init__----")
host = settings["MONGO_HOST"]
port = settings["MONGO_PORT"]
dbname = settings["MONGO_DBNAME"]
sheetname = settings["SHEET_NAME"]
print("host===",host)
print("port===", port)
print("dbname===", dbname)
print("sheetname===", sheetname)
#创建客户端
client = pymongo.MongoClient(host=host,port=port)
#得到或者创建数据库对象
mydb = client[dbname]
#得到或者创建表
self.post = mydb[sheetname]
def process_item(self,item,spider):
dict_item = dict(item)
#往mongodb里面插入数据
self.post.insert(dict_item)
return item
def close_spider(self,spider):
print("DoubanMongodbPipeline.close_spider-----")
效果:
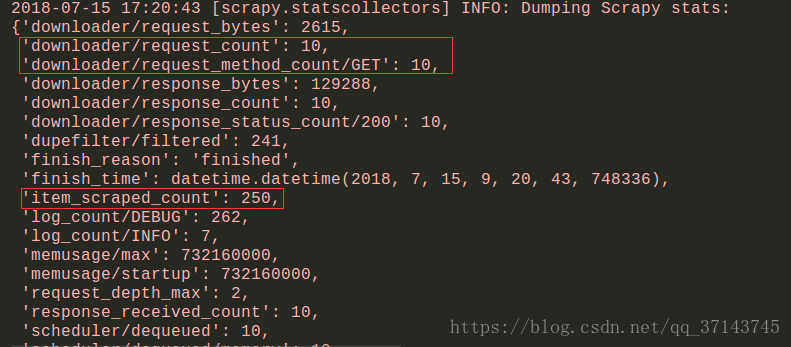
查看mongodb数据首先启动MongoDB数据库需要两个命令:
mongod:是mongoDB数据库进程本身
mongo:是命令行shell客户端
sudo mongod 首先启动数据库服务,再执行Scrapy
sudo mongo 启动数据库shell
在mongo shell下使用命令:
查看当前数据库
db
列出所有的数据库
show dbs
连接douban数据库
use douban
列出所有表
show collections
查看表里的数据
db.Douban250.find()
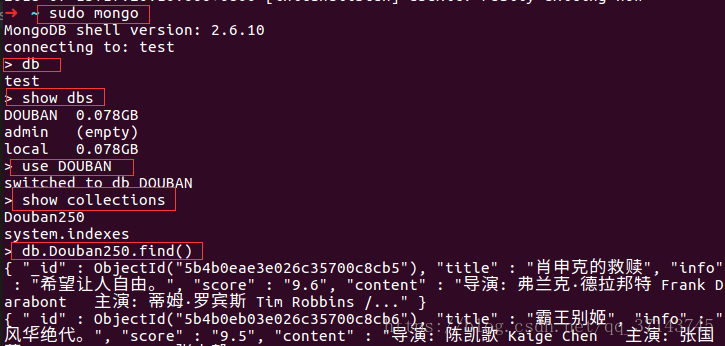
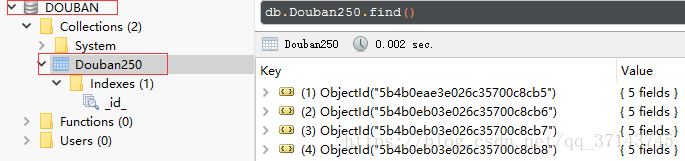
接下来查看数据库:
二、浅谈一下AJAX,首先介绍一下它的作用。
1.页面只会局部刷新,在页面内与服务器异步通信,给用户以更好的体验
2.Ajax的工作原理相当于在用户和服务器之间加了—个中间层(AJAX引擎),使用户操作与服务器响应异步化。并不是所有的用户请求都提交给服务器,像—些数据验证和数据处理等都交给Ajax引擎自己来做, 只有确定需要从服务器读取新数据时再由Ajax引擎代为向服务器提交请求。
3.具有更加迅速的响应能力,因为它使用异步的方式与服务器通信,不需要打断用户。
{% block myjs %}
<script>
$(function () {
$('#jsRightBtn').click(function () {
{#val:表单类元素值#}
var loveid = {{ teacher.orginfo.id }};
var lovetype = $(this).attr('data-fav-type');
$.ajax({
type: 'GET',
url: '{% url 'operations:user_love' %}',
data: {
'loveid': loveid,
'lovetype': lovetype
},
success: function (callback) {
if (callback.status == 'ok') {
$('#jsRightBtn').text(callback.msg);
} else {
alert(callback.msg)
}
}
})
});
$('#jsLeftBtn').click(function () {
{#val:表单类元素值#}
var loveid = {{ teacher.id }};
var lovetype = $(this).attr('data-fav-type');
$.ajax({
type: 'GET',
url: '{% url 'operations:user_love' %}',
data: {
'loveid': loveid,
'lovetype': lovetype
},
success: function (callback) {
if (callback.status == 'ok') {
$('#jsLeftBtn').text(callback.msg);
} else {
alert(callback.msg)
}
}
})
});
})
</script>
{% endblock %}三.前后端分离类目和图片不显示的原因:(除了跨域的错误)
1.此图之前是配置分页的时候写的,如果想显示美丽的界面和类目,就需要注释掉,因为这是全局的,会影响数据显示。
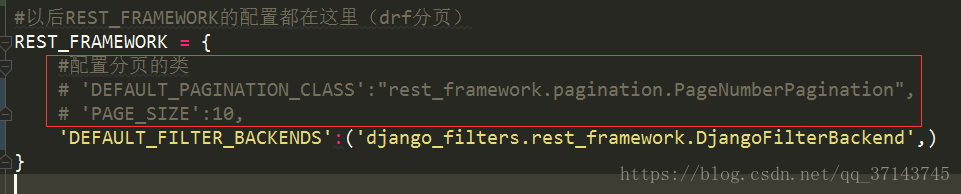
2.跨域问题:settings中的配置:



之后前后端运行起来,刷新,就有好看的界面喽~

注意:大坑,一定要注意!

















 398
398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









