






什么是SolrCloud
SolrCloud(solr 云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时使用 SolrCloud。当一个系统的索引数据量少的时候是不需要使用SolrCloud的,当索引量很大,搜索请求并发很高,这时需要使用SolrCloud来满足这些需求。
SolrCloud是基于Solr和Zookeeper的分布式搜索方案,它的主要思想是使用Zookeeper作为集群的配置信息中心。
它有几个特色功能:
1)集中式的配置信息
2)自动容错
3)近实时搜索
4)查询时自动负载均衡
Solr集群的系统架构:
1. 物理结构
三个Solr实例,组成一个SolrCloud。
2. 逻辑结构
索引集合包括两个Shard(shard1和shard2),shard1和shard2分别由三个Core组成,其中一个Leader两个Replication,Leader是由zookeeper选举产生,zookeeper控制每个shard上三个Core的索引数据一致,解决高可用问题。
用户发起索引请求分别从shard1和shard2上获取,解决高并发问题。
collection:
Collection在SolrCloud集群中是一个逻辑意义上的完整的索引结构。它常常被划分为一个或多个Shard(分片),它们使用相同的配置信息。
比如:针对商品信息搜索可以创建一个collection。
collection=shard1+shard2+....+shardX
Core:
每个Core是Solr中一个独立运行单位,提供 索引和搜索服务。一个shard需要由一个Core或多个Core组成。由于collection由多个shard组成所以collection一般由多个core组成。
Master或Slave
Master是master-slave结构中的主结点(通常说主服务器),Slave是master-slave结构中的从结点(通常说从服务器或备服务器)。同一个Shard下master和slave存储的数据是一致的,这是为了达到高可用目的。
Shard:
Collection的逻辑分片。每个Shard被化成一个或者多个replication,通过选举确定哪个是Leader。
需要实现的solr集群架构

注意:
在搭建solr集群前,建议最好有一个solr服务是已经搭建好的,并且有zookeeper集群(三台),可以简化大量重复的配置操作,省去了很大一部分时间。
实际搭建分布式:
搭建solr集群需要7台服务器。
搭建伪分布式:
需要三个zookeeper节点
需要四个tomcat节点。
建议虚拟机的内存1G以上。
1.创建四个tomcat实例。并且每个端口号都不相同:8180、8280、8380、8480
tomcat安装步骤:https://blog.youkuaiyun.com/qq_37138756/article/details/80887005
zookeeper集群安装:https://blog.youkuaiyun.com/qq_37138756/article/details/80852908
linux下单机版solr安装:https://blog.youkuaiyun.com/qq_37138756/article/details/80888141
进入到解压好的文件目录(这个tomcat目录中,有我的solr实例,是配置solr服务使用到的tomcat)

复制tomcat到之前搭建zookeeper集群时,创建的/usr/local/solrcloud目录里,复制4个tomcat
cp -r apache-tomcat-8.0.52/ /usr/local/solrcloud/tomcat_01
进入solrcloud目录查看
cd /usr/local/solrcloud/
修改每个tomcat目录下的conf里的server.xml文件,修改每个tomcat的端口号,保证每个端口都不想同,相互不冲突
vi tomcat_01/conf/server.xml
用/port命令搜索port字符串,按n搜索下一个,一共有三个地方需要更改



按Esc健,输入:wq!按Enter健,保存并退出。
其他三个tomcat按照顺序依次修改:
vi tomcat_02/conf/server.xml tomcat_02:8025, 8280, 8029
vi tomcat_03/conf/server.xml tomcat_03:8035, 8380, 8039
vi tomcat_04/conf/server.xml tomcat_04:8045, 8480, 8049
注意:四个tomcat中的server.xml文件一定都要修改,每个文件修改三个地方,每个端口号都要相互不冲突
2.把单机版的solr工程复制到集群中的tomcat中
搭建好的单机solr服务里,进入到tomcat/webapps文件中将solr复制到第一步的四个tomcat/webapps中,因为我复制的tomcat中就配置了solr服务,所以这里我就不复制,不实时操作了,大概描述一下方法。
例:
进入到solr单机版的tomcat中,进入到webapps文件中,输入以下命令进入到目录:
cd usr/tomcat-8.0.25/apache-tomcat-8.0.52/webapps/输入以下命令进行复制到solrcloud下四个tomcat/webapps目录下(每个tomcat都要复制)
cp -r solr/ /usr/local/solrcloud/tomcat_01/webapps/cp -r solr/ /usr/local/solrcloud/tomcat_02/webapps/cp -r solr/ /usr/local/solrcloud/tomcat_03/webapps/cp -r solr/ /usr/local/solrcloud/tomcat_04/webapps/
3.为每个solr实例创建对应的solrhome。
在之前搭建的单机solr服务中,将当时配置的solrhome目录,复制到solrcloud中,复制成四份。

进入到solrcloud目录中,查看现在的目录
cd usr/local/solrcloud/
4.配置solrCloud相关的配置。将每个solrhome下的solr.xml文件中的ip及端口号配置好
在搭建单机版solr服务的时候,没有配置过solrhome里的文件。在搭建集群的时候,需要修改配置信息。
输入以下命令进行编辑:
vi solrhome_01/solr.xml 
进入之后点击i进行编辑

第一个修改的是改成自己本机linux的地址;
第二个是修改成刚才配置的tomcat端口号,solrhome_01和tomcat_01对应,tomcat_01在server.xml中配置的端口号是8180。
配置完成是这样:

修改以后:wq!保存并退出。
其他三个solrhome中的solr.xml中也需要修改,可以对比这上面的进行修改。ip地址都是一样的,端口号分别是solrhome_01对应8180, solrhome_02对应8280, solrhome_03对应8380, solrhome_04对应8480
vi solrhome_02/solr.xml
vi solrhome_03/solr.xml
vi solrhome_04/solr.xml 5.修改tomcat中solr服务的web.xml文件,将solrhome文件关联起来。
修改web.xml文件和单机版配置是一样的:
vi tomcat_01/webapps/solr/WEB-INF/web.xml 
这是当时单机版配置的路径:

现在修改成集群中的solrcloud/solrhome_01路径:
/usr/local/solrcloud/solrhome_01

修改完成,保存并退出。
其他三个tomcat里的web.xml也要对应这改:
vi tomcat_02/webapps/solr/WEB-INF/web.xml /usr/local/solrcloud/solrhome_02
vi tomcat_03/webapps/solr/WEB-INF/web.xml/usr/local/solrcloud/solrhome_03
vi tomcat_04/webapps/solr/WEB-INF/web.xml/usr/local/solrcloud/solrhome_04
6.让zookeeper统一管理配置文件
现在我们每一个solr都有了自己的solrhome,现在我们要让每一个solr实例的配置文件都一样,这个配置文件需要集中管理,这个时候我们使用zookeeper来统一管理配置文件。所以要将配置文件上传到zookeeper中。那么上传哪些配置文件呢?
这里需要注意下,好像是从5.0版本开始不使用schema.xml,使用的文件名是managed-schema,其实内容都一样,搞不懂为啥要换个名字,而且内容格式是xml,但是文件名却没有.xml的后辍,这里直接上传整个conf目录就行。

知道了要上传什么,那么怎么上传呢?打开最早solr解压出来的原始文件(如果删了那就重新上传解压吧)

在/solr-5.0.0/server/scripts/cloud-scripts/的目录下有个脚本文件,执行这个脚本就可以将配置文件上传到zookeeper了

注意:在执行脚本上传配置文件前,必须先去启动zookeeper集群
进入到集群目录:
cd /usr/local/solrcloud/
通过批量脚本来启动zookeeper集群:
./start-zookeeper-all.sh 
启动完成以后,去执行脚本:
cd /usr/solr-5.0.0/solr-5.0.0/server/scripts/cloud-scripts/
脚本的执行命令(参数比较多,建议复制出来改好后再粘贴上去):
./zkcli.sh -zkhost 127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183 -cmd upconfig -confdir /usr/local/solrcloud/solrhome_01/configsets/sample_techproducts_configs/conf -confname myconf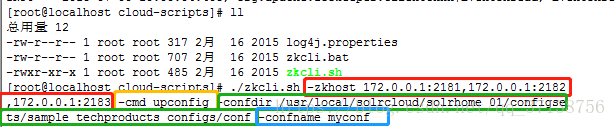
红色框代表zookeeper集群的ip和端口号列表(搭建zookeeper集群的时候配置过的)

黄色框代表要执行的是上传配置文件操作
绿色框代表的是要上传的配置文件目录(低版本不太一样,具体以那两个主要的配置文件所在目录为准,不知到在哪就find命令搜吧)

蓝色框代表的是你给上传的配置起的名字,可以随意修改
上传完成以后,我们需要查看一下是否上传成功。去zookeeper集群的一个目录找到bin里zookeeper的客户端脚本
cd /usr/local/solrcloud/zookeeper1/bin/ 
运行后会出现一大堆内容,如果不指定参数默认会访问localhost:2181
./zkCli.sh 
然后在最下面执行下面这个命令,查看在根目录下有什么
ls /
有两个文件夹一个configs,有个zookeeper,进入到configs中看看有什么
ls /configs

这就是我们刚才上传的配置了,名字是一样的,说明上传成功了
然后用quit命令退出

如果需要修改配置的话,只需要在solrhome_01/configsets/sample_techproducts_configs/conf目录里修改,改好后再上传一次就行了,就会覆盖原来的配置文件
7.关联solr和zookeeper,修改tomcat/bin目录下的catalina.sh 文件
现在配置文件已经上传好了,可是solr和zookeeper还没有建立任何关系,这个时候需要修改4个tomcat的配置文件。
进入到集合目录:
cd /usr/local/solrcloud/
修改tomcat_01/bin/目录下catalina.sh文件:
vi tomcat_01/bin/catalina.sh
用/JAVA_OPTS搜索,N是下一个(因为低版本加的位置长的不太一样,但这句话的例子是不变的)

找到这一行以后,在这行的下面添加下面的内容:
JAVA_OPTS="-DzkHost=127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183"
保存并退出。
其他三个tomcat也需要修改位置和内容是一样的,不用变
vi tomcat_02/bin/catalina.sh
vi tomcat_03/bin/catalina.sh
vi tomcat_04/bin/catalina.sh全部添加完成以后,这样每个solr实例就通过这个参数和zookeeper集群建立了联系,solr会将自己的状态发送给zookeeper,比如ip地址,端口号等,zookeeper就可以连接到solr了,建立了通信关系。
8.启动tomcat
现在需要启动每个tomcat,在启动之前要保证zookeeper集群是启动状态。
为了避免每次启动的时候都需要进去文件夹一个一个的启动,这里为了方便,可以写一个批量脚本
在集群目录下,通过输入以下命令来进行编辑一个脚本:
vi start-tomcat-all.sh
脚本中填写以下内容:
/usr/local/solrcloud/tomcat_01/bin/startup.sh
/usr/local/solrcloud/tomcat_02/bin/startup.sh
/usr/local/solrcloud/tomcat_03/bin/startup.sh
/usr/local/solrcloud/tomcat_04/bin/startup.sh 
保存并退出。

这时候还没有运行权限,需要添加运行权限。
chmod u+x start-tomcat-all.sh 
然后运行tomcat批量启动脚本。
./start-tomcat-all.sh 
如果你想看启动起来了没,可以去看看tomcat的日志信息(相当于看控制台打印信息),可以通过以下命令查看:
tail -f /usr/local/solrcloud/tomcat_01/logs/catalina.out

在搭建集群的时候看见网上有的说,从tomcat8开始,默认启动的是NIO模式,7默认启动的是BIO模式,还可以通过配置设置APR模式启动,至于APR,NIO和BIO的区别,是和tomcat并发性能有关的,高并发的系统应该将tomcat的模式设置成APR模式,会大幅度的提高服务器的处理和响应性能。感兴趣的可以自己百度下。
9.访问集群
在Windows端使用浏览器访问solr集群服务器,配置集群的时候使用的端口号是8180,8280,8380,8480,这几个端口都可以访问到。
访问地址为:linux ip地址:8180/solr

单机版是没有Cloud选项的,因为还没有创建collections,所以现在里面什么也没有:

10.创建Collection进行分片处理
低版本的只能通过命令进行分片,相比于比较麻烦,通过以下命令进行分片:
http://192.168.254.128:8180/solr/admin/collections?action=CREATE&name=collection2&numShards=2&replicationFactor=2

分片成功以后再去查看,每一片都是一主一备 :

删除集群命令:
http://192.168.254.128:8180/solr/admin/collections?action=DELETE&name=collection2高版本的solr,根据Collection按钮进行分片处理:

名字可以随意起,例:mycollection1,用自己上传的myconf配置文件,有2片shard,每个shard有2个备份节点一主一备

然后回去看下,这样solr集群就搭建成功了。

删除不用的Collection或core
删除collection,点这里,然后输入你要删除的collection名称就行

删除core在右边,完了如果要添加下面有add replica(如果工作中你的哪个备份机挂了,就这样删掉挂的服务器,再添加一个好的就行了,在添加之前,肯定是需要在服务器上部署好solr服务,然后连接zookeeper集群才行的)

java中使用solrj管理solr集群:
使用步骤:
第一步:把solrJ相关的jar包添加到工程中。
第二步:创建一个SolrServer对象,需要使用CloudSolrServer子类。构造方法的参数是zookeeper的地址列表。
第三步:需要设置DefaultCollection属性。
第四步:创建一SolrInputDocument对象。
第五步:向文档对象中添加域
第六步:把文档对象写入索引库。
第七步:提交。

查询文档的使用:
创建一个CloudSolrServer对象,其他处理和单机版一致。
bean注入solr集群
<!-- 单击版solrJ -->
<bean id="httpSolrServer" class="org.apache.solr.client.solrj.impl.HttpSolrServer">
<constructor-arg index="0" value="http://localhost:8085/solr/core"/>
</bean>
<!-- 集群版solr服务 -->
<bean id="cloudSolrServer" class="org.apache.solr.client.solrj.impl.CloudSolrServer">
<constructor-arg name="zkHost" value="127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183"></constructor-arg>
<property name="defaultCollection" value="collection2"></property>
</bean>

















 546
546

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









