




 本文探讨了一种视觉关系理解模型,强调了物体识别在关系识别中的基础作用。模型包括视觉和语义两个模块,使用预训练的词嵌入、关系共现嵌入和Node2vec方法。通过triplet损失函数和softmax的变体改进,优化嵌入向量的区分性和相似性。实验表明,triplet-softmax损失函数在模型中起关键作用。
本文探讨了一种视觉关系理解模型,强调了物体识别在关系识别中的基础作用。模型包括视觉和语义两个模块,使用预训练的词嵌入、关系共现嵌入和Node2vec方法。通过triplet损失函数和softmax的变体改进,优化嵌入向量的区分性和相似性。实验表明,triplet-softmax损失函数在模型中起关键作用。
Large-Scale Visual Relationship Understanding (AAAI 2019)
文章
本文的模型分为两部分:视觉模块和语义模块。
对于视觉模块,作者认为关系的存在依赖于主语和宾语物体的存在,但反过来并不是,换句话说就是关系识别是建立在物体识别之上的,但物体识别却是独立于关系识别的。因此,作者希望能学习从物体和关系共享的视觉特征特征空间到两个独立的语义嵌入空间(物体和关系)的映射。为了避免混淆两个空间,所以我们看到在本文的模型中,并没有将关系的视觉特征传递给物体(仅将物体特征传递给了关系)。其实这个在之前港中文的一篇文章中也有类似的做法。特征提取模块中的w_1和w_2分别是VGG-16中的fc6和fc7,这样才能保持住VGG16的capacity,并且主语和宾语的部分是共享相同的w_1和w_2的。此外,和之前大多数工作不一样,本文的模型没有将spatial特征和visual特征拼接起来,因为由于物体和类别的规模太大,关系的几何布局具有非常大的变化性。
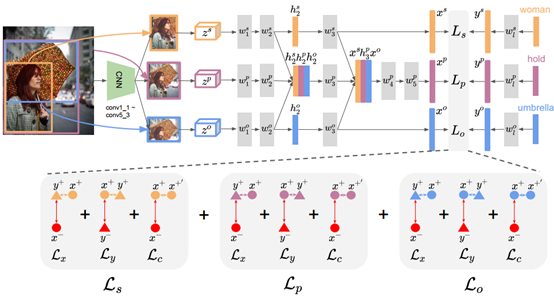
对于语义模块,将主语、宾语和关系标签的词向量输入一个1至2个fc的小MLP,然后得到每个embedding。和视觉模块类似,主语和宾语分支会共享权重而关系分支则是独立的。这个模块希望能够将词向量映射到一个比原始词向量空间更具判别性却保持了语义相似性的嵌入空间。对词向量的初始化有很多方法,本文讨论了以下几种:
-
预训练好的word2vec词嵌入向量(wiki),本文用这个作为一个baseline
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1353
1353

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









