




 本文介绍了Python中实现经典hex-dump函数的方法,详细解析了代码功能,包括3列展示:偏移量、16进制字节和ASCII值。同时,讨论了Python3的字符编码概念,区分了str和bytes类型,并介绍了格式化打印技巧,包括在Python2和Python3中的差异。最后,提到了字符编码问题的解决方案和相关测试。
本文介绍了Python中实现经典hex-dump函数的方法,详细解析了代码功能,包括3列展示:偏移量、16进制字节和ASCII值。同时,讨论了Python3的字符编码概念,区分了str和bytes类型,并介绍了格式化打印技巧,包括在Python2和Python3中的差异。最后,提到了字符编码问题的解决方案和相关测试。
作者在实现 TCP 代理脚本的时候,提到一个 hex-dump 的函数。非常经典的一段代码,看上去很美。
hex-dumper
Pyton2 代码:
def hexdump(src, length=16):
result = []
digits = 4 if isinstance(src, unicode) else 2
for i in xrange(0, len(src), length):
s = src[i:i+length]
hexa = b' '.join(["%0*X" % (digits, ord(x)) for x in s])
text = b''.join([x if 0x20 <= ord(x) < 0x7F else b'.' for x in s])
result.append( b"%04X %-*s %s" % (i, length*(digits + 1), hexa, text) )
print b'\n'.join(result)或者:
FILTER=''.join([(len(repr(chr(x)))==3) and chr(x) or '.' for x in range(256)])
def dump(src, length=8):
N=0; result=''
while src:
s,src = src[:length],src[length:]
hexa = ' '.join(["%02X"%ord(x) for x in s])
s = s.translate(FILTER)
result += "%04X %-*s %s\n" % (N, length*3, hexa, s)
N+=length
return result
s=("This 10 line function is just a sample of pyhton power "
"for string manipulations.\n"
"The code is \x07even\x08 quite readable!")
print dump(s)This function produce a classic 3 columns hex dump of a string. * The first column print the offset in hexadecimal. * The second colmun print the hexadecimal byte values. * The third column print ASCII values or a dot for non printable characters.
代码的功能是把一段字符串数据,用 3 列进行展示,第一列是用 16 进制表示的字符串位置索引,第二列是 16 进制表示的字节,第三列是用 ASCII 编码表示的字符串值,如果是不能打印显示的字符用 . 表示。
我们用 WinHex 或 UltraEdit 打开二进制文件时,和这段脚本打印的信息很相似。在目标环境,没有使用复杂工具的条件,用这类脚本来分析数据,是一个很好的思路,是必须要掌握的技巧,尤其是可以用来分析网络数据,可以发现协议,账号,口令等重要的信息。
代码的来源是:
- http://code.activestate.com/recipes/142812-hex-dumper/
- https://github.com/ActiveState/code/blob/master/recipes/Python/142812_Hex_dumper/recipe-142812.py#L1
修改为 Python3 的代码如下:
def hexdump(src, length=16):
result = []
digits = 4 if isinstance(src, str) else 2
for i in range(0, len(src), length):
s = src[i:i + length]
hexa = ' '.join([hex(x)[2:].upper().zfill(digits) for x in s])
text = ''.join([chr(x) if 0x20 <= x < 0x7F else '.' for x in s])
result.append("{0:04X}".format(i) + ' '*3 + hexa.ljust(length * (digits + 1)) + ' '*3 + "{0}".format(text))
return '\n'.join(result)
print("hex dump string:")
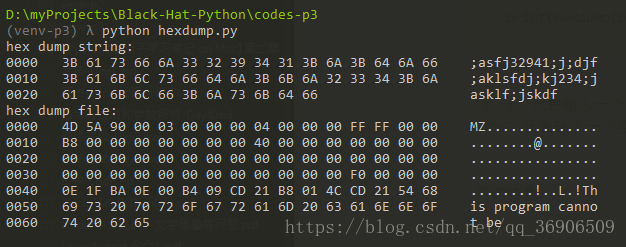
print(hexdump(b";asfj32941;j;djf;aklsfdj;kj234;jasklf;jskdf", 16))
print("hex dump file:")
with open("calc.exe", "rb") as fr:
buff = fr.read()
print(hexdump(buff[:100], 16))测试结果如下,这里也测试了从文件读取内容,读取出来的数据是 bytes 类型,直接传个 hexdump() 打印。
简单说明下,对这段代码的理解,主要是要搞懂字符编码和格式化打印两个知识点。
字符编码
关于字符编码的问题,在 Python3 下,文本字符和二进制数据区分得更清晰,分别用 str 和 bytes 表示。文本字符全部用 str 类型表示,str 能表示 Unicode 字符集中所有字符,而二进制字节数据用一种全新的数据类型,用 bytes 来表示。详情见 “Python 之禅” 公众号文章(Python3 是如何解决棘手的字符编码问题的?), 讲得非常好。
格式化打印
关于字符格式化打印的问题,在 Python2 下用 %-*s %04X %s 等形式,如:
"%04X %-*s %s" % (i, length*(digits + 1), hexa, text)
打印结果形如:
0000 3B 61 73 66 6A 33 32 39 34 31 3B 6A 3B 64 6A 66 ;asfj32941;j;djf
%-*s代表输入一个字符串,-号代表左对齐、后补空白,*号代表对齐宽度由输入时确定。%*s代表输入一个字符串,右对齐、前补空白,*号代表对齐宽度由输入时确定。%04X代表输入一个数字,按 16 进制打印,4 个字节对齐,前补 0.
在 Python3 下,常用 "{0} {1:2d}".format(text, num) 等形式,以及用 rjust() ljust() center() zfill() 等函数,来对齐和填充。
"{0} {1:2d}".format(text, num)# {0} 的位置打印 text, {1:2d} 的位置打印 num, 并且占用2个字节,十进制表示。- str.ljust(width,[fillchar]) # 输出 width 个字符,str 左对齐,不足部分用 fillchar 填充,默认为空格。
- str.rjust(width,[fillchar]) # 右对齐
- str.center(width, [fillchar]) # 中间对齐
- str.zfill(width) # 把 str 变成 width 长,并右对齐,不足部分在前用 0 补足
简单测试下:
>>> str = "hello world."
>>> str.ljust(20)
'hello world. '
>>> str.ljust(20, '*')
'hello world.********'
>>> str.rjust(20)
' hello world.'
>>> str.rjust(20, '+')
'++++++++hello world.'
>>> str.center(20)
' hello world. '
>>> str.center(20, '--')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: The fill character must be exactly one character long
>>> str.center(20, '-')
'----hello world.----'
>>> str.zfill(20)
'00000000hello world.'
>>>
















 1677
1677

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









