




 本文详细解析了Java中Map接口的几种实现类,包括HashMap、HashTable、LinkedHashMap和TreeMap的特点与应用场景。探讨了HashMap的工作原理,如数组索引、链表与红黑树的转换,以及线程安全性问题。
本文详细解析了Java中Map接口的几种实现类,包括HashMap、HashTable、LinkedHashMap和TreeMap的特点与应用场景。探讨了HashMap的工作原理,如数组索引、链表与红黑树的转换,以及线程安全性问题。
关于Map接口的延伸关系:
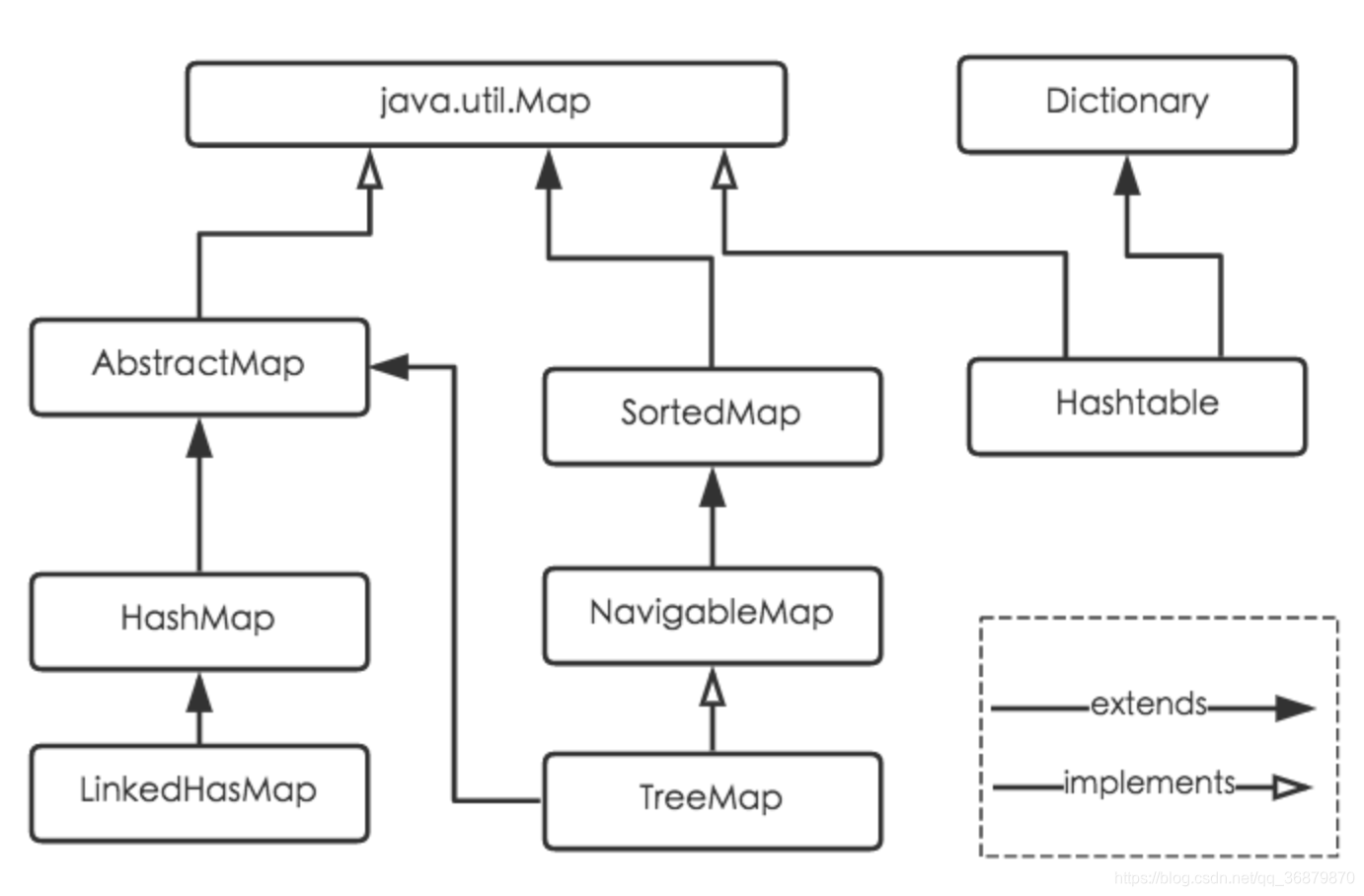
下面针对各个实现类的特点做一些说明:
1.HashMap:根据hashCode值存储数据,大多数情况下可以直接定位到他的值,因而具有很快的访问顺序,但遍历顺序确实不确定的。HashMap最多只允许一条记录的键为null,允许多条值为null,HashMap非线程安全,即任一时刻可以有多个线程同时写HashMap,可能会导致数据的不一致。如果需要满足线程安全,可以用Collection借口的synchronizedMap或ConcurrentHashMap
2.HashTable:HashTable是遗留类,很多映射的常用功能跟HashMap相似,不同的是他继承于Dictionary类,并且是线程安全的,任一时间只能有一个线程写HashTable,并发性不如ConcurrentHashMap,因为ConcurrentHashMap引入了分段锁。HashTable不建议在新代码中使用,若不需要线程安全可以用HashMap代替,需要线程安全的场合可以用ConcurrentHashMap替换
3.LinkedHashMap:LinkedHashMap是HashMap的子类,保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的数据肯定是先插入的,也可以在构造时带参数,按照访问次序排序
4.TreeMap:TreeMap实现SortedMap接口,能够将保存的数据根据键排序,默认是按键值的升序排序。也可以指定排序的比较器,当用Iterator遍历TreeMap时,得到的记录是排过序的。如果使用排序的映射,建议使用TreeMap。在使用TreeMap时,key必须实现Comparable接口或在构造TreeMap是传入自定义的Comparator,否则会在运行时报ClassCastException
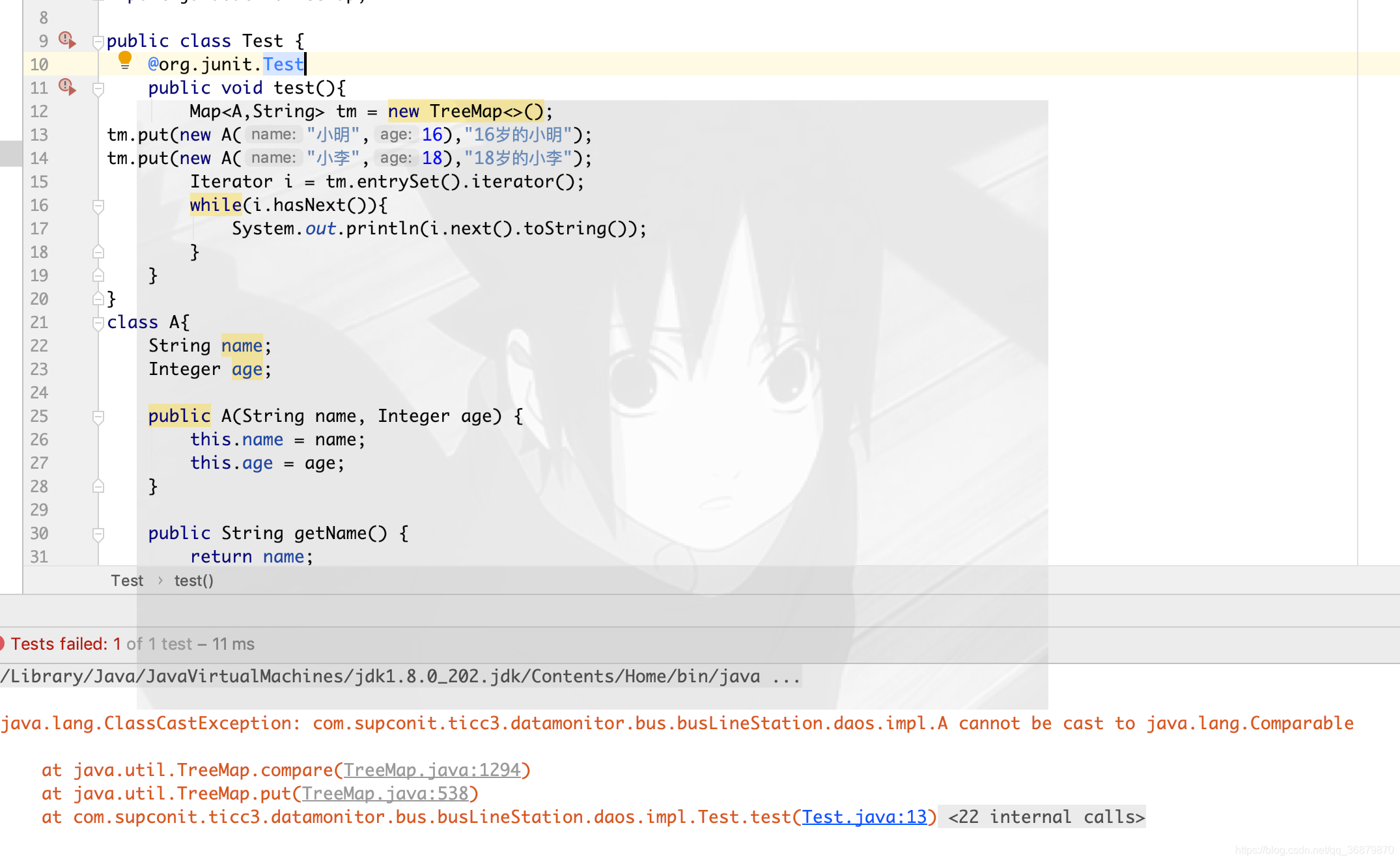
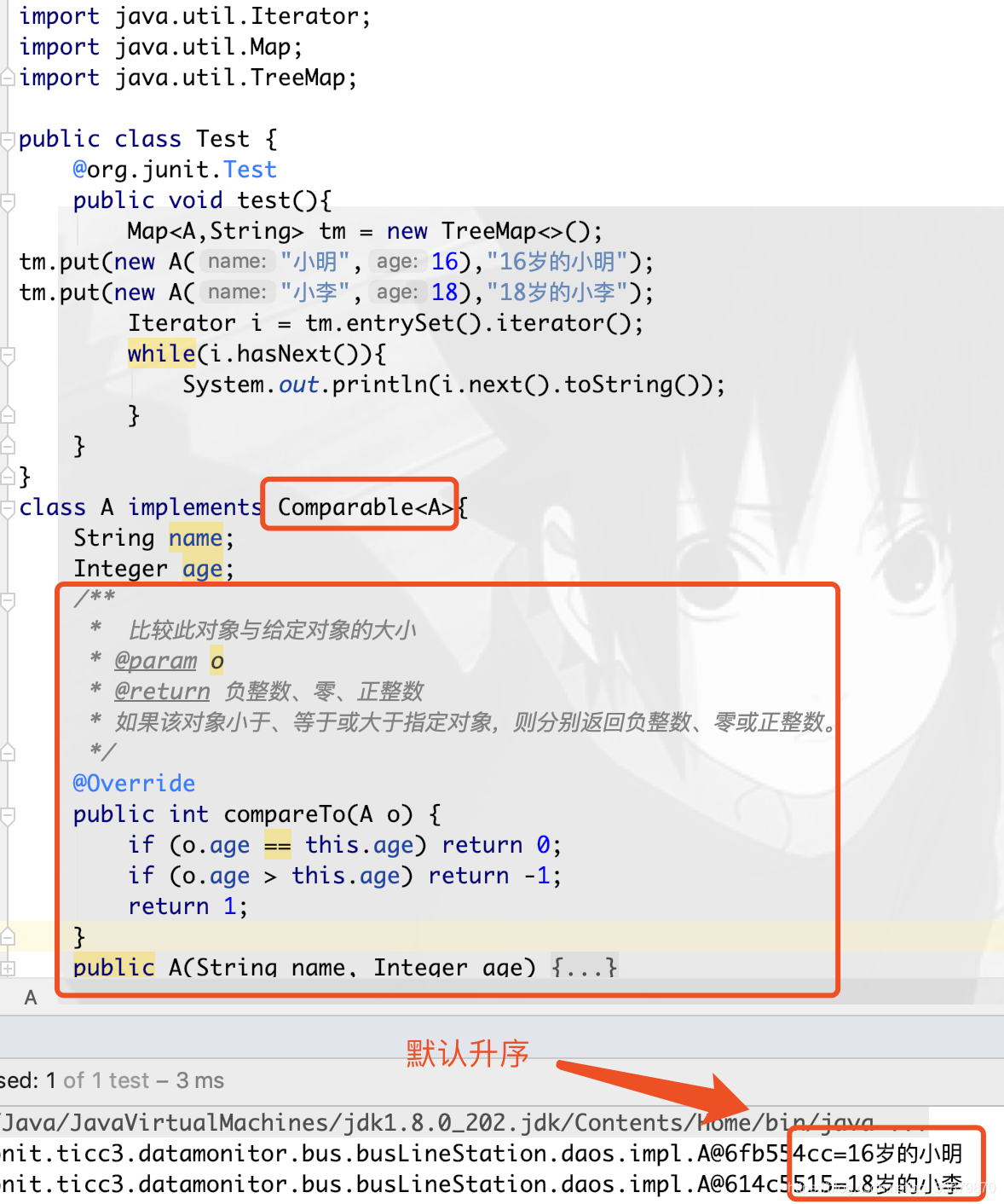
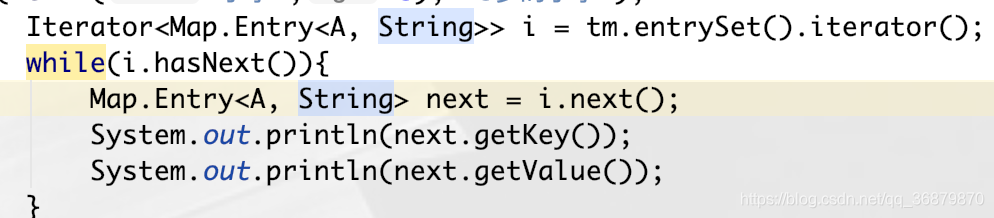
遍历取KeyValue
HashMap:HashMap是一个用来存储键值对的集合,每一个键值对就是一个Entry,这个Entry分布存储在一个数组中,这个数组就是HashMap的主干
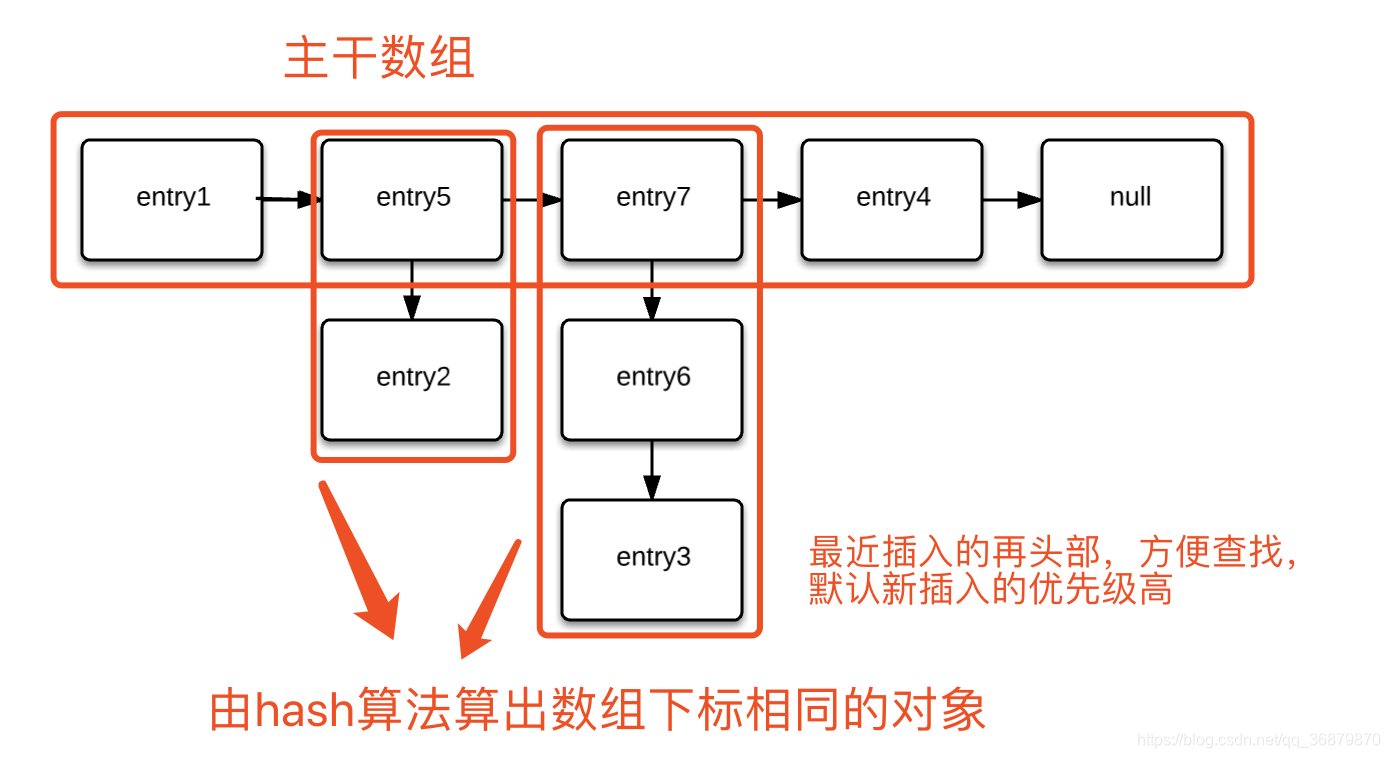
功能实现:
1.确定数组索引位置

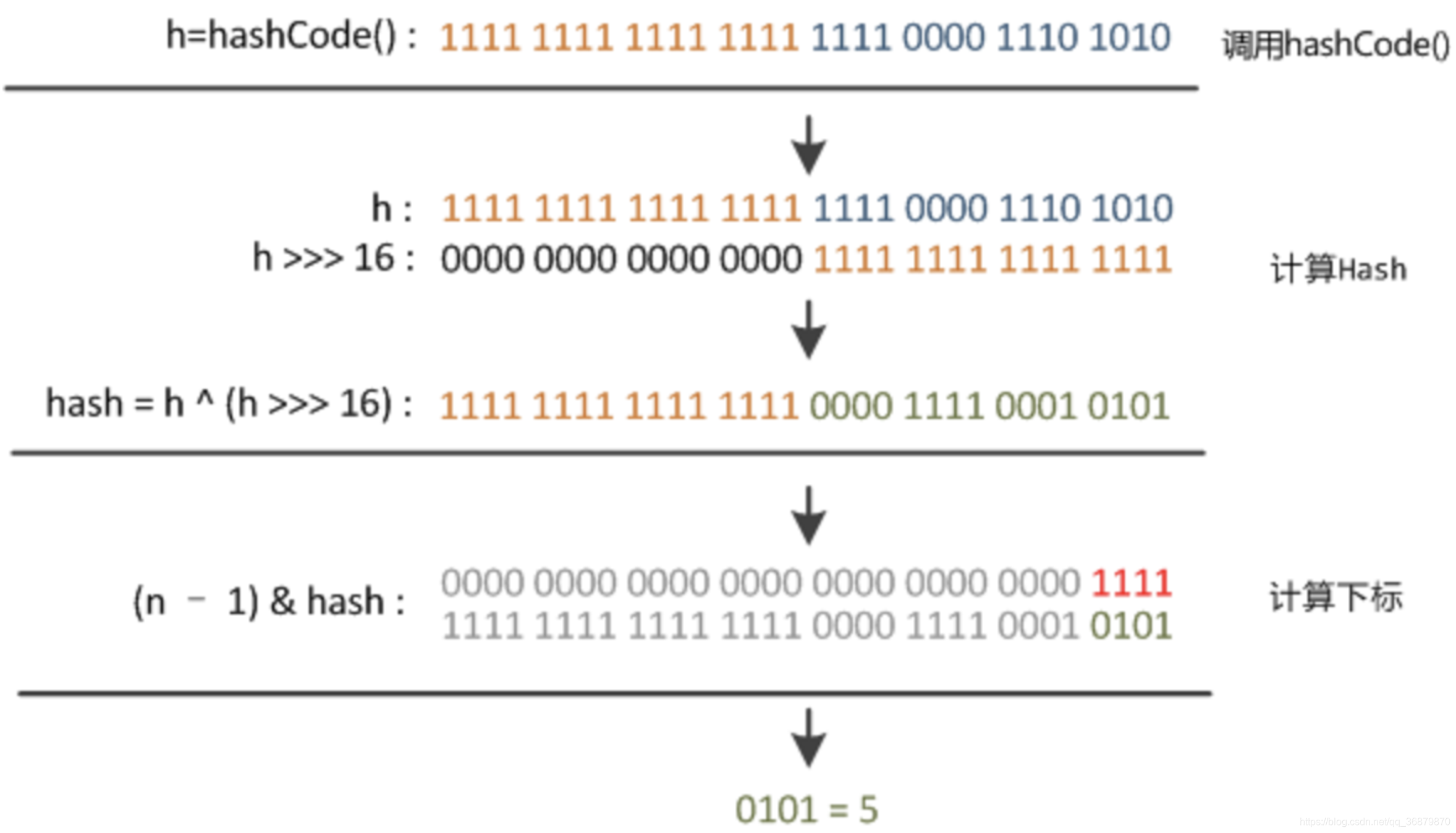
其中n为table的长度
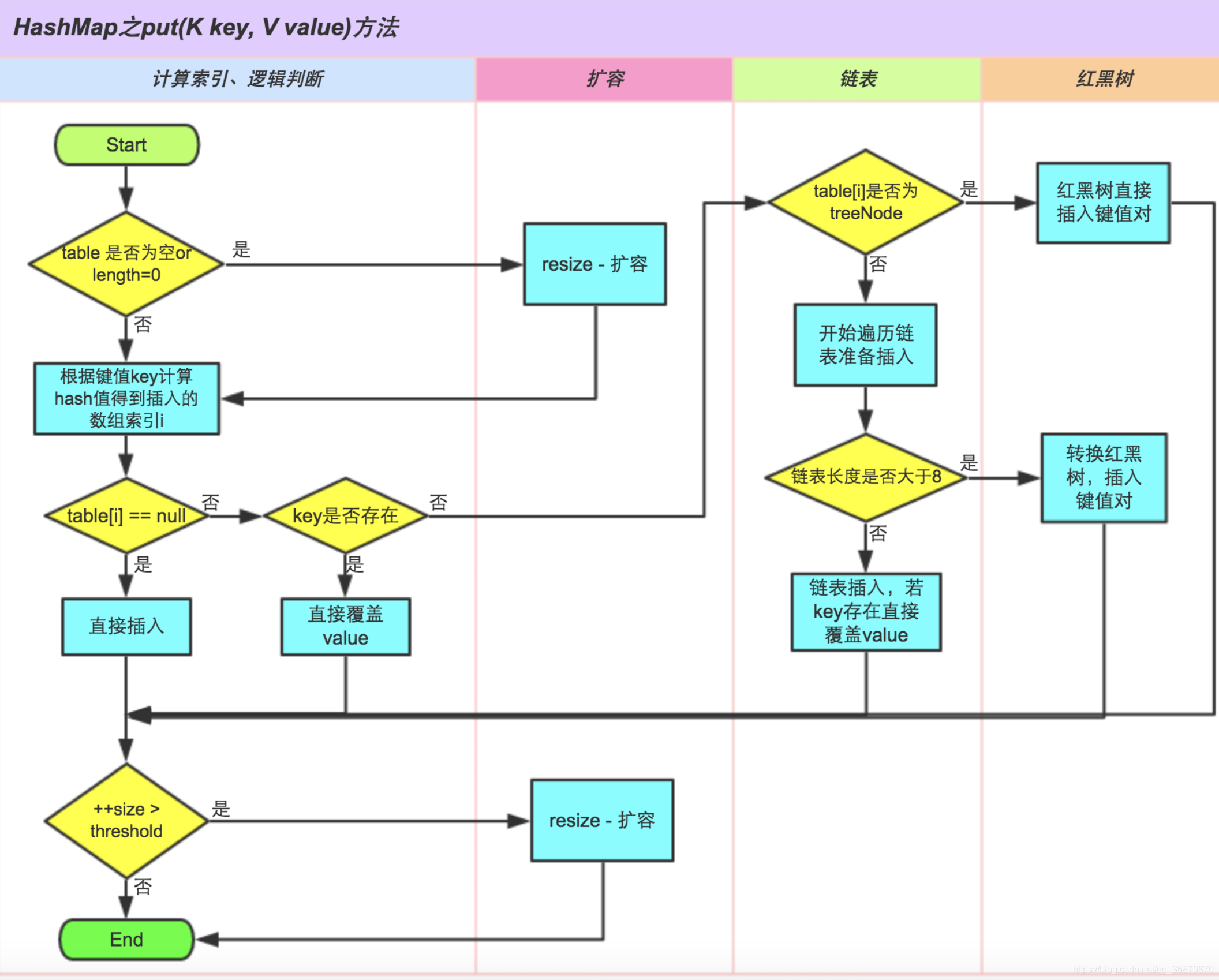
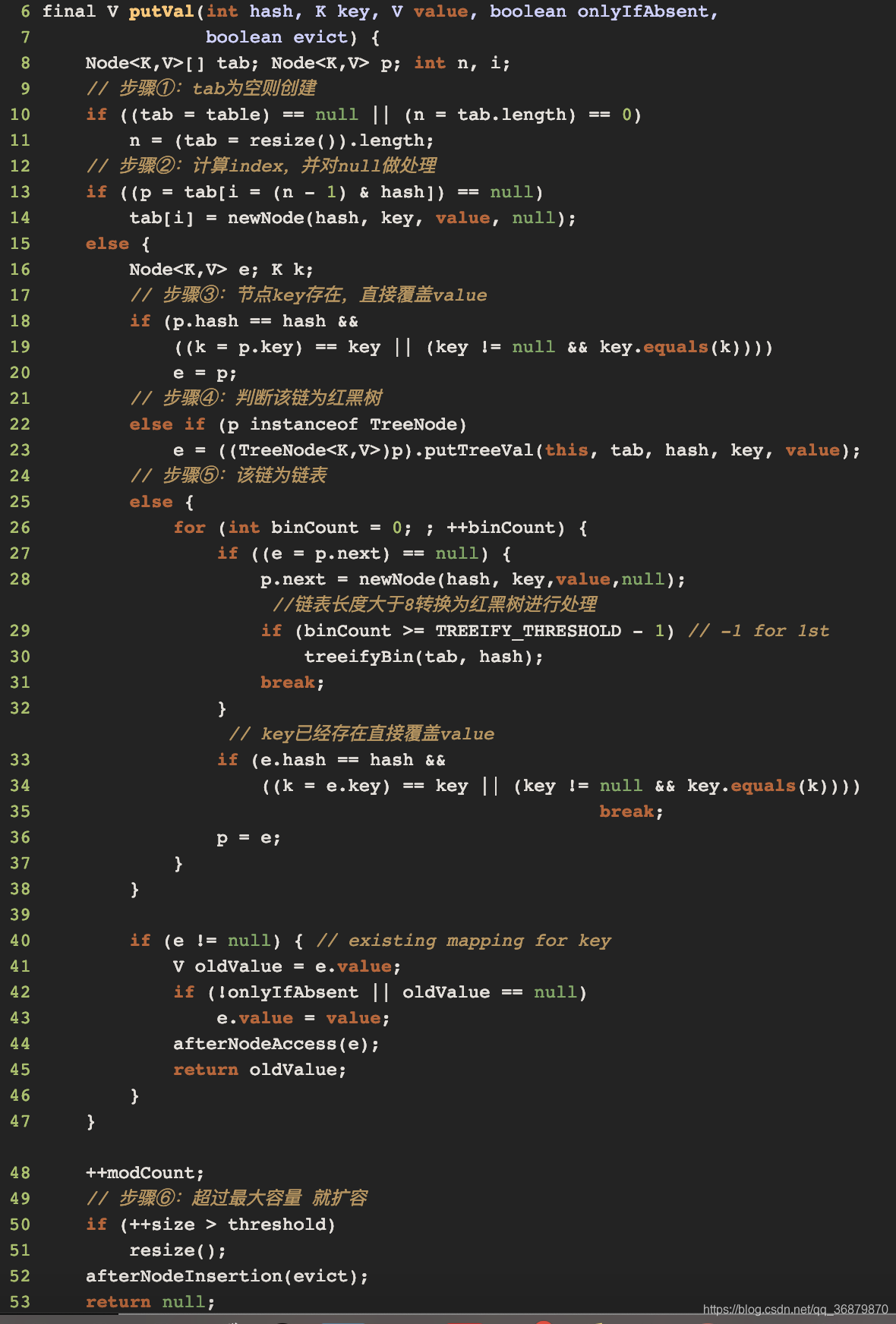
2.分析HashMap的put方法:
-
判断键值对对数组table[i]是否为空或者为null,否则执行resize()进行扩容
-
根据键值key计算hash值得到插入的数组索引i,如果table[i]==null,直接新建节点添加,转向6,如果table[i]不为空,则接着转向3
-
判断table[I]的首个元素是否和key一样,如果相同直接覆盖value,否则转向4,这里的相同指的是hashCode一级equals
-
判断table[I]是否为treeNode,即table[I]是否为红黑树,如果是红黑树则直接在树中插入键值对,否则转向5
-
遍历table[I](链表),判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操作,否则进行链表的插入操作,遍历过程中若发现key已经存在则直接覆盖value
-
插入成功后判断实际存在的键值对数量size是否超过了最大容量threshold,如果超过则进行扩容
-
risize方法中有遍历每个节点是否小于阙值6,若小于则把树形转化为链表
进程图:
源码:
3.为什么HashMap不是线程安全的
假如一个HashMap到了resize的临界点,这时两个线程同时对他进行了扩容之后进行ReHash,可能会形成链表环,当get一个不存在的key而这个key的hash计算为该下标时会造成死循环

















 2179
2179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









