




写在前面
决策粗糙集
1 决策粗糙集的引入
粗糙集的的思想:使用可定义集合刻画不可定义集合,从而给出上下近似集的概念定义。
Pawlaw经典粗糙集,只考虑了 定性 关系,过于严格、容错能力不足.
决策粗糙集模型:结合概率论展开研究,给出了粗糙集理论的 定量 描述。
定性:决定其概念、性质,只决定其含义。
定量:在定性的基础之上进行量化,定性过程中量的边界。
2. Pawlaw经典粗糙集回顾
粗糙集理论首次形式化地描述了对象的不可分辨性、属性冗余性及属性约简等重要概念。
重要贡献: 给出一种基于等价关系的数据分析方法,并且给出了一个非常精确、严格的数学描述。
上近似:
a
p
r
‾
(
X
)
=
{
x
∈
U
∣
[
x
]
∩
X
≠
∅
}
\overline{apr}(X) = \{x\in U | [ x] \cap X \neq \empty\}
apr(X)={x∈U∣[x]∩X̸=∅}
下近似:
a
p
r
‾
(
X
)
=
{
x
∈
U
∣
[
x
]
⊆
X
}
\underline{apr}(X) = \{x\in U | [ x] \subseteq X \}
apr(X)={x∈U∣[x]⊆X}
正域(必然性):
P
O
S
(
X
)
=
a
p
r
‾
(
X
)
=
{
x
∈
U
∣
[
x
]
⊆
X
}
POS(X) = \underline{apr}(X) = \{x\in U | [ x] \subseteq X \}
POS(X)=apr(X)={x∈U∣[x]⊆X}
负域:
N
E
G
(
X
)
=
U
−
a
p
r
‾
(
X
)
=
{
x
∈
U
∣
[
x
]
∩
X
=
∅
}
NEG(X) =U - \overline{apr}(X) = \{x\in U | [ x] \cap X = \empty\}
NEG(X)=U−apr(X)={x∈U∣[x]∩X=∅}
边界域(可能性):
B
N
D
(
X
)
=
a
p
r
‾
(
X
)
−
a
p
r
‾
(
X
)
=
{
x
∈
U
∣
[
x
]
∩
X
≠
∅
∧
¬
(
[
x
]
⊆
X
)
}
BND(X) =\overline{apr}(X) - \underline{apr}(X) = \{x\in U | [ x] \cap X \neq \empty \wedge \lnot ([x] \subseteq X)\}
BND(X)=apr(X)−apr(X)={x∈U∣[x]∩X̸=∅∧¬([x]⊆X)}

3. 决策粗糙集
3.1 问题引入
Pawlaw经典粗糙集被看作一种定性的近似,其定义不允许任何不确定性,这是优点也是缺点。
不允许任何的不确定性,难以体现概念表示的 容错性(包含错误的能力:宰相的肚子)。
由以上原因,考虑另外一种粗糙集的表示,将概念近似空间引入到粗糙集研究中,即:概率粗糙集模型。
1987年Wong和Xiarko将概率近似空间引入到粗糙集研究中。
3.2 基本理论
P r ( X ∣ [ x ] ) Pr(X|[x]) Pr(X∣[x])表示 任何一个属于[x]的对象 属于X的 条件概率,属于[x]是条件。
可获得以下等价条件:
| 条件 | 表示 | |
|---|---|---|
| POS | P r ( X / [ x ] ) = 1 ⇔ [ x ] ⊆ X Pr(X/[x])=1 \Leftrightarrow [x] \subseteq X Pr(X/[x])=1⇔[x]⊆X | { x ∈ U ∥ { P r ( X / [ x ] ) = 1 } \{x \in U \| \{ Pr(X/[x])=1\} {x∈U∥{Pr(X/[x])=1} |
| NEG | P r ( X / [ x ] ) = 0 ⇔ [ x ] ∩ X = ∅ Pr(X/[x])=0 \Leftrightarrow [x] \cap X = \empty Pr(X/[x])=0⇔[x]∩X=∅ | { x ∈ U ∥ { P r ( X / [ x ] ) = 0 } \{x \in U \| \{ Pr(X/[x])=0\} {x∈U∥{Pr(X/[x])=0} |
| BND | 0 < P r ( X / [ x ] ) < 1 ⇔ [ x ] ∩ X ≠ ∅ ∧ ¬ ( [ x ] ⊆ X ) } 0< Pr(X/[x])<1 \Leftrightarrow [ x] \cap X \neq \empty \wedge \lnot ([x] \subseteq X)\} 0<Pr(X/[x])<1⇔[x]∩X̸=∅∧¬([x]⊆X)} | { x ∈ U ∥ { 0 < P r ( X / [ x ] ) < 1 } \{x \in U \| \{ 0< Pr(X/[x])<1\} {x∈U∥{0<Pr(X/[x])<1} |
上述的 0 和 1 是概率的两个极端值,我们可以使用其他(0 < t < 1)的值来表示。
我们使用 β \beta β 和 α \alpha α 来替换上述的 0 , 1 值的时候就是 决策粗糙集。0< β \beta β < α \alpha α < 1。
| 条件 | |
|---|---|
| POS | P O S ( α , β ) = { x ∈ U ∥ { P r ( X / [ x ] ) ≥ α } POS_{(\alpha ,\beta)} = \{x \in U \| \{ Pr(X/[x]) \ge \alpha \} POS(α,β)={x∈U∥{Pr(X/[x])≥α} |
| NEG | N E G ( α , β ) = { x ∈ U ∥ { P r ( X / [ x ] ) ≤ β } NEG_{(\alpha ,\beta)} = \{x \in U \| \{ Pr(X/[x]) \leq \beta\} NEG(α,β)={x∈U∥{Pr(X/[x])≤β} |
| BND | B N D ( α , β ) = { x ∈ U ∥ { β < P r ( X / [ x ] ) < α } BND_{(\alpha ,\beta)} =\{x \in U \| \{ \beta< Pr(X/[x])<\alpha\} BND(α,β)={x∈U∥{β<Pr(X/[x])<α} |
当 ( β , α ) (\beta,\alpha) (β,α)为(0,1)时候,决策粗糙集就成为了经典粗糙集。
3.3 待解决的问题
- 阈值 β \beta β 和 α \alpha α 的解释和计算。(贝叶斯决策论处理)
- 条件概率 P r ( X / [ x ] ) Pr(X/[x]) Pr(X/[x])的估计。(朴素贝叶斯)
- 概率正、负和边界域的解释和应用。(三支决策)
4. 问题处理
4.1 阈值 β \beta β 和 α \alpha α 的解释和计算(贝叶斯决策论处理)
研究 将对象划分到对应域的损失 来解释和计算阈值。
损失函数 :

a
P
,
a
N
,
a
B
a_P,a_N,a_B
aP,aN,aB:分别为将对象分类到正域、负域和边界域的决策动作。
λ
P
P
,
λ
N
P
,
λ
B
P
\lambda_{PP},\lambda_{NP},\lambda_{BP}
λPP,λNP,λBP:表示一个对象 属于 集合X时候采取
a
P
,
a
N
,
a
B
a_P,a_N,a_B
aP,aN,aB决策带来的损失函数
λ
P
N
,
λ
N
N
,
λ
B
N
\lambda_{PN},\lambda_{NN},\lambda_{BN}
λPN,λNN,λBN:表示一个对象 不属于 集合X时候采取
a
P
,
a
N
,
a
B
a_P,a_N,a_B
aP,aN,aB决策带来的损失函数
对于[x]中对象不同动作产生的 损失表示 :
划分到正域:
(
1
)
R
(
a
P
∣
[
x
]
)
=
λ
P
P
∗
P
r
(
X
∣
[
x
]
)
+
λ
P
N
∗
P
r
(
X
c
∣
[
x
]
)
(1) R(a_P| [x]) = \lambda_{PP}*Pr(X|[x])+\lambda_{PN}*Pr(X^c|[x])
(1)R(aP∣[x])=λPP∗Pr(X∣[x])+λPN∗Pr(Xc∣[x])
划分到边界域:
(
2
)
R
(
a
B
∣
[
x
]
)
=
λ
B
P
∗
P
r
(
X
∣
[
x
]
)
+
λ
B
N
∗
P
r
(
X
c
∣
[
x
]
)
(2) R(a_B| [x]) = \lambda_{BP}*Pr(X|[x])+\lambda_{BN}*Pr(X^c|[x])
(2)R(aB∣[x])=λBP∗Pr(X∣[x])+λBN∗Pr(Xc∣[x])
划分到负域:
(
3
)
R
(
a
N
∣
[
x
]
)
=
λ
N
P
∗
P
r
(
X
∣
[
x
]
)
+
λ
N
N
∗
P
r
(
X
c
∣
[
x
]
)
(3) R(a_N| [x]) = \lambda_{NP}*Pr(X|[x])+\lambda_{NN}*Pr(X^c|[x])
(3)R(aN∣[x])=λNP∗Pr(X∣[x])+λNN∗Pr(Xc∣[x])
(Note: X c X^c Xc是 X X X的补集)
最小风险决策规则 :
若(1)<= (2) 且(1)<= (3)则:
x
∈
P
O
S
(
X
)
x\in POS(X)
x∈POS(X)
若(2)<= (1) 且(2)<= (3)则:
x
∈
B
N
D
(
X
)
x\in BND(X)
x∈BND(X)
若(3)<= (1) 且(3)<= (2)则:
x
∈
N
E
G
(
X
)
x\in NEG(X)
x∈NEG(X)
β \beta β、 α \alpha α 和 λ \lambda λ 的产生
由于以下公式:
P
r
(
X
∣
[
x
]
)
+
∗
P
r
(
X
c
∣
[
x
]
)
=
1
Pr(X|[x]) + *Pr(X^c|[x]) = 1
Pr(X∣[x])+∗Pr(Xc∣[x])=1
Note:
X
c
X^c
Xc是
X
X
X的补集。
我们可以使用 损失函数
λ
\lambda
λ 和
P
r
(
X
∣
[
x
]
)
Pr(X|[x])
Pr(X∣[x]) 简化 最小风险决策规则。
一般来说一个属于X的对象x划分到三个域的损失有以下情况:
λ
P
P
<
=
λ
B
P
<
λ
N
P
\lambda_{PP} <= \lambda_{BP} < \lambda_{NP}
λPP<=λBP<λNP
λ
N
N
<
=
λ
B
N
<
λ
P
N
\lambda_{NN} <= \lambda_{BN} < \lambda_{PN}
λNN<=λBN<λPN
基于以上条件可得到3个阈值:
α
=
λ
P
N
−
λ
B
N
(
λ
P
N
−
λ
B
N
)
+
(
λ
B
P
−
λ
P
P
)
\alpha = \frac{\lambda_{PN} - \lambda_{BN}}{(\lambda_{PN}-\lambda_{BN})+(\lambda_{BP}-\lambda_{PP})}
α=(λPN−λBN)+(λBP−λPP)λPN−λBN
λ = λ P N − λ N N ( λ P N − λ N N ) + ( λ N P − λ P P ) \lambda = \frac{\lambda_{PN} - \lambda_{NN}}{(\lambda_{PN}-\lambda_{NN})+(\lambda_{NP}-\lambda_{PP})} λ=(λPN−λNN)+(λNP−λPP)λPN−λNN
β = λ B N − λ N N ( λ B N − λ N N ) + ( λ N P − λ B P ) \beta = \frac{\lambda_{BN} - \lambda_{NN}}{(\lambda_{BN}-\lambda_{NN})+(\lambda_{NP}-\lambda_{BP})} β=(λBN−λNN)+(λNP−λBP)λBN−λNN
最小风险决策规则2(使用alpha、beta 和 lambda):
若
P
r
(
X
∣
[
x
]
)
≥
α
Pr(X|[x]) \ge \alpha
Pr(X∣[x])≥α 且
P
r
(
X
∣
[
x
]
)
≥
λ
Pr(X|[x]) \ge \lambda
Pr(X∣[x])≥λ 则 :
x
∈
P
O
S
(
X
)
x\in POS(X)
x∈POS(X)
若
P
r
(
X
∣
[
x
]
)
≤
α
Pr(X|[x]) \le \alpha
Pr(X∣[x])≤α 且
P
r
(
X
∣
[
x
]
)
≥
β
Pr(X|[x]) \ge \beta
Pr(X∣[x])≥β 则 :
x
∈
B
N
D
(
X
)
x\in BND(X)
x∈BND(X)
若
P
r
(
X
∣
[
x
]
)
≤
β
Pr(X|[x]) \le \beta
Pr(X∣[x])≤β 且
P
r
(
X
∣
[
x
]
)
≤
λ
Pr(X|[x]) \le \lambda
Pr(X∣[x])≤λ 则 :
x
∈
N
E
G
(
X
)
x\in NEG(X)
x∈NEG(X)
最小风险决策规则3(去除lambda):
进一步假设 λ N P − λ B P λ N P − λ N N > λ B P − λ P P λ P N − λ B N \frac{\lambda_{NP} - \lambda_{BP} }{\lambda_{NP} -\lambda_{NN}} > \frac{\lambda_{BP} - \lambda_{PP} }{\lambda_{PN} -\lambda_{BN}} λNP−λNNλNP−λBP>λPN−λBNλBP−λPP ,可证明 α \alpha α > λ \lambda λ > β \beta β,则不再需要阈值 λ \lambda λ ,风险决策可简化。
若
P
r
(
X
∣
[
x
]
)
≥
α
Pr(X|[x]) \ge \alpha
Pr(X∣[x])≥α 则 :
x
∈
P
O
S
(
X
)
x\in POS(X)
x∈POS(X)
若
β
<
P
r
(
X
∣
[
x
]
)
<
α
\beta < Pr(X|[x]) < \alpha
β<Pr(X∣[x])<α 则 :
x
∈
B
N
D
(
X
)
x\in BND(X)
x∈BND(X)
若
P
r
(
X
∣
[
x
]
)
≤
β
Pr(X|[x]) \le \beta
Pr(X∣[x])≤β 则 :
x
∈
N
E
G
(
X
)
x\in NEG(X)
x∈NEG(X)
4.2 条件概率 P r ( X / [ x ] ) Pr(X/[x]) Pr(X/[x])的估计(朴素贝叶斯)
使用朴素贝叶斯公式对条件概率 P r ( X / [ x ] ) Pr(X/[x]) Pr(X/[x])进行估计。
朴素贝叶斯公式:
P r ( X ∣ [ x ] ) = P r ( [ x ] ∣ X ) P r ( X ) P r ( [ x ] ) ( 公 式 1 ) Pr(X|[x]) = \frac{Pr([x]|X)Pr(X)}{Pr([x])} (公式1) Pr(X∣[x])=Pr([x])Pr([x]∣X)Pr(X)(公式1)
P
r
(
X
∣
[
x
]
)
Pr(X|[x])
Pr(X∣[x]):后验概率
P
r
(
[
x
]
∣
X
)
Pr([x]|X)
Pr([x]∣X):似然函数
P
r
(
X
)
Pr(X)
Pr(X):先验概率
后验概率 转化为 似然比
通过引入赔率(odds)变换、对数(logit)变换将
P
r
(
X
∣
[
x
]
)
Pr(X|[x])
Pr(X∣[x])转换为
P
r
(
[
x
]
∣
X
)
P
r
(
[
x
]
∣
X
c
)
\frac{Pr([x]|X)}{Pr([x]|X^c)}
Pr([x]∣Xc)Pr([x]∣X)
即:
l
o
g
i
t
(
P
r
(
[
x
]
∣
X
)
)
=
l
o
g
(
O
(
P
r
(
[
x
]
∣
X
)
)
)
=
l
o
g
(
P
r
(
[
x
]
∣
X
)
P
r
(
[
x
]
∣
X
c
)
)
+
l
o
g
(
P
r
(
X
)
P
r
(
X
c
)
)
(
公
式
2
)
logit( Pr([x]|X) ) = log( O(Pr([x]|X)) ) = log(\frac{Pr([x]|X)}{Pr([x]|X^c)})+log( \frac{Pr(X)}{Pr(X^c)}) (公式2)
logit(Pr([x]∣X))=log(O(Pr([x]∣X)))=log(Pr([x]∣Xc)Pr([x]∣X))+log(Pr(Xc)Pr(X))(公式2)
对象子集 [ x ] [x] [x] 使用属性子集 A ⊆ A t A\subseteq At A⊆At : [ x ] = [ x ] A = ∩ a ∈ A [ x ] { a } [x] = [x]_A = \cap_{a\in A}[x]_{\{a\}} [x]=[x]A=∩a∈A[x]{a}。
估计 P r ( [ x ] ∣ X ) Pr([x]|X) Pr([x]∣X)和 P r ( [ x ] ∣ X c ) Pr([x]|X^c) Pr([x]∣Xc)
为了估计
P
r
(
[
x
]
∣
X
)
Pr([x]|X)
Pr([x]∣X)和
P
r
(
[
x
]
∣
X
c
)
Pr([x]|X^c)
Pr([x]∣Xc),做出如下假设:
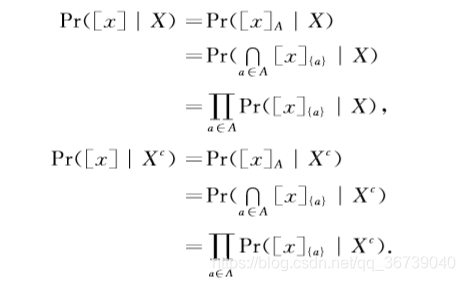
代入公式2:

阈值来说建立以下关系:

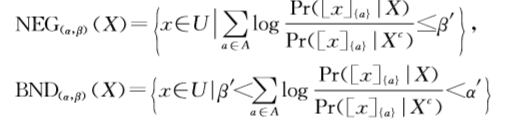
4.3 概率正、负和边界域的解释和应用(三支决策)
粗糙集可以看作是三支决策的特例,三支决策给出了更加广泛的理论、方法和工具。
5 定性定量区别
定性:不容许错误。
定量:可以容忍错误。
现实生活中不存在绝对的错误,所以定量的方式更有意义。
详细了解请查阅论文:决策粗糙集理论研究现状与展望

















 2085
2085

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









