






 本文深入解析SpringData-JPA如何简化Spring框架应用的数据访问技术,涵盖非关系数据库、Map-Reduce框架、云数据服务及关系数据库访问支持。介绍SpringData特点、统一的Repository接口、数据访问模板类及JPA与SpringData整合,包括JpaRepository基本功能、规范方法命名、@Query自定义查询和Specifications查询。
本文深入解析SpringData-JPA如何简化Spring框架应用的数据访问技术,涵盖非关系数据库、Map-Reduce框架、云数据服务及关系数据库访问支持。介绍SpringData特点、统一的Repository接口、数据访问模板类及JPA与SpringData整合,包括JpaRepository基本功能、规范方法命名、@Query自定义查询和Specifications查询。
SpringBoot学习之路(X4)- 整合Spring Data - JPA
简介
Spring Data作用
Spring Data 项目的目的是为了简化构建基于 Spring 框架应用的数据访问技术,包括非关系数据库、Map-Reduce 框架、云数据服务等等;另外也包含对关系数据库的访问支持。
1、Spring Data特点
SpringData为我们提供使用统一的API来对数据访问层进行操作;这主要是Spring Data Commons项目来实现的。Spring Data Commons让我们在使用关系型或者非关系型数据访问技术时都基于Spring提供的统一标准,标准包含了CRUD(创建、获取、更新、删除)、查询、排序和分页的相关操
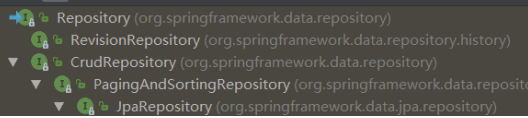
2、统一的Repository
- Repository<T, ID extends Serializable>:统一接口
- RevisionRepository<T, ID extends Serializable, N extends Number & Comparable>:基于乐观锁机制
- CrudRepository<T, ID extends Serializable>:基本CRUD操作
- PagingAndSortingRepository<T, ID extends Serializable>:基本CRUD及分页
3、提供数据访问模板类 xxxTemplate
如:MongoTemplate、RedisTemplate等
如图所示:
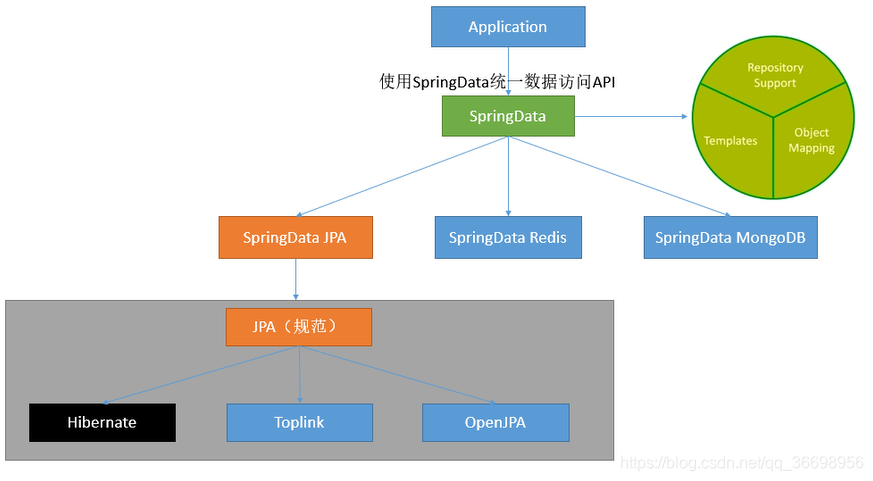
4、JPA与Spring Data
1)、JpaRepository基本功能
编写接口继承JpaRepository既有crud及分页等基本功能
2)、定义符合规范的方法命名
在接口中只需要声明符合规范的方法,即拥有对应的功能


















 3811
3811




 到【灌水乐园】发言
到【灌水乐园】发言







