




一、搜索引擎信息收集
1、谷歌语法
通过特定站点范围查询子域:site:qq.com

2、证书搜索
基于SSL证书查询子域:https://crt.sh/

3、DNS搜索
基于DNS记录查询子域:DNS在线查询工具 - Coding.Tools
二、目录扫描
1、目录遍历
2、敏感信息泄露
输入url 可以获取目录详情、操作系统、中间件、开发语言、版本信息 等 ( sql注入)
前端(HTML、CSS、JS)里面包含登录地址,内网接口信息、账号和密码
3、robots.txt(爬虫协议)
https://zhuanlan.zhihu.com/p/683759639
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
所有蜘蛛抓取整站 Disallow:禁止 Allow:允许 例如如下允许
User-agent: *
Allow: /符合表示
“*”: 代表所有 “$”:匹配行结束符。 “/”:代表根目录或者目录内所有文件目录扫描方式
1、robots.txt 网站内robots文件
2、目录探测:御剑, nikto disbuster webdirscan dirbuster
3、第三方资源:Js SDK
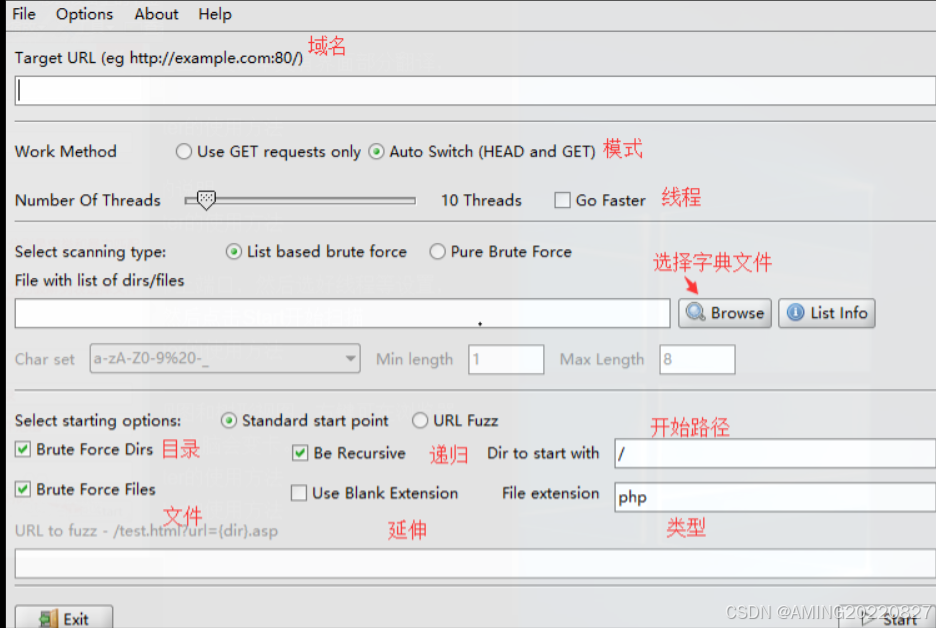
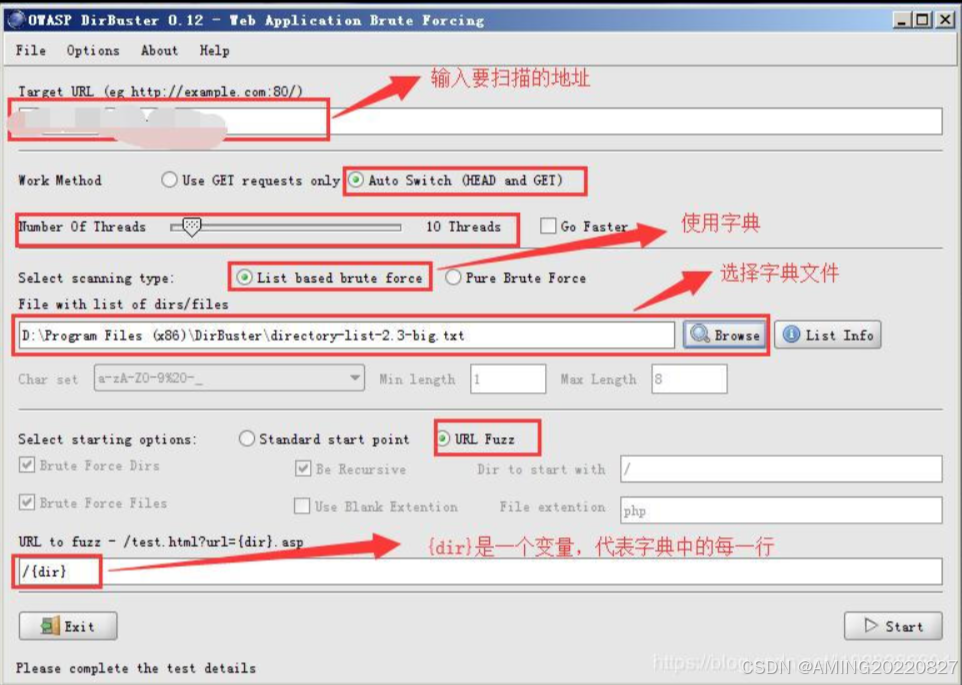
DirBuster
用于探测web目录结构和隐藏的敏感文件



















 1932
1932

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











