




1.文件系统
1.1.文件系统的工作原理
文件系统是在磁盘的基础上,提供了一个用来管理文件的树状结构。
接下来我们就看看Linux 文件系统的工作原理。
1.1.1索引节点和目录项
在 Linux 中一切皆文件 ,文件系统,本身是对存储设备上的文件,进行组织管理的机制
为了方便管理,Linux 文件系统为每个文件都分配两个数据结构,索引节点(index node)和 目录项(directory entry)。
- 它们主要用来记录文件的元信息 和目录结构。索引节点,简称为 inode,用来记录文件的元数据,比如 inode 编号、文件大小、访问权限、修改日期、数据的位置等。索引节点和文件一一对应,它跟文件内容一样,都会被持久化存储到磁盘中。所以记住,索引节点同样占用磁盘空间。
- 目录项,简称为 dentry,用来记录文件的名字、索引节点指针以及与其他目录项的关联关系。多个关联的目录项,就构成了文件系统的目录结构。不过,不同于索引节点,目录项是由内核维护的一个内存数据结构,所以通常也被叫做目录项缓存。
文件数据到底是怎么存储的呢?
磁盘读写的最小单位是扇区,然而扇区只有 512B 大小,如果每次都读写这么小的单位,效率一定很低。所以,文件系统又把连续的
扇区组成了逻辑块,然后每次都以逻辑块为最小单元,来管理数据。常见的逻辑块大小为 4KB,也就是由连续的 8 个扇区组成。
注意:
- 目录项本身就是一个内存缓存,而索引节点则是存储在磁盘中的数据 ,Buw er和Cache缓存可以协调慢速磁盘
与快速 CPU 的性能差异,文件内容会缓存到页缓存 Cache 中 ,这些索引节点自然也会缓存到内存中,加速文
件的访问。 - 磁盘在执行文件系统格式化时,会被分成三个存储区域,超级块、索引节点区 和数据块区。超级块,存储整个文件系统的状态。索引节点区,用来存储索引节点。
数据块区,则用来存储文件数据。
1.1.2.虚拟文件系统
**什么是虚拟文件系统VFS? **
为了支持各种不同的文件系统,Linux 内核在用户进程和文件系统的中间,又引入了一个抽象层,也就是虚拟文件系统 VFS(Virtual File System)。VFS 定义了一组所有文件系统都支持的数据结构和标准接口。这样,用户进程和内核中的其他子系统,只需要跟 VFS 提供的统一接口进行交互就可以了,而不需要再关心底层各种文件系统的实现细节。
为了更好地理解系统调用、VFS、缓存、文件系统以及块存储之间的关系 ,可以参考Linux 文件系统的架构图。
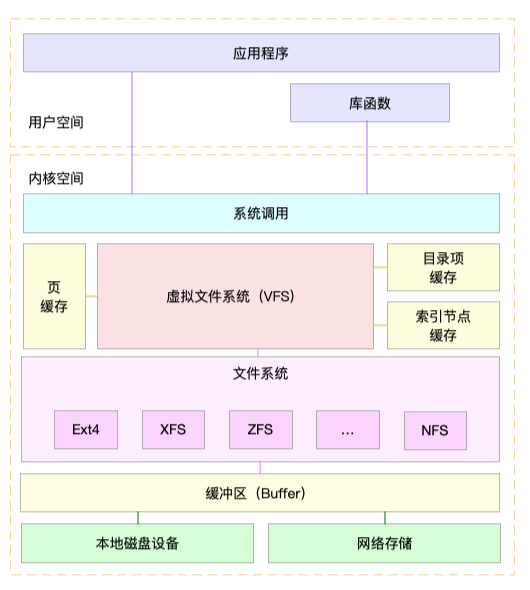
通过这张图,你可以看到,在 VFS 的下方,Linux 支持各种各样的文件系统,如 Ext4、XFS、NFS 等等。按照存储位置的不同,这些文件系统可以分为三类。
第一类是基于磁盘的文件系统,也就是把数据直接存储在计算机本地挂载的磁盘中。常见的 Ext4、XFS、OverlayFS等,都是这类文件系统。
第二类是基于内存的文件系统,也就是我们常说的虚拟文件系统。这类文件系统,不需要任何磁盘分配存储空间,但会占用内存。我们经常用到的 /proc就是一种最常见的虚拟文件系统。
第三类是网络文件系统,也就是用来访问其他计算机数据的文件系统,比如 NFS、SMB、iSCSI 等。
这些文件系统,要先挂载到 VFS 目录树中的某个子目录(称为挂载点),然后才能访问其中的文件。拿第一类,也就是基于磁盘的文件系统为例,在安装系统时,要先挂载一个根目录(/),在根目录下再把其他文件系统(比如其他的磁盘分区、/proc 文件系统、/sys 文件系统、NFS 等)挂载进来。
2.磁盘I/O工作原理
2.1.磁盘类型
2.1.1.根据介质不同分类
常见磁盘可以分为两类:机械磁盘和固态磁盘。
第一类,机械磁盘,也称为硬盘驱动器(Hard Disk Driver),通常缩写为 HDD。机械磁盘主要由盘片和读写磁头组成,数据就存储在盘片的环状磁道中。在读写数据前,需要移动读写磁头,定位到数据所在的磁道,然后才能访问数据。
如果 I/O 请求刚好连续,那就不需要磁道寻址,自然可以获得最佳性能。这其实就是我们熟悉的,连续 I/O 的工作原理。与之相对应的,当然就是随机 I/O,它需要不停地移动磁头,来定位数据位置,所以读写速度就会比较慢。
第二类,固态磁盘(Solid State Disk),通常缩写为 SSD,由固态电子元器件组成。固态磁盘不需要磁道寻址,所以,不管是连续 I/O,还是随机 I/O 的性能,都比机械磁盘要好得多。
其实,无论机械磁盘,还是固态磁盘,相同磁盘的随机 I/O 都要比连续 I/O 慢很多,原因也很明显。
- 对机械磁盘来说,我们刚刚提到过的,由于随机 I/O 需要更多的磁头寻道和盘片旋转,它的性能自然要比连续 I/O 慢。
- 而对固态磁盘来说,虽然它的随机性能比机械硬盘好很多,但同样存在“先擦除再写入”的限制。随机读写会导致大量的垃圾回收,所以相对应的,随机 I/O 的性能比起连续 I/O 来,也还是差了很多。
- 此外,连续 I/O 还可以通过预读的方式,来减少 I/O 请求的次数,这也是其性能优异的一个原因。很多性能优化的方案,也都会从这个角度出发,来优化 I/O 性能。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 810
810

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











