




今时网上流行一句话:“人生苦短,我学python。”python以其简单易学,应用领域广及众多第三方包而快速风靡IT圈。在python的众多第三方包中BeautifulSoup是网页解析中最常用也是最好用的。下面我们就以爬取纵横小说网小说榜http://book.zongheng.com/rank/male/r1/c0/q0/1.html为例,简单的介绍一下BeautifulSoup的用法。
1、安装BeautifulSoup
pip install bs42、内容补全
prettify()方法from bs4 import BeautifulSoup
html ="<b><!--This will be used in the crawler--></b><p>It's wonderful"
tags = []
#soup = BeautifulSoup(html,'html.parser')
#环境问题(安装c++环境),可能报错,lxml比html.parser解析速度快
soup = BeautifulSoup(html,'lxml')
fixed_html = soup.prettify()
print(fixed_html)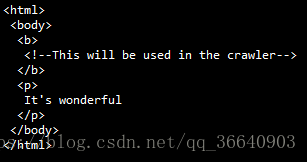
3、标签选择器
获取网页整体信息
from bs4 import BeautifulSoup
import requests
html = requests.get("http://book.zongheng.com/rank/male/r1/c0/q0/1.html").text
soup = BeautifulSoup(html,'lxml')
print(soup)
获取title标签
print(soup.title)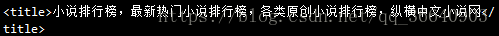
3、获取标签名称
print(soup.title.name)
4、获取标签属性
from bs4 import BeautifulSoup
import requests
html = requests.get("http://book.zongheng.com/rank/male/r1/c0/q0/1.html").text
soup = BeautifulSoup(html,'lxml')
print(soup.form)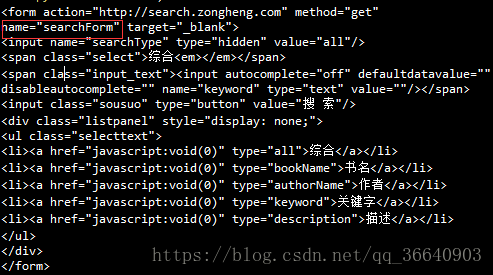
print(soup.form['name'])print(soup.form.attrs['name'])

5、获取内容
print(soup.li)
print(soup.li.string)
6、标准选择器
soup.find_all(name,attrs,...)#该方法返回多个元素 name:标签名字 attrs:标签属性 soup.find(name,attrs,...)返回单个元素print(soup.find_all('span'))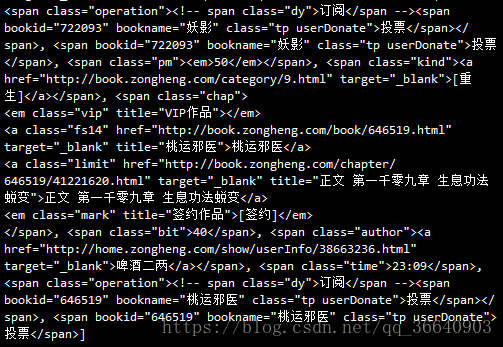
print(soup.find_all(attrs={'bookid':646519}))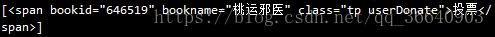
7、css选择器
print(soup.select('.kind')) #依据 类class
print(soup.select('li span'))#根据标签名选择
from bs4 import BeautifulSoup
html ='''<html>
<body>
<b>
<!--This will be used in the crawler-->
</b>
<p id='aojin'>
It's wonderful
</p>
</body>
</html>'''
soup = BeautifulSoup(html,'lxml')
print(soup.select('#aojin')) #依据id进行选择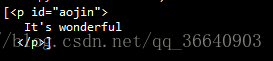
最后附上我的一次作业代码及结果:爬取纵横网上排行榜单书籍信息。
from bs4 import BeautifulSoup
import requests
html = requests.get("http://book.zongheng.com/rank/male/r1/c0/q0/1.html").text
soup = BeautifulSoup(html,'lxml')
lis = soup.select('li')
kind = []
chap = []
for li in lis:
kinds = li.select('.kind')
chaps = li.select('.chap')
for cp in chaps:
chap.append(str(cp.get_text()).replace('\n',''))
for kd in kinds:
kind.append(kd.get_text())
for cp in chap:
print(cp)


















 1263
1263

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









