







首先注明:感谢拉勾网提供的权威、质量的数据,本人抱着学习的态度,不愿增加其服务器负担,与dos攻击。
继上一篇爬取拉勾网后的第二篇文章,同样是使用scrapy来获取网站的招聘信息,并且保存至MySQL数据库,与上一篇文章有所差异,下面进入正题:
直聘网的信息也比较权威、质量,但是反爬虫的有点厉害,做了很多的措施,但时不时还是六字真言教你做人:

本来比较简单的网页硬是用了两天才爬完,第一天就把IP给我封了。说多了都,哎不说了。
首先我们来分析一下需要爬取得网页信息:
https://www.zhipin.com/c100010000/h_101270100/?ka=sel-city-100010000
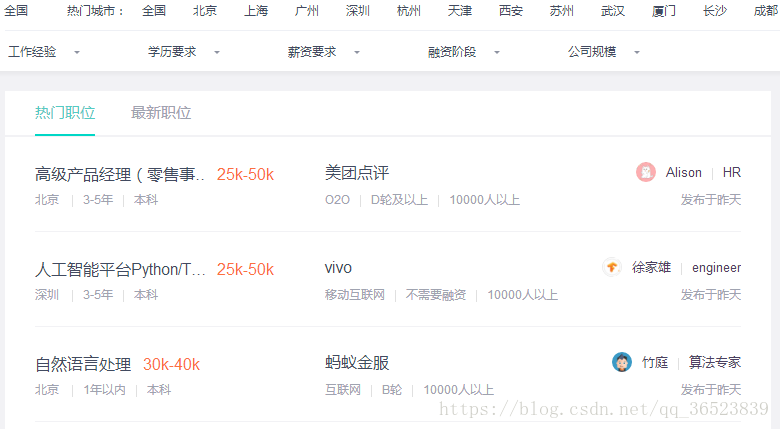
下面这个招聘信息就是我们后面要获取的信息,获取的内容包括(城市、规模、学历、领域、职位、薪水、工作经验等7个内容)
又与年轻了,想着这个网页,获取到链接就可以直接爬了,还比较简单,刚爬了没一分钟,就没数据了,我还以为代码bug了,刷新一下网页,竟然连我的IP都给封了,由于更换IP来反爬虫有点麻烦,就没有搞了,休息一天,本来就有点累了。
第二天开始了小心翼翼的工作,需要处理的就是伪造浏览器信息,和设置爬取速度,来防止正义制裁:
不停的更换user_agent:
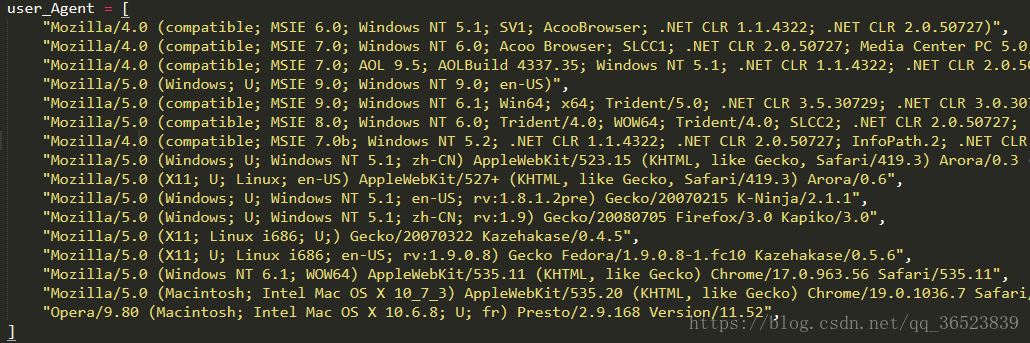
列一长串出来,后面我们随机选取。
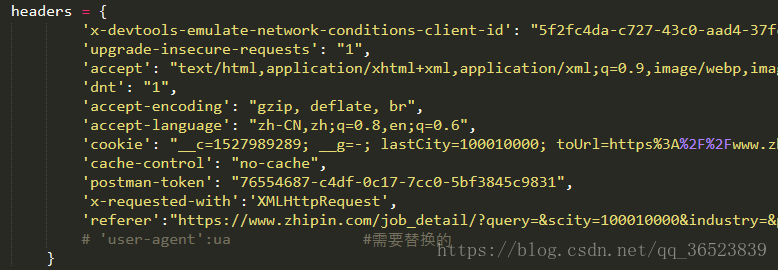
headers的设置,这个在F12的Network的数据包中查找到:
慢慢找嘛
import time time.sleep(8)很重要,每次请求都慢一点,让他缓缓,这里我设置的8秒,因为我比较害怕,又被封了。
还有在setting中开启某些设置(下载延迟等也是一个措施):
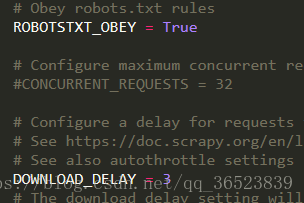
好了简单有效的措施我们都做了,下面就开始创建scrapy来爬取
创建scrapy(不累述,如果不清楚可以先查阅一下资料):
我们先编写容器文件,以便确定我们需要获取的信息(这里我在items里面新建的类,也可以使用原来的):
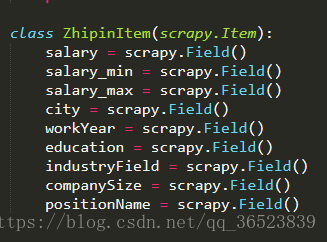
接着我们来编写spider文件:
spider源码:(首先爬取全国,然后爬取14个热门城市)
# -*- coding: utf-8 -*-
import scrapy
import time
import random
import os
path = os.path.abspath(os.path.join(os.getcwd(), "../.."))
import sys
sys.path.append(path)
from get_zhipin.items import ZhipinItem
import main
user_Agent = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
]
headers = {
'x-devtools-emulate-network-conditions-client-id': "5f2fc4da-c727-43c0-aad4-37fce8e3ff39",
'upgrade-insecure-requests': "1",
'accept': "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
'dnt': "1",
'accept-encoding': "gzip, deflate, br",
'accept-language': "zh-CN,zh;q=0.8,en;q=0.6",
'cookie': "__c=1527989289; __g=-; lastCity=100010000; toUrl=https%3A%2F%2Fwww.zhipin.com%2Fjob_detail%2Fc77944563dd5cc1a1XV70tW0ElM%7E.html%3Fka%3Dsearch_list_1_blank%26lid%3DTvnYVWp16I.search; JSESSIONID=""; __l=l=%2Fwww.zhipin.com%2F&r=; __a=33024288.1527773672.1527940079.1527989289.90.5.22.74; Hm_lvt_194df3105ad7148dcf2b98a91b5e727a=1527774077,1527835258,1527940079,1527989289; Hm_lpvt_194df3105ad7148dcf2b98a91b5e727a=1527991981",
'cache-control': "no-cache",
'postman-token': "76554687-c4df-0c17-7cc0-5bf3845c9831",
'x-requested-with':'XMLHttpRequest',
'referer':"https://www.zhipin.com/job_detail/?query=&scity=100010000&industry=&position="
# 'user-agent':ua #需要替换的
}
class ZhipinSpider(scrapy.Spider):
name = 'zhipin'
main_url = 'https://www.zhipin.com/c100010000/h_100010000/?' #全国页第一次使用
url1 = 'https://www.zhipin.com' #用来做拼接
page = 1 #控制爬取页数
key = 0 #区分全国页和其他城市页
countrys = [] #记录城市部分链接
countrys_name = [] #记录城市名
country_num = 0 #用来提取城市链接的下标
flag = 0 #区分全国页和其他城市页
def parse(self, response):
if(self.key == 0): #初次爬取时获得所有城市的链接以及名字,后面用来拼接链接用
self.key+=1
for i in range(3,16):
country = response.xpath('//*[@id="filter-box"]/div/div[2]/dl/dd/a[{}]//@href'.format(str(i))).extract()[0]
self.countrys.append(country)
country_name = response.xpath('//*[@id="filter-box"]/div/div[2]/dl/dd/a[{}]/text()'.format(str(i))).extract()[0]
self.countrys_name.append(country_name)
item = ZhipinItem()
for i in range(1,31): #记得每次匹配到数据都判断下有没有值,有的网页信息为空值,我用try有问题,优先使用try
city = response.xpath('//*[@id="main"]/div/div[2]/ul/li[{}]/div/div[1]/p/text()[1]'.format(str(i))).extract()
if(city):
city = city[0].split()[0]
else:
city = None
workYear = response.xpath('//*[@id="main"]/div/div[2]/ul/li[{}]/div/div[1]/p/text()[2]'.format(str(i))).extract()
if(workYear):
workYear = workYear[0]
else:
workYear = None
education = response.xpath('//*[@id="main"]/div/div[2]/ul/li[{}]/div/div[1]/p/text()[3]'.format(str(i))).extract()
if(education):
education = education[0]
else:
education = None
positionName = response.xpath('//*[@id="main"]/div/div[2]/ul/li[{}]/div/div[1]/h3/a/div[1]/text()'.format(str(i))).extract()
if(positionName):
positionName = positionName
else:
positionName = None
salary = response.xpath('//*[@id="main"]/div/div[2]/ul/li[{}]/div/div[1]/h3/a/span/text()'.format(str(i))).extract()
if(salary):
sal = salary[0].split('-')
if(len(sal)==1):
salary = salary[0]
salary_min = sal[0][:sal[0].find('k')] #这里获得最大最小薪水
salary_max = sal[0][:sal[0].find('k')]
else:
salary = salary[0]
salary_min = sal[0][:sal[0].find('k')]
salary_max = sal[1][:sal[1].find('k')]
else:
salary = None
salary_min = None
salary_max = None
industryField = response.xpath('//*[@id="main"]/div/div[2]/ul/li[{}]/div/div[2]/div/p/text()[1]'.format(str(i))).extract()
if(industryField):
industryField = industryField[0]
else:
industryField = None
companySize = response.xpath('//*[@id="main"]/div/div[2]/ul/li[{}]/div/div[2]/div/p/text()[3]'.format(str(i))).extract()
if(not companySize):
companySize = response.xpath('//*[@id="main"]/div/div[2]/ul/li[{}]/div/div[2]/div/p/text()[2]'.format(str(i))).extract()
if(companySize):
companySize = companySize[0]
else:
companySize = None
item['salary'] = salary
item['city'] = city
item['workYear'] = workYear
item['education'] = education
item['industryField'] = industryField
item['companySize'] = companySize
item['positionName'] = positionName
item['salary_min'] = salary_min
item['salary_max'] = salary_max
yield item
if(self.page < 10): #该城市的所有页面爬取
print("pn:{}运行中请勿打断...".format(self.page+1))
self.page +=1 #这里先加再用
if(self.flag == 0): #第一次和其他次的使用链接格式有区别,没有优化这里
link = self.main_url+('page={}&ka=page-{}'.format(str(self.page),str(self.page)))
else:
link = self.url1+self.countrys[self.country_num]+('?page={}&ka=page-{}'.format(str(self.page),str(self.page)))
ua = random.choice(user_Agent)
headers['user-agent'] = ua
time.sleep(8)
yield scrapy.http.FormRequest(url=link,headers=headers,callback=self.parse)
else: #切换到其余的热门城市
self.page = 1 #!!!千万记住这里要初始化页数,不然不会进入上面的if判断
self.flag = 1
if(self.country_num >= len(self.countrys)):
print("爬虫已结束运行^.^")
else:
print("热门城市 ->{}<-,切换中...".format(self.countrys_name[self.country_num]))
link = self.url1+self.countrys[self.country_num]+"?page=1&ka=page-1"
self.country_num +=1 #这里先用在加
ua = random.choice(user_Agent)
headers['user-agent'] = ua
time.sleep(8)
yield scrapy.http.FormRequest(url=link,headers=headers,callback=self.parse)
def start_requests(self): #首页 全国置为初始链接
url = 'https://www.zhipin.com/c100010000/h_100010000/?page=1&ka=page-1'
ua = random.choice(user_Agent) #随机选择一个user_agent
headers['user-agent'] = ua
return [scrapy.http.FormRequest(url=url,headers=headers,callback=self.parse)] #这里使用列表是因为传入的值必须是可迭代的这篇文章的spider相对上一篇要麻烦一点,因为要获得子网页,转变链接格式,使用的yield也更多了,代码量中等。但是整体的思路还是很简单的。有的网页信息不全,要做还异常处理,免得程序中断。
首先我们使用start_requests来请求第一页信息,返回至parse函数中,然后在parse中通过判断当前页数,来确定是否继续爬取网页。需要注意的上面的文件中我们导入了之前创建的容器类LagouItem()。os.path.abspath是我用来导入上上层文件的路径,sys.path我用来添加main.py和items.py文件的路径,main.py中,就是执行scraoy的命令,你也可以在cmd中执行scrapy,我之前的文章有介绍很方便的。spider很简单,代码不多,我们介绍pipelines文件。
pipelines源码:
import pymysql
import re
class GetZhipinPipeline(object):
def table_exists(self,con,table_name):
sql = "show tables;" #第一次使用需要将数据表删除
con.execute(sql)
tables = [con.fetchall()]
table_list = re.findall('(\'.*?\')',str(tables))
table_list = [re.sub("'",'',each) for each in table_list]
if table_name in table_list:
return 1
else:
return 0
def process_item(self, item, spider):
connect = pymysql.connect(
user = 'root',
password = 'root@123456',
db = 'MYSQL',
host = '127.0.0.1',
port = 3306,
charset = 'utf8'
)
con = connect.cursor()
con.execute("use w_lagouwang")
table_name = 'zhipinwang' #这张表是用来测试所有数据的 并非关键词表
if(self.table_exists(con,table_name) != 1):
# con.execute("drop table if exists zhipinwang")
sql = '''create table zhipinwang(city varchar(20),companySize varchar(20),education varchar(20),
industryField varchar(30),positionName varchar(40),salary varchar(20),salary_max varchar(10),salary_min varchar(10),
workYear varchar(20))'''
con.execute(sql)
data = {'city':item['city'],'companySize':item['companySize'],'education':item['education'],
'industryField':item['industryField'],'positionName':item['positionName'],'salary':item['salary'],
'salary_max':item['salary_max'],'salary_min':item['salary_min'],'workYear':item['workYear']}
city = data['city']
companySize = data['companySize']
education = data['education']
industryField = data['industryField']
positionName = data['positionName']
salary = data['salary']
salary_max = data['salary_max']
salary_min = data['salary_min']
workYear = data['workYear']
con.execute('insert into zhipinwang(city,companySize,education,industryField,positionName,salary,salary_max,salary_min,workYear)values(%s,%s,%s,%s,%s,%s,%s,%s,%s)',
[city,companySize,education,industryField,positionName,salary,salary_max,salary_min,workYear])
connect.commit()
con.close()
connect.close()
return data其实很简单的,就是sql语句有点多,和一个判断表的函数,真正的代码不多。
好了,接下来就是运行了,等等我们先配置一下setting文件:

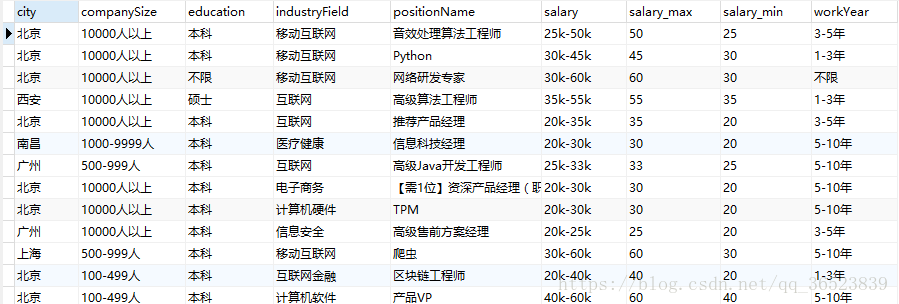
大致数据像上面,对于上面的数据我还做过一点处理,但是不影响上面的操作。
好了直聘网反爬虫的项目就完成了,可以看出还是挺简单的,只是每一步都有需要细心,还有就是注意文件之间的关联性,其他的就没有了。反爬虫其实还有很多种,这里只是一种,在接下来的几篇文章中我还会介绍爬取 拉勾网,猎聘网等,都有反爬虫机制。有问题的朋友可以留言交流。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









