




 本文介绍了通过keras实现MNIST手写数字识别的步骤,包括模型定义、优化器选择和训练策略。讨论了SGD与Mini-batch的区别,并给出了训练深度神经网络的实用技巧,如激活函数选择、防止过拟合的方法。
本文介绍了通过keras实现MNIST手写数字识别的步骤,包括模型定义、优化器选择和训练策略。讨论了SGD与Mini-batch的区别,并给出了训练深度神经网络的实用技巧,如激活函数选择、防止过拟合的方法。
学习编程语言时,我们学的第一个问题都是输出“hello world”,毫不夸张的说,MNIST就是深度学习版的“hello word”。这节课将通过keras实现MNIST手写数字识别这个经典案例,并且在实践过程中总结深度学习调参的一般套路。
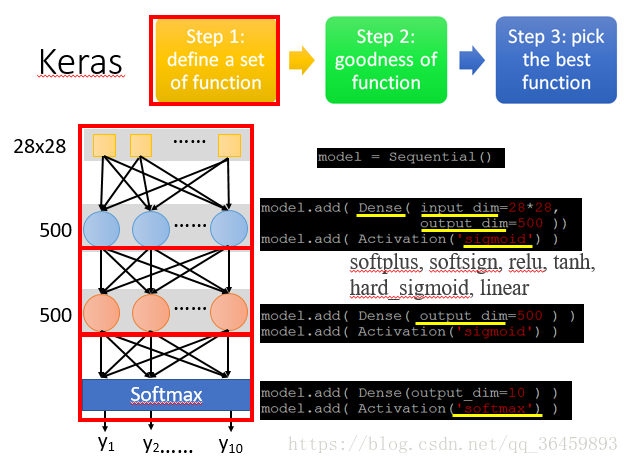
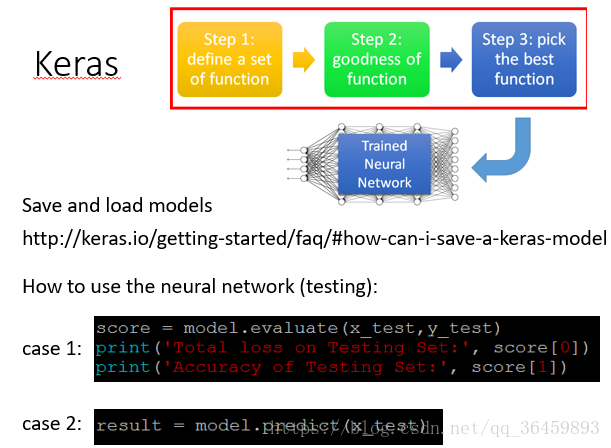
一、利用keras进行深度学习的一般步骤
step1: define a set of function
这一步决定神经网络的结构,也是编写程序最重要的一步。常用的参数包括神经网络的层数,每一层神经元个数,激活函数的选择等等。常见的激活函数在下图中已列出。
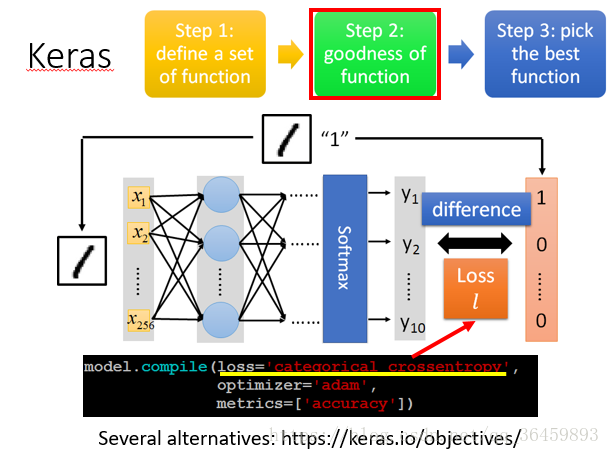
step 2: goodness of function
这一步要定义合适的损失函数,以及相应accuracy(optimazer指定求解的方法,归入第三步)。
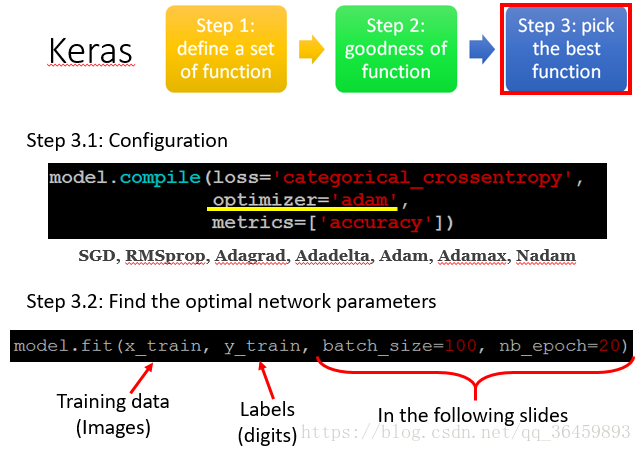
step 3: pick the best function
选定optimezer,实际上是选择梯度下降的各种方法。之后需选择batch_size和no_epoch,决定神经网络训练的batch大小和训练的轮数。
模型训练完成后,就可以用来测试啦。这里有两种测试情境,一种是带标记的(evaluate),一种是不带标记的(predict)。
一个batch是进行一次参数更新所需的样本子集,将所有batch都训练完的一轮就是一个epoch。
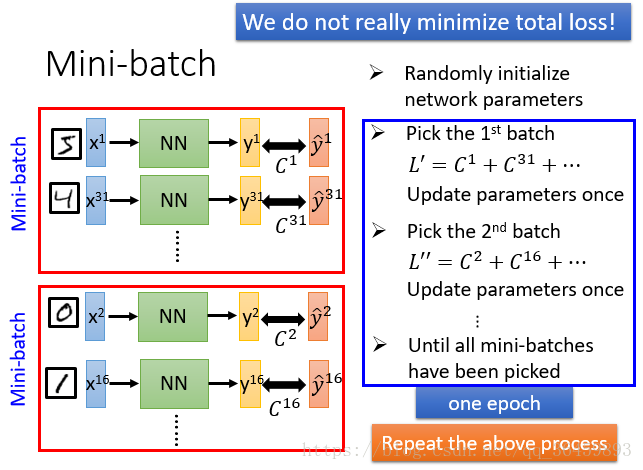
二、SG
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









