







 本文详细探讨了Hive的元数据存储机制,包括Dbs、Version、Tbls等核心概念,以及mapjoin和reducejoin的执行流程对比。同时,深入介绍了SparkSQL的执行原理与Catalyst优化,讨论了谓词下推的重要性。此外,还讲解了UDF的使用,以及如何在Hive和Spark中创建和使用自定义函数。
本文详细探讨了Hive的元数据存储机制,包括Dbs、Version、Tbls等核心概念,以及mapjoin和reducejoin的执行流程对比。同时,深入介绍了SparkSQL的执行原理与Catalyst优化,讨论了谓词下推的重要性。此外,还讲解了UDF的使用,以及如何在Hive和Spark中创建和使用自定义函数。
文章目录
hive的MetaStore信息
进入Mysql对应的database
Dbs
存的database的创建信息
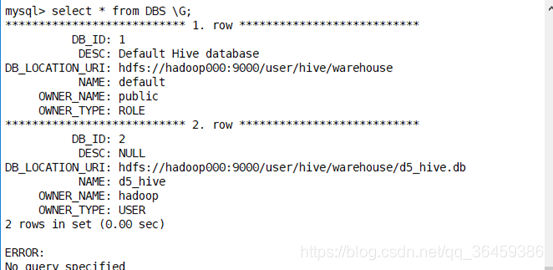
Version
这里的数据有且仅有1条时,hive才能启动起来
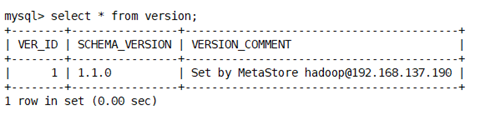
Tbls
存表的创建信息
TBL_ID 表ID
DB_ID对应database的id
SD_ID 序列化配置信息
Table_params
表的具体信息
TBL_ID关联

Cds
Sds
表的压缩和格式文件存储的基本信息
通过CD_ID字段信息ID
和上表关联
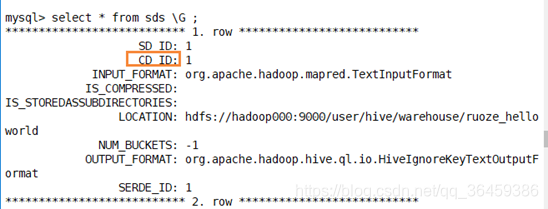
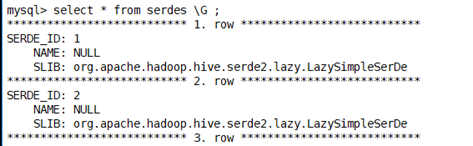
Serdes
表的序列化方式
通过serde_id序列化类ID关联
Columns_v2
存表的字段信息
Interger_idx代表字段顺序,0代表表里第1个字段

Partitions
存分区信息
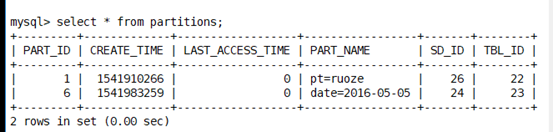
Partition_keys
分区的字段属性

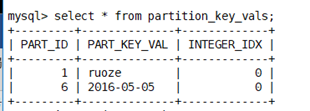
Partition_key_vals
存分区的值
https://www.cnblogs.com/1130136248wlxk/articles/5517909.html
细谈join
假设我们做下面的sql语句
JOIN:
select
e.empno,e.ename,e.deptno, d.dname
from
ruoze_emp e join ruoze_dept d
on e.deptno=d.deptno;
mapreduce里实现
-
a: 读取数据 <deptno,(e.empno,e.ename)>
b: 读取数据 <deptno,(d.dname)> -
join,把相同key的放到一起
<deptno,((e.empno,e.ename,e.deptno),(d.dname))>这个过程要shuffle,shuffle最终结果在reduce端完成,这种join通常叫Common Join/Reduce Join/Shuffle Join
执行流程
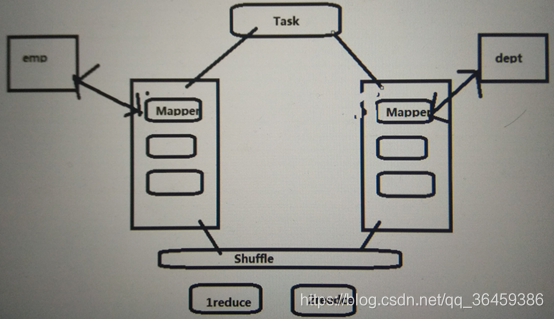
执行计划里有3部分内容
- 抽象语法树 需要在explain 后面加extended
- 不同stage之间的依赖关系
- 每个stage的描述
在Hive里查看执行计划
导入数据到emp和dept
sqoop import \
--connect jdbc:mysql://localhost:3306/ruozedb \
--username root \
--password 123456 \
--table dept \
--delete-target-dir \
--hive-import \
--hive-table ruoze_dept \
--fields-terminated-by '\t' \
--hive-overwrite \
-m 1
默认情况下不是使用这种join,改下参数
hive (default)> set hive.auto.convert.join;
hive.auto.convert.join=true
hive (default)> set hive.auto.convert.join = false;
hive (default)> set hive.auto.convert.join;
hive.auto.convert.join=false
执行计划语句
Explain
select a.empno,a.ename,a.deptno, d.dname
from ruoze_emp a join ruoze_dept d
on a.deptno=d.deptno;
输出



Map结束后reduce
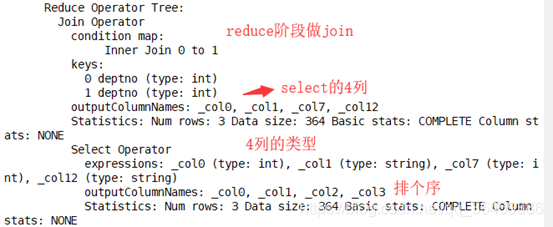
结果输出
mapjoin
执行流程
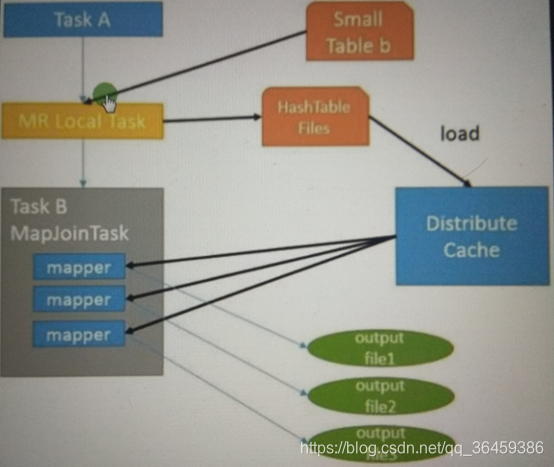
MR Local Task 把小表数据读进来,生成一个HashTable Files,加载文件到Distribbute cache(分布式缓存)
TaskB读大表数据,和小表的数据做匹配,匹配的上就留,匹配不上就走。
执行计划
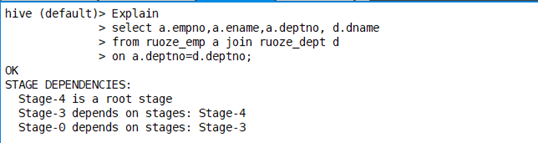
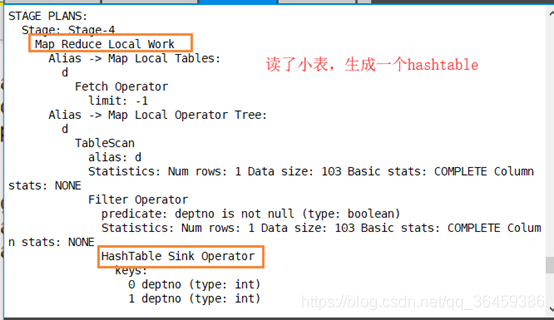
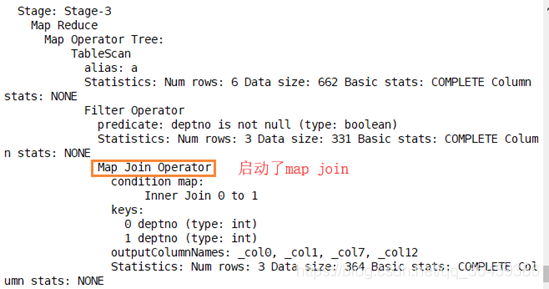
看hashtable
直接执行代码,看日志
select a.empno,a.ename,a.deptno, d.dname
from ruoze_emp a join ruoze_dept d
on a.deptno=d.deptno;
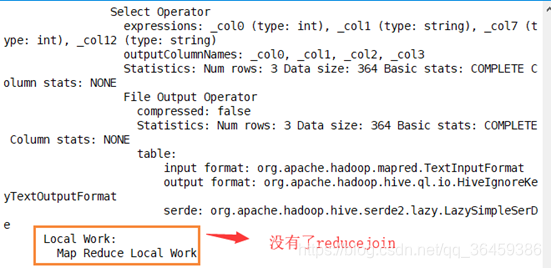
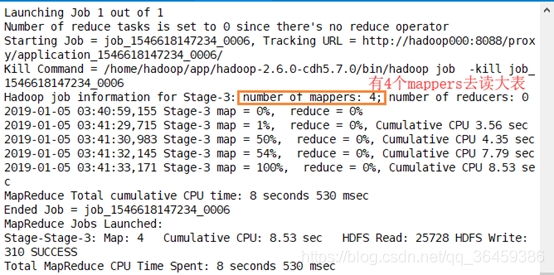
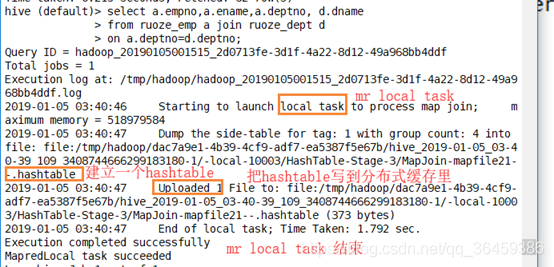 没有reducer,说明没有reducejoin,没有shuffle和reduce.
没有reducer,说明没有reducejoin,没有shuffle和reduce.
没有shuffle就没有reduce,因为数据归约在map阶段就做了,并且直接输出到文件
这样写也可以
Explain
select /*+ MAPJOIN(d) */
a.empno,a.ename,a.deptno, d.dname
from ruoze_emp a join ruoze_dept d
on a.deptno=d.deptno;
UDF 用户定义函数
UDF 一进一出 upper,lower
UDAF 多进一出 sum,map
UDTF 一进多出 lateral view explode
查看内置函数
hive (default)> show functions;
Pom.xml添加hive依赖
<hive.version>1.1.0-cdh5.7.0</hive.version>
<dependency>
<groupId>org.appche.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>${hive.version}</version>
</dependency>
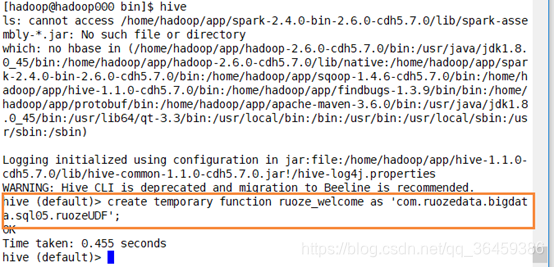
在Hive里,创建临时函数
Add jar /home/hadoop/data/g5-spark-1.0.jar;
create temporary function ruoze_welcome as 'com.ruozedata.bigdata.sql05.ruozeUDF';
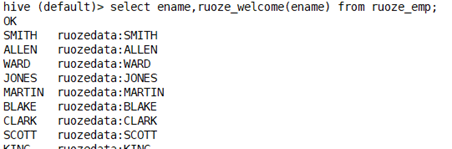
临时函数生命周期只在当前窗口有效

关掉hive
在hive目录下创建一个文件夹用来放jar包
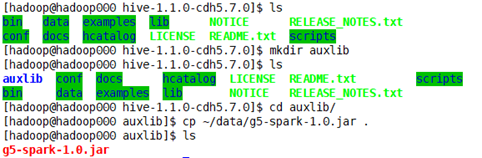
这样的话,启动hive,不需要add了
永久函数
就是把函数注册到metastore
现在

先把jar包放到hdfs上
[hadoop@hadoop000 data]$ hadoop fs -put g5-spark-1.0.jar /lib/ g5-spark-1.0.jar
然后hive里
create function ruoze_hello as 'com.ruozedata.bigdata.sql05.ruozeUDF' using jar 'hdfs://hadoop000:9000/lib/g5-spark-1.0.jar';
metastore已有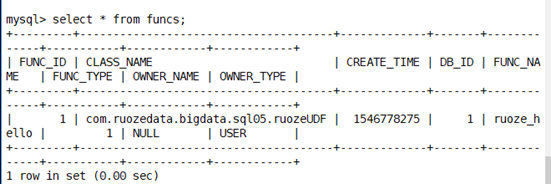
Sparksql执行底层与catalys优化
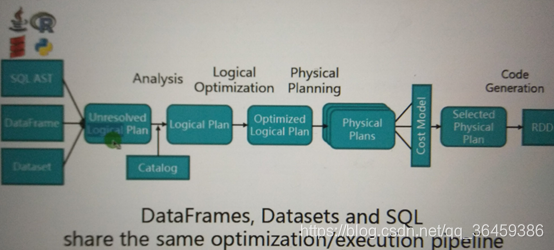
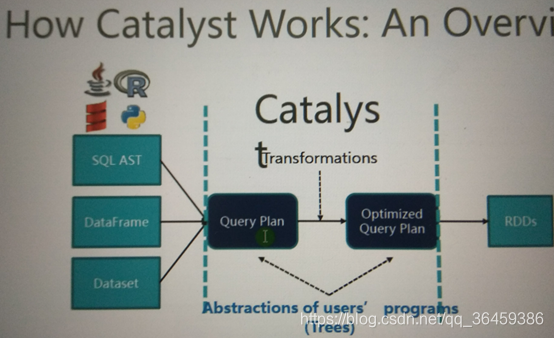
假如执行下面语句
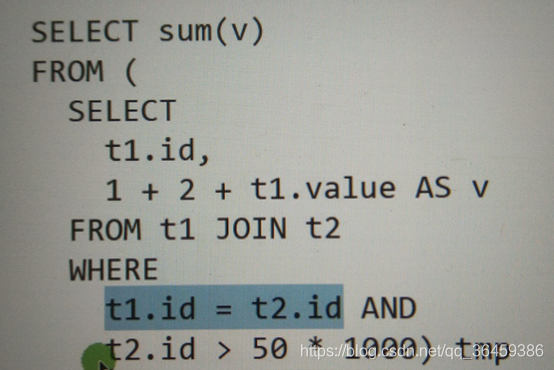
表达式就是一个基于输入值就算出来的东东,比如sum和v

逻辑执行计划,只是规化,但不计算
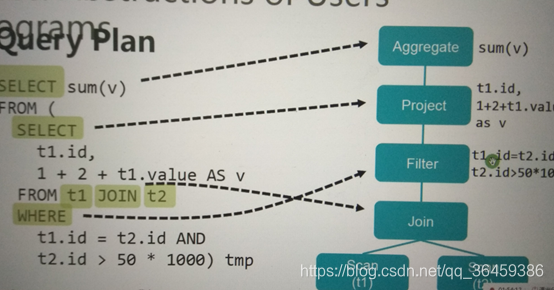
物理执行计划
明确如何计算

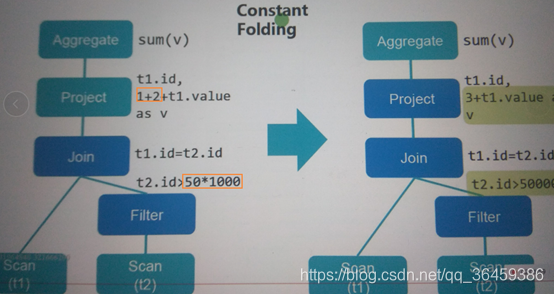
1+2明显是常量,不需要每次都重新计算,计算一次即可
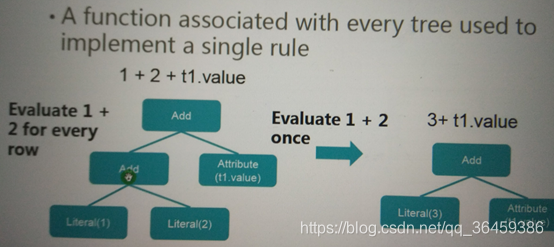
如果遇到两个int类型,直接相加

谓词下压
过滤完再join,数据更少,更快
我们知道,可以通过封装SparkSql的Data Source API完成各类数据源的查询,那么如果底层数据源无法高效完成数据的过滤,就会执行直接的全局扫描,把每条相关的数据都交给SparkSql的Filter操作符完成过滤,虽然SparkSql使用的Code Generation技术极大的提高了数据过滤的效率,但是这个过程无法避免大量数据的磁盘读取,甚至在某些情况下会涉及网络IO(例如数据非本地化时);如果底层数据源在进行扫描时能非常快速的完成数据的过滤,那么就会把过滤交给底层数据源来完成,这就是SparkSql中的谓词下推。
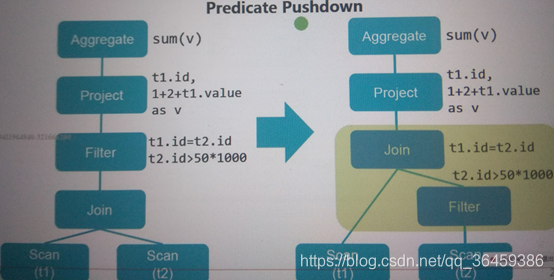
常量计算一次转换
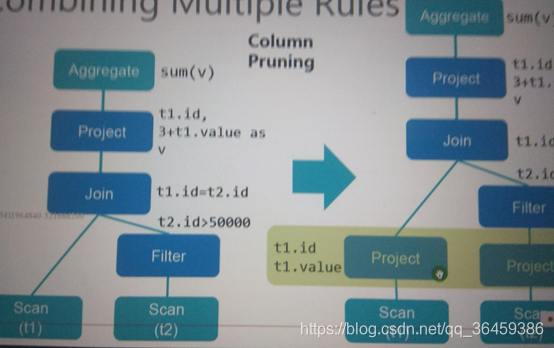
提前列裁剪
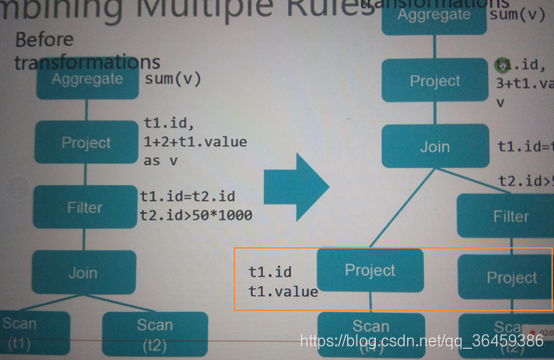
综合起来就是这样
在sql里查看执行计划
Sql语句后面加个 .explain或者.explain(true)
前者只有物理,后者有逻辑执行计划

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









