







 本文介绍了在项目和测试中如何使用Scala和Java来操作HDFS。在没有明确指定Hadoop配置的情况下,默认使用本地环境。同时,文章强调了在Windows和Linux上配置hadoop000的重要性。
本文介绍了在项目和测试中如何使用Scala和Java来操作HDFS。在没有明确指定Hadoop配置的情况下,默认使用本地环境。同时,文章强调了在Windows和Linux上配置hadoop000的重要性。
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
在pom.xml里加入这段依赖
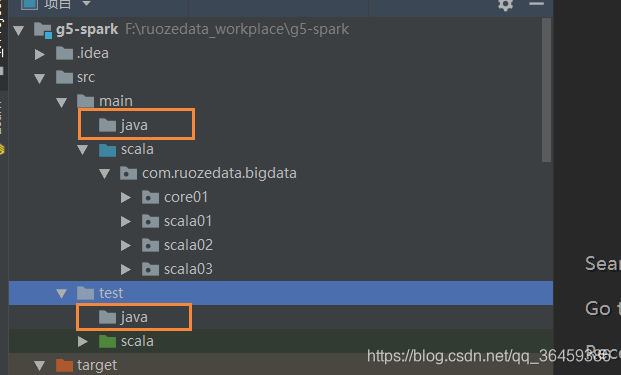 项目和测试里都建立java目录
项目和测试里都建立java目录
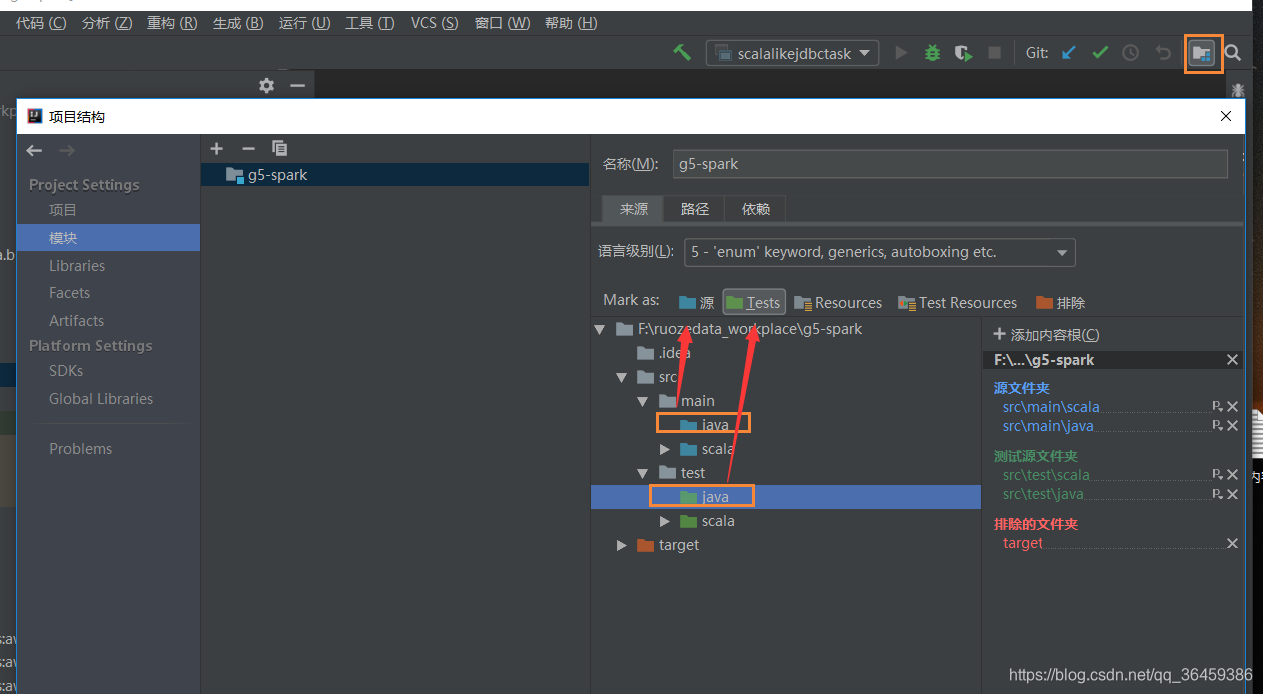 设置
设置
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.junit.*;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
//java操作hdfs
public class HDFSApp {
Configuration configuration ;
URI uri;
FileSystem fileSystem;
//有些时候,一些测试需要共享代价高昂的步骤(如数据库登录),这会破坏测试独立性,通常是需要优化的。
使用@BeforeClass注解一个public static void 方法,并且该方法不带任何参数,会使该方法在所有测试方法被执行前执行一次,并且只执行一次。
父类的@BeforeClass注解方法会在子类的@BeforeClass注解方法执行前执行。
@BeforeClass
public static void begin(){
System.out.println("begin");
}
//如果在@BeforeClass注解方法中分配了代价高昂的额外的资源,那么在测试类中的所有测试方法执行完后,需要释放分配的资源。
使用@AfterClass注解一个public static void方法会使该方法在测试类中的所有测试方法执行完后被执行。
即使在@BeforeClass注解方法中抛出了异常,所有的@AfterClass注解方法依然会被执行。
父类中的@AfterClass注解方法会在子类@AfterClass注解方法执行后被执行。
@AfterClass
public static void stop(){
System.out.println("stop");
}
//使用@Before注解一个public void 方法会使该方法在每个@Test注解方法被执行前执行
@Before
public void setUp(){
System.out.println("setUp");
//设置连接的参数的
configuration = new Configuration();
//这个是设置hdfs副本数,不设置的话,用这种操作会默认3副本
configuration.set("dfs.replication","1");
try {
uri = new URI("hdfs://hadoop000:8020");
//后面加hadoop就是以什么用户访问,默认是当前电脑用户
fileSystem = FileSystem.get(uri,configuration,"hadoop");
} catch (Exception e) {
e.printStackTrace();
}
}
@After
public void tearDown(){
System.out.println("tearDown");
try {
fileSystem.close();
} catch (IOException e) {
e.printStackTrace();
}
}
//使用@After注解一个public void方法会使该方法在每个@Test注解方法执行后被执行
@Test
public void test01() throws Exception{
//操作hdfs创建文件夹咯
fileSystem.mkdirs(new Path("/g5"));
}
//@Test注解的public void方法将会被当做测试用例,JUnit每次都会创建一个新的测试实例,然后调用@Test注解方法,任何异常的抛出都会认为测试失败。所以throw掉。
//如果在@Before注解方法中分配了额外的资源,那么在测试执行完后,需要释放分配的资源,这个释放资源的操作可以在After中完成。
@Test
public void test02() throws Exception{
输出到文件
FSDataOutputStream out = fileSystem.create(new Path("/g5/test/ruozedata-hadoop.txt"));
out.writeUTF("ruoze");
out.writeUTF("J总");
out.flush();
out.close();
}
@Test
public void test03() throws Exception {
FSDataInputStream in = fileSystem.open(new Path("/g5/test/ruozedata-hadoop.txt"));
//--in:是FSDataInputStream类的对象,是有关读取文件的类,也就是所谓“输入流”
//--out:是FSDataOutputStream类的对象,是有关文件写入的类,也就是“输出流”
//--4096表示用来拷贝的buffer大小(buffer是缓冲区)--缓冲区大小
//把文件读到控制台
IOUtils.copyBytes(in, System.out, 1024);
}
@Test
public void test04() throws Exception {
//改名字
fileSystem.rename(new Path("/g5/test/ruozedata-hadoop.txt"),
new Path("/g5/test/ruozedata-hadoop.txt-bak"));
// local ==> hdfs
fileSystem.copyFromLocalFile(new Path(""), new Path(""));
// hdfs ==> local
fileSystem.copyToLocalFile(new Path(""), new Path(""));
//遍历一个路径,是否递归
fileSystem.listFiles(new Path(""), true);
fileSystem.delete(new Path(""),true);
}
}
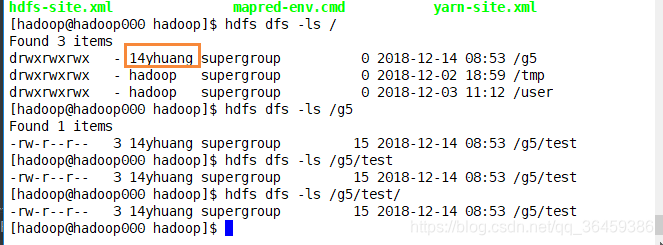
我电脑是14yhuang,所以这里如果没指定hadoop就是本机。
scala写法
import java.net.URI
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FSDataInputStream, FileSystem, Path}
import org.apache.hadoop.io.IOUtils
object HDFSApp1 {
def main(args: Array[String]): Unit = {
val configuration = new Configuration
val uri = new URI("hdfs://192.168.137.190:9000" )
val fileSystem = FileSystem.get(uri,configuration,"hadoop")
val in:FSDataInputStream = fileSystem.open(new Path("/g5/asd.txt"))
IOUtils.copyBytes(in,System.out,1024)
val flag = fileSystem.delete(new Path("/g5/test"),true)
println(flag)
}
}
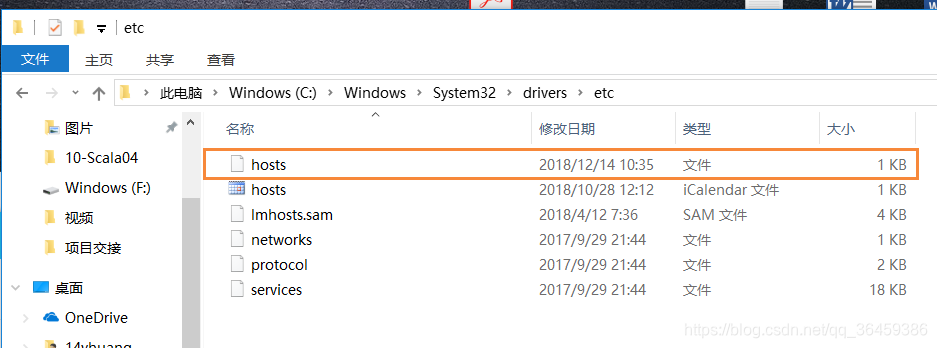
hadoop000不仅要配置在linux上,在win上也要配置。

















 1665
1665

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









