




 本文深入解析HDFS的架构特点,包括主从结构、数据冗余保存机制、NameNode和DataNode的角色职责,以及SecondaryNameNode如何协助解决EditLog过大问题。了解HDFS如何通过多副本方式保障数据可靠性。
本文深入解析HDFS的架构特点,包括主从结构、数据冗余保存机制、NameNode和DataNode的角色职责,以及SecondaryNameNode如何协助解决EditLog过大问题。了解HDFS如何通过多副本方式保障数据可靠性。
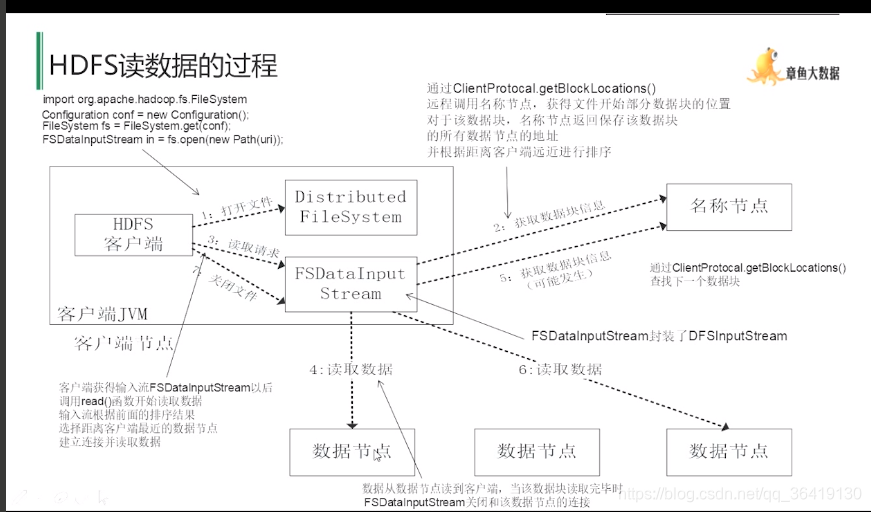
HDFS工作原理
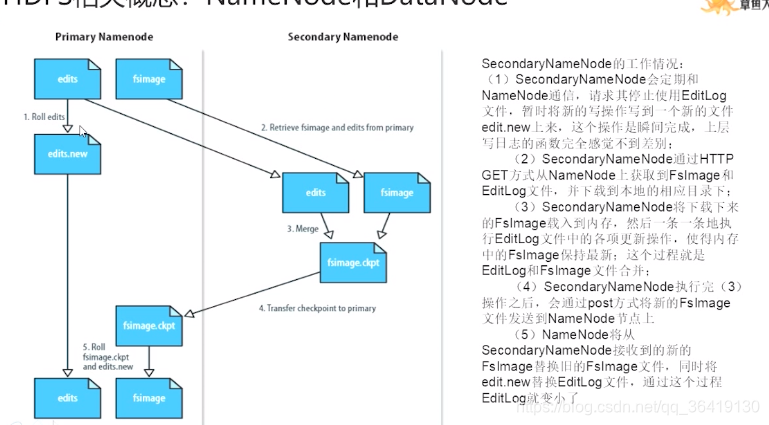
NameNode和Sencondary NameNode节点通过HTTP GET(N->S)和POST(S->N)发送和接受数据
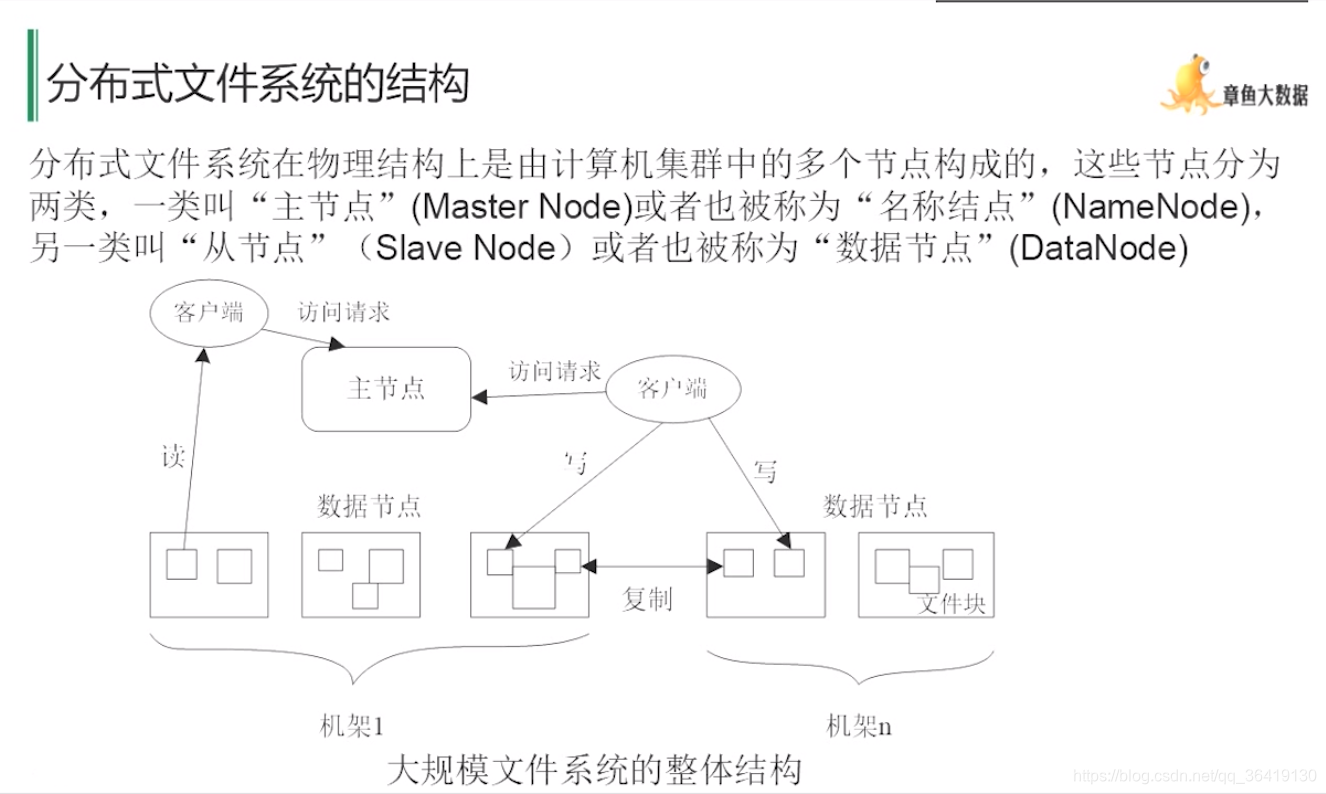
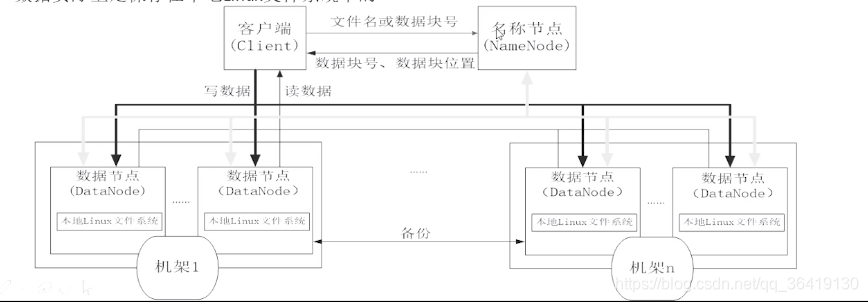
体系结构,主从(master/slave)
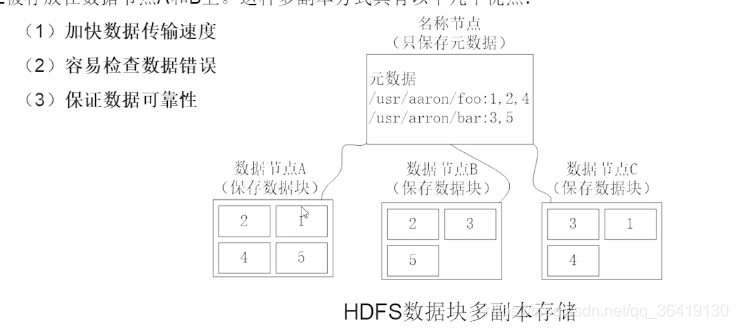
存储原理:冗余数据保存(多副本)
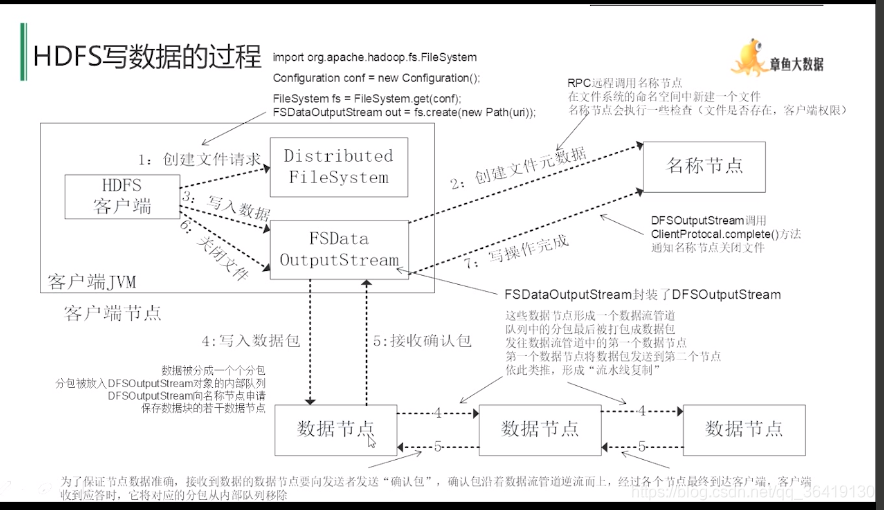
HDFS 实现目标

HDFS 相关概念
块
默认128M

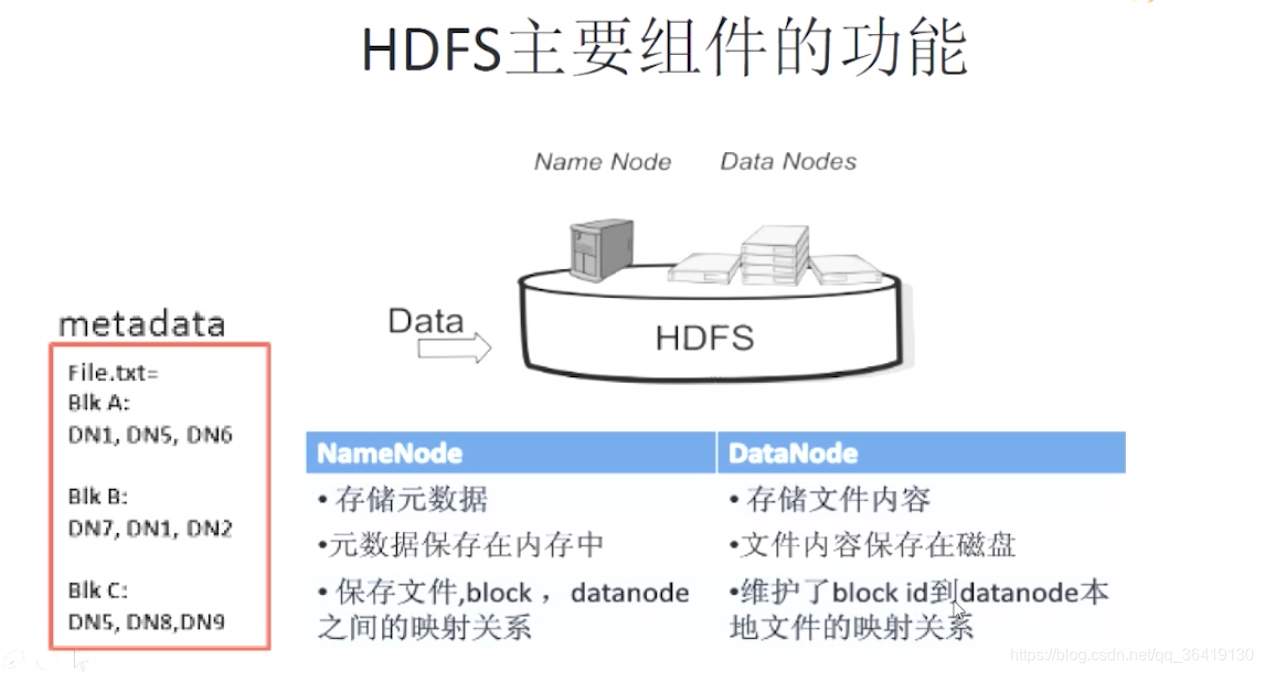
NameNode
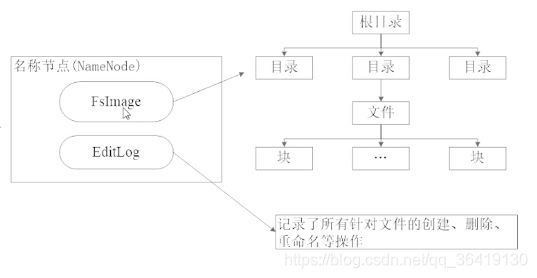
FsImage

namenode节点启动时,会将fsimage中的内容加载到内存中,执行editlog中的步骤
Editlog
Secondary Namenode(冷备份)
定时向primary namenode 请求fsimage和editlog,避免namenode因运行时间过多而导致的editlog文件过大的问题
DataNode
HDFS的工作节点,负责存储数据和读取数据,根据客户端或者namenode的调度,并定期向datanode发送自己存储的数据块信息

















 1581
1581

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









