




 本文通过debug简单使用代码的方式,探索了ArrayDeque数据结构的底层实现原理。ArrayDeque既可以用作堆栈也可以用作队列,其底层实现为数组,初始容量为16。文章详细介绍了addFirst、addLast、pollFirst等核心方法的工作机制。
本文通过debug简单使用代码的方式,探索了ArrayDeque数据结构的底层实现原理。ArrayDeque既可以用作堆栈也可以用作队列,其底层实现为数组,初始容量为16。文章详细介绍了addFirst、addLast、pollFirst等核心方法的工作机制。
今天在学习深度优先和广度优先遍历树的时候,发现了一个非常牛逼的数据结构,它就是ArrayDeque,这个数据结构既可以当成堆栈使用,又可以当成队列来使用。接下来通过debug一些简单的使用代码来探索一下ArrayDeque的底层实现原理。
首先,我的简明测试如下:

在debug的过程中,我发现在ss和ss1的数据组成里面,相同值所在的地址是一样的,类似与String类,这是Integer常量的缓存特性。跟踪它的初始化:
elements = new Object[16];这个反映出这个数据结构的底层实现实际上是数组,而且在没有指定容量的条件下初始容量为16.,然后是作为栈使用的push方法,先把push的值转为Integer(范围-128 ~127),然后跳转到addFirst方法:
public void addFirst(E e) {
if (e == null)
throw new NullPointerException();
elements[head = (head - 1) & (elements.length - 1)] = e; //将head的指针减一后 将数据存入---1
if (head == tail)
doubleCapacity(); 如果指针相遇,意味着里面没有东西------2
}1----这个意味着堆栈的使用是以head节点作为栈顶来使用的
2----这时候这个数据结构为空,所以需要重新初始化一个数组给它,具体代码如下:
private void doubleCapacity() {
assert head == tail;
int p = head;
int n = elements.length;
int r = n - p; // number of elements to the right of p
int newCapacity = n << 1;
if (newCapacity < 0)
throw new IllegalStateException("Sorry, deque too big");
Object[] a = new Object[newCapacity];
System.arraycopy(elements, p, a, 0, r); //native方法,通过地址实现内存复制
System.arraycopy(elements, 0, a, r, p);
elements = a;
head = 0;
tail = n;
}作为堆栈使用的pop()方法直接来到了removeFirst()-->pollFirst():
public E pollFirst() {
int h = head;
@SuppressWarnings("unchecked")
E result = (E) elements[h]; //取head指向的值
// Element is null if deque empty
if (result == null)
return null;
elements[h] = null; // Must null out slot
head = (h + 1) & (elements.length - 1); //head++
return result;
}同理,add方法直接跳转到addLast:
public void addLast(E e) {
if (e == null)
throw new NullPointerException();
elements[tail] = e;
if ( (tail = (tail + 1) & (elements.length - 1)) == head) //在数组的末尾添加元素
doubleCapacity();
}添加成功后还会返回true。remove方法直接来到了removeFirst()-->pollFirst()--同pop一致!!!
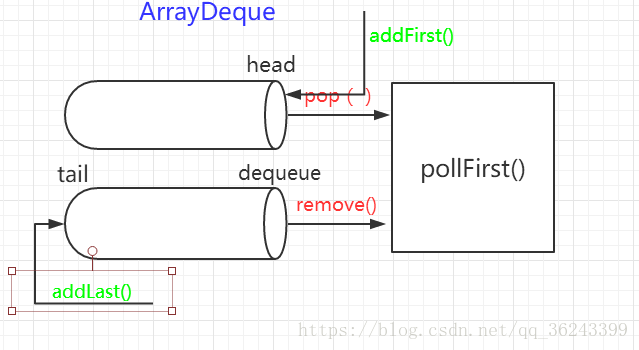
总结以上:基本上可以画出一个基本的实现图:

















 748
748

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









