




 本文深入探讨Solr的四种缓存机制:filterCache、queryResultCache、documentCache及调整策略。filterCache存储无序documentid集合,适用于facet查询;queryResultCache缓存查询结果,提升分页性能;documentCache保存<doc_id,document>对,加速频繁请求的Document读取。文章还提供了调整缓存大小的策略,包括关注命中率、插入与移除次数,以实现最佳性能。
本文深入探讨Solr的四种缓存机制:filterCache、queryResultCache、documentCache及调整策略。filterCache存储无序documentid集合,适用于facet查询;queryResultCache缓存查询结果,提升分页性能;documentCache保存<doc_id,document>对,加速频繁请求的Document读取。文章还提供了调整缓存大小的策略,包括关注命中率、插入与移除次数,以实现最佳性能。
1.filterCache
filterCache存储了无序的document id集合,key为单个fq(类型为Query),value为document id集合(类型为DocSet)。
还可用于facet查询,facet查询中各facet的计数是通过对满足query条件的document id集合(可涉及到filterCache)的处理得到的。因为统计各facet计数可能会涉及到所有的doc id,所以filterCache的大小需要能容下索引的文档数。
Filter Cache使用的内存可能会很大。Filter结果是这样存储的,用一个bit位表示Document是否符合Filter条件。如果索引中有100万Document,那么需要100万个bit位,换算一下,8位一个字节,那么需要125KB的空间。如果Filter Cache保存1000个缓存实体,那么一共占用的内存量为120M。
配置方式:
<filterCache class="solr.FastLRUCache"
size="512"
initialSize="512"
autowarmCount="128"/>
size也可以用maxRamMB代替,相对来说容易控制整体的内存使用。autowarmCount也可以使用百分比控制。
<filterCache class="solr.FastLRUCache"
maxRamMB="1000"
autowarmCount="128"/>
2.queryResultCache
queryResultCache是对查询结果的缓存,是针对查询条件的完全有序的结果。 因为查询参数是有start和rows的,所以可能存在命中了cache,但start和rows范围里的结果却不在cache的document id set范围内。这就需要参数queryResultWindowSize来指定document id set的大小。
假如要搜索“牛仔裤”,Solr是这样处理检索请求的:
首先Solr会先分词,假设把“牛仔裤”分成“牛仔”和“裤”。
Solr在索引中找到所有包含“牛仔”的Document,返回Document ID列表。一个Document ID代表包含“牛仔”这个词的Document。对于“裤”这个词同理。
最后,合并生成的两个列表。根据配置使用OR或者AND。
每次Solr计算出符合检索的Document ID集合,Solr就把结果保存在Query Cache中。如果有另外一个相同的检索,Solr能什么都不用做,立刻返回结果。但是通常来说完全相同的q和fq的请求可能并不多。
Query Cache不只是为了重复的检索。Solr接口提供分页取得检索结果,Query Cache对分页结果取得也有好处。从Solr的视角看问题,用户一次次点击下一页,相当于重复相同的检索过程。就可以配合上面提到的queryResultWindowSize来提升性能。
Query Cache用整数数组保存数据,每个缓存实体由两部分组成:Query部分和Document ID部分。Query部分保存Query String,大小由String自身大小决定。Document ID部分保存Document ID,每个Document ID由8个字节一个保存。举个简单的例子:
如果每个Query平均50个字符长度(100字节)
每个Query返回10000个结果(每个ID有8个字节,一共80000字节)
这样每个缓存实体刚刚超过80K
如果配置Solr的Query Cache可保存1000个实体。那么大约需要80M内存。
配置方式:
<queryResultCache class="solr.LRUCache"
size="512"
initialSize="512"
autowarmCount="128"
maxRamMB="1000"/>
3.documentCache
documentCache用来保存<doc_id,document>对的。如果使用documentCache,至少要大过<max_results> *<max_concurrent_queries>,否则因为cache的淘汰,一次请求期间还需要重新获取document一次。也要注意document中存储的字段的多少,避免大量的内存消耗。
当Solr返回搜索结果时,会发送请求中需要的stored字段。为了取得这些字段的值,必须单独从索引里读取。访问硬盘数据结构取得与Document ID对应的字段。读取硬盘上的数据,比读内存中的数据慢。
如果某些Document被频繁请求,Solr会把它的字段保存到内存中,节省读取字段值的性能损耗。这就是Document Cache。大体来说,Document Cache对性能方面的影响,没有另外两个Cache影响得那么大。同一个Document通常不会频繁请求,所以Cache的命中率通常比较低。
如果有很多stored段,或者stored字段很大,可能就需要让Document Cache相对小一点了,因为这种数据会消耗大量内存。
4.调整Solr缓存
刚刚使用Solr通常会把Solr的缓存大小开得很大,其实这么做对性能没有好处:
把大量内量分配给Solr,操作系统可以使用的空闲内存就少了。操作系统通常会很好地利用空闲内存提高IO性能。这对Solr来说很有好处,这会缩短Solr访问索引的时间,提高Solr整体的搜索性能,不仅仅是那些命中缓存的搜索。
大缓存只是大内存垃圾的另一种说法。如果缓存中积累了大量对象,Java的垃圾收集器用的时间会增加,会影响Solr的响应时间。
那么如何做好决策呢?
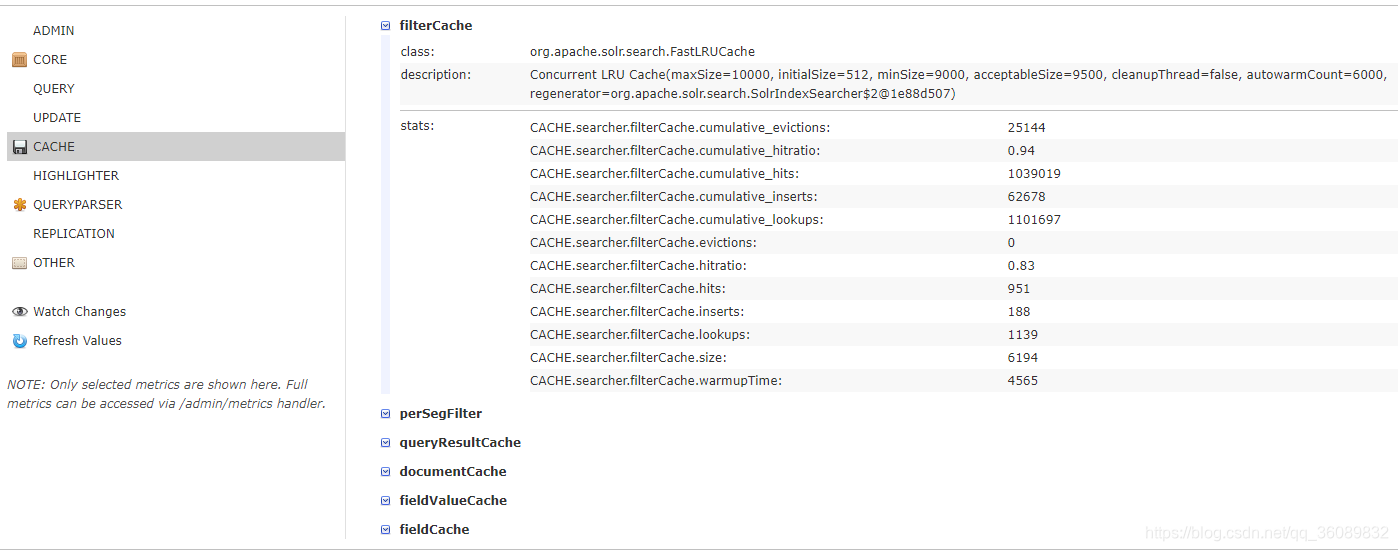
在这个画面中,你可以看到所有上面提到的缓存。还有一些其它信息。统计数据有很多种,要判断缓存是否有效,关注下面数据:
cumulative_hitratio: 是一个0〜1之间的数,代表请求命中缓存的百分比。
cumulative_inserts: 在缓存的整个生存期中,有多少缓存实体对象被加入的缓存当中。
cumulative_evictions: 在缓存的整个生存期中,有多少缓存实体对象从缓存中被移除。
最终衡量缓存性能的是命中率。你需要做实验调整缓存大小,但时刻要关注命中率,看命中率是不是越来越高。下面是调整缓存大小的一些提示:
如果发现cumulative_evictions比cumulative_inserts高一些,那么可以试着增加缓存大小,观察命中率,有可能是因为缓存实体被移除得太快了。
如果发现缓存的命中率很高,而且cumulative_evictions值很小,那么说明缓存大小设置有点大了。试着减少缓存大小,观察命中率,直到命中率有变化。
如果缓存命中率很低也不要觉得灰心,如果你的查询一般都不会有重复的case出现,命中率本来就不可能上来,这时你可以调小缓存的大小。
即使缓存的命中率很低,也不要把缓存关掉。对某些请求来说缓存还是起作用的。把缓存大小调小就可以了,保留缓存是值得的。
当调整了缓存的大小,试着用上面提到过的方法,大体估算一下内存使用的最坏情况。确保不会使用过大的内存。
参考资料:
https://blog.youkuaiyun.com/huanghai200911/article/details/51240766
http://lucene.apache.org/solr/guide/7_6/query-settings-in-solrconfig.html#caches

















 1945
1945

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









