




 本文介绍了Spark Streaming中的基本抽象Dstream,以及如何从本地文件和HDFS上读取数据流。Dstream由一系列连续的RDD表示,操作DStream会转化为对RDD的操作。在本地运行时,需要注意主URL的设置以避免线程冲突。文章还提到,文件流不使用接收器,监控规则包括基于文件修改时间、忽略更新等,并提供了代码示例。
本文介绍了Spark Streaming中的基本抽象Dstream,以及如何从本地文件和HDFS上读取数据流。Dstream由一系列连续的RDD表示,操作DStream会转化为对RDD的操作。在本地运行时,需要注意主URL的设置以避免线程冲突。文章还提到,文件流不使用接收器,监控规则包括基于文件修改时间、忽略更新等,并提供了代码示例。
标题介绍文件流之前先介绍一下Dstream
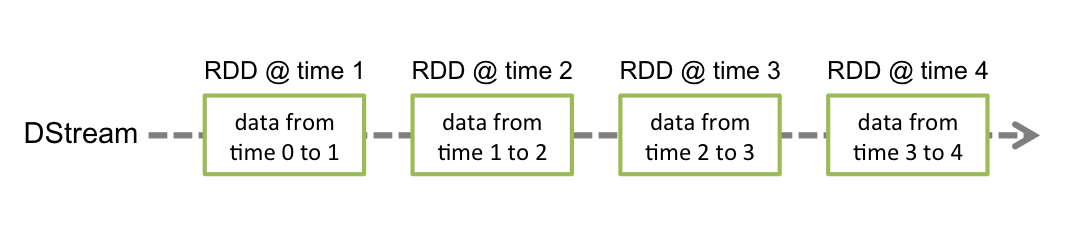
下面是来自官网一段的说明,Discretized Streams或DStream是Spark Streaming提供的基本抽象。它表示连续的数据流,可以是从源接收的输入数据流,也可以是通过转换输入流生成的已处理数据流。在内部,DStream由一系列连续的RDD表示,这是Spark对不可变的分布式数据集的抽象(有关更多详细信息,请参见Spark编程指南)。DStream中的每个RDD都包含来自特定间隔的数据,如下图所示。
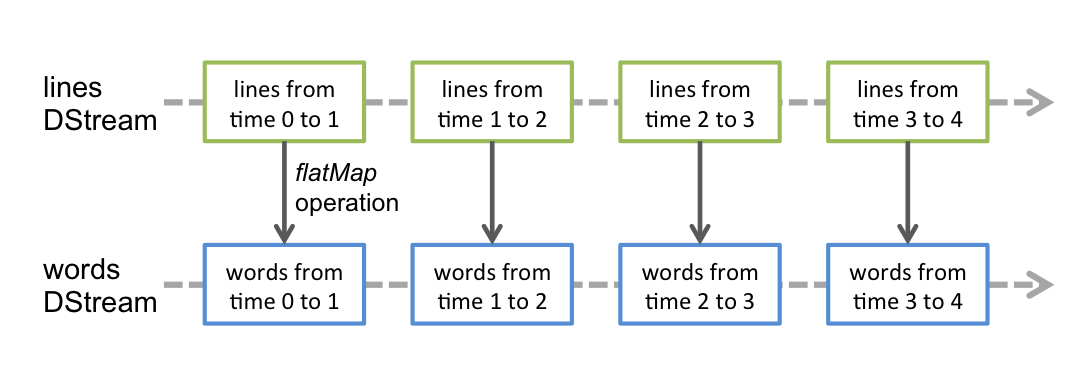
在DStream上执行的任何操作都转换为对基础RDD的操作。例如,在较早的将行流转换为单词的示例中,将flatMap操作应用于linesDStream中的每个RDD 以生成DStream的 wordsRDD。如下图所示。
要从与HDFS API兼容的任何文件系统(即HDFS,S3,NFS等)上的文件中读取数据,可以通过创建DStream StreamingContext.fileStream[KeyClass, ValueClass, InputFormatClass]。
文件流不需要运行接收器,因此无需分配任何内核来接收文件数据。
对于简单的文本文件,最简单的方法是StreamingContext.textFileStream(dataDirectory)。
在本地运行Spark Streaming程序时,请勿使用“ local”或“ local [1]”作为主URL。这两种方式均意味着仅一个线程将用于本地运行任务。如果您使用的是基于接收器的输入DStream(例如套接字,Kafka,Flume等),则将使用单个线程来运行接收器,而不会留下任何线程来处理接收到的数据。因此,在本地运行时,请始终使用“ local [ n ]”作为主URL,其中n >要运行的接收者数(有关如何设置主服务器的信息,请参见Spark属性)。
为了将逻辑扩展到在集群上运行,分配给Spark Streaming应用程序的内核数必须大于接收器数。否则,系统将接收数据,但无法处理它。
下面代码开发本地文件和hdfs的文件流
package com.zgw.spark.streaming
import org.apache 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











