



 本文详细介绍如何在Kaggle平台上进行数据竞赛,包括数据准备、处理、模型建立与训练的全过程,适合初学者快速掌握Kaggle竞赛技巧。
本文详细介绍如何在Kaggle平台上进行数据竞赛,包括数据准备、处理、模型建立与训练的全过程,适合初学者快速掌握Kaggle竞赛技巧。
参考(以免自己敲废话,可以先看,当然那个代码是python2的不是最新的):https://www.cnblogs.com/nowornever-L/p/6392780.html
这篇文章适合那些刚接触Kaggle、想尽快熟悉Kaggle并且独立完成一个竞赛项目的网友,对于已经在Kaggle上参赛过的网友来说,大可不必耗费时间阅读本文。本文分为两部分介绍Kaggle,第一部分简单介绍Kaggle,第二部分将展示解决一个竞赛项目的全过程。如有错误,请指正!
点击进入赛题“Digit Recognition”:
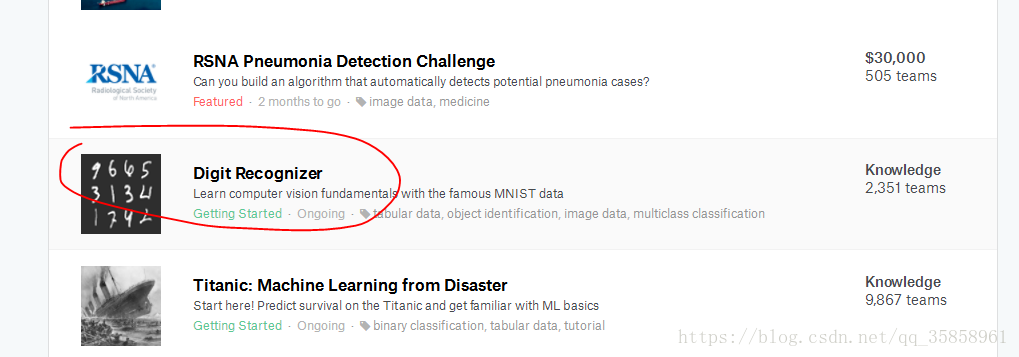
下载数据集(数据集下面有数据的格式、数据集大小等)
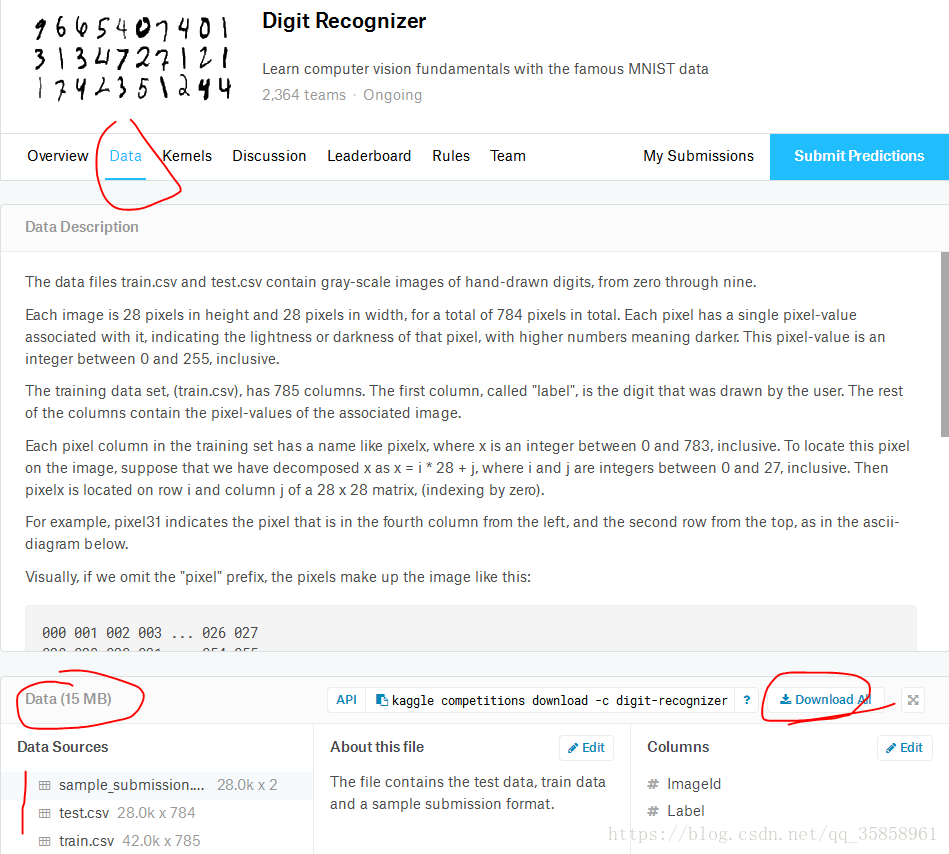
下载完解压,发现所给的数据是csv格式,不是传统上所看到的(28*28)的图片,也就是说其已经拉直了(一个数据是一维),kaggle上很多数据都是给的csv格式

其中,train.csv就是训练样本,test.csv就是测试样本,(测试样本的结果在sample_submission中)
一 数据准备
- 分析train.csv数据(参考)
train.csv是训练样本集,大小42001*785,第一行是文字描述,所以实际的样本数据大小是42000*785,其中第一列的每一个数字是它对应行的label,可以将第一列单独取出来,得到42000*1的向量trainLabel,剩下的就是42000*784的特征向量集trainData,所以从train.csv可以获取两个矩阵trainLabel、trainData。
下面给出从csv文件中读取数据代码
def loadTrainData():
l = []
with open('all/train.csv') as file:
lines = csv.reader(file)
for line in lines:
#line = int(line) 报错(csv中保存的数据为字符串,我本想一行一次转为int型数字,但后来发现int()转换一次只能转一个字符串,否则,或报错)
#:TypeError: int() argument must be a string, a bytes-like object or a number, not 'list'/'tuple'
l.append(line) #自动关闭文件(也必须关闭的)
l.remove(l[0]) #第一行为描述,不是真实数据,故要去掉
l=np.mat(l) #将数据转换为矩阵才能切片 ,python自带的列表只有是一维列表时才能切片
label = l[:,0] #在二维数组中可以方便地使用区域切片功能,
data = l[:,1:]
#return nomalizing(toInt(data)),nomalizing(toInt(label)) 是不对的,label标签只有一个维度
return nomalizing(toInt(data)),toInt(label) 这里还有两个函数需要说明一下,toInt()函数,是将字符串转换为整数,因为从csv文件读取出来的,是字符串类型的,比如‘253’,而我们接下来运算需要的是整数类型的,因此要转换,int(‘253’)=253。toInt()函数如下:
def toInt(array):
array=np.mat(array)
m,n=np.shape(array)
newArray=np.zeros((m,n))
for i in range(m):
for j in range(n):
newArray[i,j]=int(array[i,j])
return newArray
def nomalizing(array):
m,n=np.shape(array)
for i in range(m):
for j in range(n):
if array[i,j]!=0:
array[i,j]=1
return array nomalizing()函数做的工作是归一化,因为train.csv里面提供的表示图像的数据是0~255的,为了简化运算,我们可以将其转化为二值图像,因此将所有非0的数字,即1~255都归一化为1。nomalizing()函数如上:(参考上面,该不用自己废话的就直接复制了,代码有一点不一样代码有一点不一样)
- 分析test.csv数据
test.csv里的数据大小是28001*784,第一行是文字描述,因此实际的测试数据样本是28000*784,与train.csv不同,没有label,28000*784即28000个测试样本,我们要做的工作就是为这28000个测试样本找出正确的label。所以从test.csv我们可以得到测试样本集testData,代码如下:
def loadTestData():
l=[]
with open('all/test.csv') as file:
lines=csv.reader(file)
for line in lines:
l.append(line)
#28001*784
l.remove(l[0])
data=np.array(l)
return nomalizing(toInt(data)) - 分析sample_submission.csv
前面已经提到,由于digit recognition是训练赛,所以这个文件是官方给出的参考结果,本来可以不理这个文件的,但是我下面为了对比自己的训练结果,所以也把knn_benchmark.csv这个文件读取出来,这个文件里的数据是28001*2,第一行是文字说明,可以去掉,第一列表示图片序号1~28000,第二列是图片对应的数字。从knn_benchmark.csv可以得到28000*1的测试结果矩阵testResult,代码:
def loadTestResult():
l=[]
with open('all/sample_submission.csv') as file:
lines=csv.reader(file)
for line in lines:
l.append(line)
#28001*2
l.remove(l[0])
label=np.array(l)
return toInt(label[:,1])到这里,数据分析和处理已经完成,我们获得的矩阵有:trainData、trainLabel、testData、testResult
二 数据载入
x_train,y_train = loadTrainData()
#x_test,y_test = main.loadTestData()
x_test=loadTestData()
y_test=loadTestResult()
print(y_test.shape) # 这一步为什么要呢?因为在testResult的数据维度信息不一样,导致后面报错,这里写了就是确认一下数据的维度信息。
y_test = y_test.flatten() # 这一行就是为了解决上面报错的情况的。
y_train = np_utils.to_categorical(y_train, num_classes=10) #将index转换橙一个one_hot矩阵
y_test = np_utils.to_categorical(y_test, num_classes=10) #将index转换橙一个one_hot矩阵
#print(x_train.shape()) 错误的shape用法
print(x_train.shape)
print(y_train.shape)
print(x_test.shape)
print(y_test.shape)运行结果:(可以看出,同样是load data testResult的结果是红圈所画,而其他的几个载入数据则是对的,如果不管,会是的最后一行数据的维度变为(1,28000,10)。在知晓数据维度不对的情况下,添加y_test = y_test.flatten()使红圈变为(28000,))
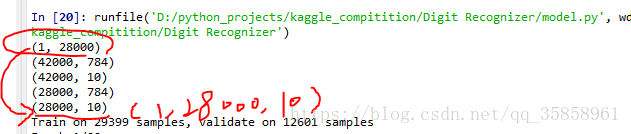
如果不处理,会报如下错误:ValueError: Error when checking target: expected activation_17 to have 2 dimensions, but got array with shape (1, 28000, 10) 解决办法(查看数据维度信息)参考:https://blog.youkuaiyun.com/u012193416/article/details/79399679
https://github.com/keras-team/keras/issues/8088
三 模型建立与编译 训练(当然,我用的比较简单的模型)
'''模型建立'''
model = Sequential()
model.add(Dense(500,input_shape=(784,))) #输入层, 28*28=784
model.add(Activation('relu'))
model.add(Dropout(0.5)) #50% dropout
model.add(Dense(500)) #隐藏层, 500
model.add(Activation('tanh'))
model.add(Dropout(0.5)) #50% dropout
model.add(Dense(10)) #输出结果, 10
model.add(Activation('softmax'))
adam = Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
#model.compile(loss = 'categorical_crossentropy', optimizer=adam, class_mode='categorical') #使用交叉熵作为loss ,keras编译时compile()只有三个参数,这里出错
model.compile(loss = 'categorical_crossentropy', optimizer=adam, metrics=['accuracy'])
训练 与预测
model.fit(x_train,y_train,batch_size=32,epochs=20,shuffle=True,verbose=1,validation_split=0.3)
loss,accuracy = model.evaluate(x_test,y_test)训练过程完毕! 完整代码
# conding:utf-8
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
#from keras.models import Sequential
#from keras.layers import Dense, Dropout, Activation
#from keras.optimizers import SGD,Adam
#import numpy as np
import csv
from keras.layers import Dense, Activation,Dropout, Convolution2D, MaxPooling2D, Flatten
import numpy as np
np.random.seed(1337) # for reproducibility
from keras.utils import np_utils
from keras.models import Sequential
from keras.optimizers import SGD,Adam
'''数据准备'''
def loadTrainData():
l = []
with open('all/train.csv') as file:
lines = csv.reader(file)
for line in lines:
#line = int(line) 报错:TypeError: int() argument must be a string, a bytes-like object or a number, not 'list'
l.append(line) #自动关闭文件(也必须关闭的)
l.remove(l[0]) #第一行为描述,不是真实数据,故要去掉
l=np.mat(l) #将数据转换为矩阵才能切片
label = l[:,0] #在二维数组中可以方便地使用区域切片功能,
data = l[:,1:]
#return nomalizing(toInt(data)),nomalizing(toInt(label)) 是不对的,label标签只有一个维度
return nomalizing(toInt(data)),toInt(label)
def toInt(array):
array=np.mat(array)
m,n=np.shape(array)
newArray=np.zeros((m,n))
for i in range(m):
for j in range(n):
newArray[i,j]=int(array[i,j])
return newArray
def nomalizing(array):
m,n=np.shape(array)
for i in range(m):
for j in range(n):
if array[i,j]!=0:
array[i,j]=1
return array
def loadTestData():
l=[]
with open('all/test.csv') as file:
lines=csv.reader(file)
for line in lines:
l.append(line)
#28001*784
l.remove(l[0])
data=np.array(l)
return nomalizing(toInt(data))
def loadTestResult():
l=[]
with open('all/sample_submission.csv') as file:
lines=csv.reader(file)
for line in lines:
l.append(line)
#28001*2
l.remove(l[0])
label=np.array(l)
return toInt(label[:,1])
x_train,y_train = loadTrainData()
#x_test,y_test = main.loadTestData()
x_test=loadTestData()
y_test=loadTestResult()
print(y_test.shape)
y_test = y_test.flatten()
y_train = np_utils.to_categorical(y_train, num_classes=10) #将index转换橙一个one_hot矩阵
#y_test = y_test.reshape(len(y_test),-1)
y_test = np_utils.to_categorical(y_test, num_classes=10)
#print(x_train.shape()) 错误的shape用法
print(x_train.shape)
print(y_train.shape)
print(x_test.shape)
print(y_test.shape)
'''模型建立'''
model = Sequential()
model.add(Dense(500,input_shape=(784,))) #输入层, 28*28=784
model.add(Activation('relu'))
model.add(Dropout(0.5)) #50% dropout
model.add(Dense(500)) #隐藏层, 500
model.add(Activation('tanh'))
model.add(Dropout(0.5)) #50% dropout
model.add(Dense(10)) #输出结果, 10
model.add(Activation('softmax'))
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True) #设定学习效率等参数
adam = Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
#model.compile(loss = 'categorical_crossentropy', optimizer=adam, class_mode='categorical') #使用交叉熵作为loss ,keras编译时compile()只有三个参数,这里出错
model.compile(loss = 'categorical_crossentropy', optimizer=adam, metrics=['accuracy'])
model.fit(x_train,y_train,batch_size=32,epochs=20,shuffle=True,verbose=1,validation_split=0.3)
loss,accuracy = model.evaluate(x_test,y_test)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









