



 本文介绍了Apache Flume的三个高级组件:拦截器、通道选择器和处理器。拦截器包括Timestamp Interceptor、Host Interceptor和Static Interceptor,用于数据过滤和包装。通道选择器如Replicating Channel Selector和Multiplexing Channel Selector决定了数据流向。处理器部分讨论了Failover Sink Processor和Load balancing Sink Processor,前者实现故障转移,后者实现负载均衡。
本文介绍了Apache Flume的三个高级组件:拦截器、通道选择器和处理器。拦截器包括Timestamp Interceptor、Host Interceptor和Static Interceptor,用于数据过滤和包装。通道选择器如Replicating Channel Selector和Multiplexing Channel Selector决定了数据流向。处理器部分讨论了Failover Sink Processor和Load balancing Sink Processor,前者实现故障转移,后者实现负载均衡。
flume中3大高级组件
Flume Interceptors:拦截器,与Spring中拦截器是类似
官方解释:

功能:通过拦截器对每条数据进行过滤护着包装
Timestamp Interceptor:时间拦截器
在每一个event的头部添加一个KeyValue
key: timestamp
value:当前封装event的时间
Host Interceptor:主机名拦截器
在每一个event的头部添加一个KeyValue
key: host
value:当前封装event所在机器的主机名
Static Interceptor:自定义拦截器
a1.sources = r1
a1.channels = c1
a1.sources.r1.channels = c1
a1.sources.r1.type = seq
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
a1.sources.r1.interceptors.i1.key = datacenter
a1.sources.r1.interceptors.i1.value = NEW_YORK
Regex Filtering Interceptor通过自定义正则表达式,实现对数据过滤
符号该正则,该条数据才会被留下
a1.sources = s1
a1.channels = c1
a1.sinks = k1
# defined sources
a1.sources.s1.type =exec
a1.sources.s1.command=tail -F /opt/datas/flume/fliter.txt
a1.sources.s1.shell=/bin/sh -c
#正则过滤
a1.sources.s1.interceptors=i2
a1.sources.s1.interceptors.i2.type = regex_filter
a1.sources.s1.interceptors.i2.regex=\\{.*\\}
a1.sources.s1.interceptors.i2.excludeEvents=false
# defined channel
a1.channels.c1.type = memory
#容量
a1.channels.c1.capacity=1000
#瓶口大小
a1.channels.c1.transactionCapacity=100
# defined sink
# defined sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path=/flume/fliter_interceptor
a1.sinks.k1.hdfs.useLocalTimeStamp=true
#设置文件类型和写的格式
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.writeFormat=Text
#设置hdfs文件大小
a1.sinks.k1.hdfs.rollInterval=0
a1.sinks.k1.hdfs.rollSize=10240
a1.sinks.k1.hdfs.rollCount=0
#bind
a1.sinks.k1.channel = c1
a1.sources.s1.channels = c1执行命令:
bin/flume-ng agent -n a1 -c conf -f case/9-filter-interceptor.properties -Dflume.root.logger=INFO,console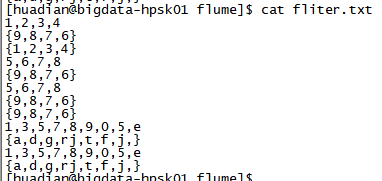
输出:

看输出可以看到与期望的结果不一样,少了一个{9,8,7,6},原因是exec,tail -F默认读后面10行数据。第一个{9,8,7,6}在11行了,所以读取不到。
时间拦截器:
a1.sources = s1
a1.channels = c1
a1.sinks = k1
# defined sources
a1.sources.s1.type = seq
#时间过滤
a1.sources.s1.interceptors = i1
a1.sources.s1.interceptors.i1.type = timestamp
# defined channel
a1.channels.c1.type = memory
#容量
a1.channels.c1.capacity=1000
#瓶口大小
a1.channels.c1.transactionCapacity=100
# defined sink
a1.sinks.k1.type = logger
#设置hdfs文件大小
a1.sinks.k1.hdfs.rollInterval=0
a1.sinks.k1.hdfs.rollSize=10240
a1.sinks.k1.hdfs.rollCount=0
#bind
a1.sinks.k1.channel = c1
a1.sources.s1.channels = c1Flume Channel Selectors
selector.type根据该值确定功能
Replicating Channel Selector(默认)
source将每条数据发给每一个channel
source将数据发了多份
Multiplexing Channel Selector
source选择性的将数据发送给channel
a1.sources = r1
a1.channels = c1 c2 c3 c4
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = state //取出event 头信息中可以是state的值AA
a1.sources.r1.selector.mapping.CZ = c1 //AA==CZ ,发给C1
a1.sources.r1.selector.mapping.US = c2 c3 //AA==US ,发给C2,C3
a1.sources.r1.selector.default = c4Flume Sink Processors(sink的处理器)
Failover Sink Processor(故障转移)
processor.type= failover
启动了多个,但是工作的只有一个,只有active状态进程死掉,其他才可能接替工作。
那么多个有多个sink到底谁先工作,根据权重来,谁的权重高,谁先干活
一般故障转移的话,2个sink的类型不一样(HDFS sink ,file sink)
比如往HDFS写数据,HDFS宕机了,数据不丢失,往文件里写
Load balancing Sink Processor(负载均衡)
processor.type=load_balance
processor.selector = round_robin(轮询)|random(随机)
负载均衡与故障转移,只能实现一个,不能同时实现,往往选择负载均衡

















 368
368

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









