




 本文详细介绍了线性回归的基本原理,包括最小二乘法的数学推导和概率角度的理解,以及为防止过拟合引入的L1-Lasso和L2-岭回归正则化方法。
本文详细介绍了线性回归的基本原理,包括最小二乘法的数学推导和概率角度的理解,以及为防止过拟合引入的L1-Lasso和L2-岭回归正则化方法。
线性回归
线性回归作为最简单的数据拟合函数,基本形式也非常简单。
给定由d个属性描述的示例
x
=
(
x
1
,
x
2
,
.
.
.
,
x
d
)
T
x=(x_{1},x_{2},...,x_{d})^T
x=(x1,x2,...,xd)T,其中
x
i
x_{i}
xi是x在第i个属性上的取值,线性模型试图学得一个通过属性的线性组合组合来进行结果预测的函数,即
f
(
x
)
=
w
1
x
1
+
w
2
x
2
+
.
.
.
+
w
d
x
d
+
b
,
f(x)=w_{1}x_{1}+w_{2}x_{2}+...+w_{d}x_{d}+b,
f(x)=w1x1+w2x2+...+wdxd+b,用向量的形式表达就是:
f
(
x
)
=
w
T
x
+
b
,
f(x)=w^Tx+b,
f(x)=wTx+b,这里
w
w
w也是d维列向量,
w
=
(
w
1
,
w
2
,
.
.
.
,
w
d
)
T
.
w=(w_{1},w_{2},...,w_{d})^T.
w=(w1,w2,...,wd)T.当我们把
w
w
w和
b
b
b确定下来之后,模型显然也就得到了。
最小二乘法
对于刚刚我们求得的线性回归模型,如何衡量
f
(
x
)
f(x)
f(x)和真实
y
y
y之间的差别呢?如果采用均方误差(平方损失)作为模型求解的方法的话,就被叫做“最小二乘法”。
最小二乘法定义如下:
L
(
w
)
=
∑
i
=
1
N
∣
∣
f
(
x
i
)
−
y
i
∣
∣
2
=
∑
i
=
1
N
∣
∣
w
T
x
i
−
y
i
∣
∣
2
=
∑
i
=
1
N
(
w
T
x
i
−
y
i
)
2
=
(
w
T
X
T
−
Y
T
)
(
w
X
−
Y
)
L(w)=\sum_{i=1}^{N}||f(x_{i})-y_{i}||^2=\sum_{i=1}^{N}||w^Tx_{i}-y_{i}||^2=\sum_{i=1}^{N}(w^Tx_{i}-y_{i})^2=(w^TX^T-Y^T)(wX-Y)
L(w)=i=1∑N∣∣f(xi)−yi∣∣2=i=1∑N∣∣wTxi−yi∣∣2=i=1∑N(wTxi−yi)2=(wTXT−YT)(wX−Y)
将上式展开,有:
L
(
w
)
=
(
w
T
X
T
−
Y
T
)
(
w
X
−
Y
)
=
w
T
X
T
−
2
w
T
X
T
Y
+
Y
T
Y
L(w)=(w^TX^T-Y^T)(wX-Y)=w^TX^T-2w^TX^TY+Y^TY
L(w)=(wTXT−YT)(wX−Y)=wTXT−2wTXTY+YTY
又因为
w
^
=
a
r
g
m
i
n
L
(
w
)
,
\hat {w}=argminL(w),
w^=argminL(w),为了求出
w
w
w,我们可以对其求偏导:
∂
L
(
w
)
∂
w
=
2
X
T
X
w
−
2
X
T
Y
=
0
,
\frac {\partial L(w)}{\partial w}=2X^TXw-2X^TY=0,
∂w∂L(w)=2XTXw−2XTY=0,解得
w
=
(
X
T
X
)
−
1
X
T
Y
w=(X^TX)^{-1}X^TY
w=(XTX)−1XTY
注意:为了方便求解,上面的推导过程省略了偏置
b
,
b,
b,并且此求解过程只适用于
X
T
X
X^TX
XTX是满秩矩阵或者正定矩阵
概率角度
样本集:
D
=
{
(
x
1
,
y
1
)
,
.
.
.
,
(
x
N
,
y
N
)
}
D=\left \{(x_1,y_1),...,(x_N,y_N)\right \}
D={(x1,y1),...,(xN,yN)}
x
i
ϵ
R
p
,
y
i
ϵ
R
,
i
=
1
,
2
,
.
.
.
,
N
x_i\epsilon R^p,y_i \epsilon R,i=1,2,...,N
xiϵRp,yiϵR,i=1,2,...,N
X
=
(
x
1
,
x
2
,
.
.
.
,
x
N
)
T
=
(
x
1
T
.
.
.
x
N
T
)
,
Y
=
(
y
1
.
.
.
y
N
)
X=(x_1,x_2,...,x_N)^T=\begin{pmatrix} x_1^T \\ ...\\ x_N ^T \end{pmatrix},Y=\begin{pmatrix} y_1 \\ ...\\ y_N \end{pmatrix}
X=(x1,x2,...,xN)T=⎝⎛x1T...xNT⎠⎞,Y=⎝⎛y1...yN⎠⎞
最小二成估计的损失函数
L
(
w
)
=
∑
i
=
1
N
∣
∣
w
T
x
i
−
y
i
∣
∣
2
,
L(w)=\sum_{i=1}^{N}||w^Tx_{i}-y_{i}||^2,
L(w)=∑i=1N∣∣wTxi−yi∣∣2,
w
^
=
a
r
g
m
i
n
L
(
w
)
,
w
=
(
X
T
X
)
−
1
X
T
Y
\hat {w}=argminL(w),w=(X^TX)^{-1}X^TY
w^=argminL(w),w=(XTX)−1XTY
在现实情况中,我们的数据都是有噪声的,因此模型的不可能和真实数据百分百拟合。
这里假定噪声是服从高斯分布的,也就是
ε
∼
N
(
0
,
σ
2
)
,
\varepsilon \sim N(0,\sigma ^2),
ε∼N(0,σ2),
那么
y
=
f
(
w
)
+
ε
=
w
T
x
+
ε
,
y
y=f(w)+\varepsilon=w^Tx+\varepsilon,y
y=f(w)+ε=wTx+ε,y就服从高斯分布
y
∣
x
;
w
∼
N
(
w
T
x
,
σ
2
)
y|x;w\sim N(w^Tx,\sigma^2)
y∣x;w∼N(wTx,σ2)
利用极大似然估计求解:
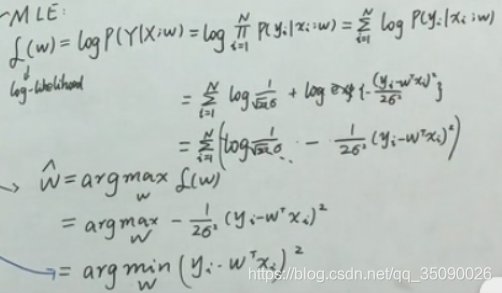
所以通过概率的角度得出的结论也是一样的,也就是最小二乘估计隐藏了一个噪声服从正态分布的假设。
等价于:最小二乘估计等价于噪声服从给正态分布的最大似然估计
正则化:L1-lasso,L2-岭回归
最小二成估计的损失函数
L
(
w
)
=
∑
i
=
1
N
∣
∣
w
T
x
i
−
y
i
∣
∣
2
,
L(w)=\sum_{i=1}^{N}||w^Tx_{i}-y_{i}||^2,
L(w)=∑i=1N∣∣wTxi−yi∣∣2,
w
^
=
a
r
g
m
i
n
L
(
w
)
,
w
^
=
(
X
T
X
)
−
1
X
T
Y
\hat {w}=argminL(w),\hat w=(X^TX)^{-1}X^TY
w^=argminL(w),w^=(XTX)−1XTY
由于现实中样本无法对
X
T
X
X^TX
XTX求逆矩阵,样本数量过少又会有过拟合的风险,因此提出了很多解决方法。常见的解决方法有:1.加数据,2特征选择、特征提取,3.正则化
正则化的框架:
a
r
g
m
i
n
w
[
L
(
w
)
+
λ
P
(
w
)
]
\underset w {argmin}[L(w)+\lambda P(w)]
wargmin[L(w)+λP(w)]
具体我们引入两种正则化:
1.L1:Lasso,
P
(
w
)
=
∣
∣
w
∣
∣
P(w)=||w||
P(w)=∣∣w∣∣
2.L2:Ridge.
P
(
w
)
=
∣
∣
w
∣
∣
2
2
−
w
T
w
P(w)=||w||^2 _2 -w^T w
P(w)=∣∣w∣∣22−wTw也就是权值衰减
一范数和二范数。
岭回归
代入求解,有
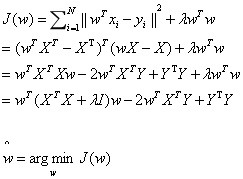
对其求偏导,有
w
=
(
X
T
X
+
λ
I
)
−
1
X
T
Y
w=(X^TX+\lambda I)^{-1}X^TY
w=(XTX+λI)−1XTY
这里和加入偏置后和原来求解的结果只差了
λ
I
,
\lambda I,
λI,而
λ
I
\lambda I
λI又是对角矩阵,对角矩阵+半正定矩阵一定是可逆的。可以达到抑制过拟合的效果。

















 442
442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









