




Hive是什么?
Hive是构建在hadoop之上的数据仓库
Hive是一个基于hadoop的数据仓库,可以通过类似于SQL语句来进行对数据的读写管理(元数据)等操作
Hive定义了一种类似于SQL的查询语言,叫做HQL类似于SQL,但是不完全相同,通常用于离线数据处理(采用的方式是MapReduce)
Hive的底层支持不同的执行引擎(Hive on MapReduce Hive on Spark Hive on Tez)
支持多种不同压缩格式,存储格式以及自定义函数
Hive的特点:
1.Hive是一种易于对数据实现提取转换加载的工具(ETL数据清洗),可以理解为数据清洗分析
2.它有一种大量格式化数据集强加上结构的机制
3.它可以分析处理直接存储在HDFS中的数据,或者别的和数据存储中的数据例如:HBASE
4.查询的执行是MapReduce完成的
5.Hive可以使用存储过程
6.YARN和Slider实现秒级查询搜索
Hive的架构:
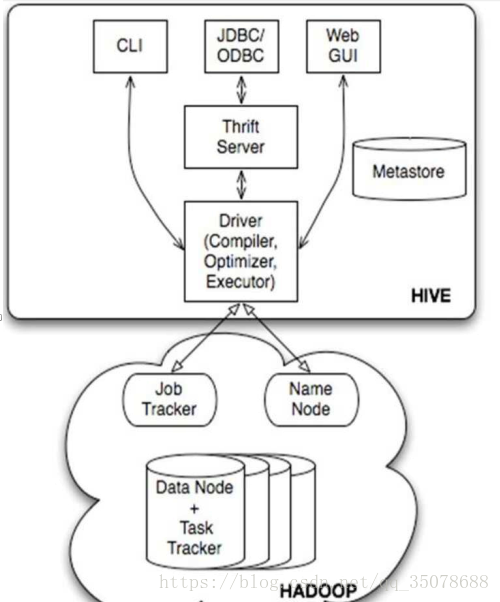
用户接口主要有三个:
CLI(命令行接口)JDBC/ODBC和WEBUI,其中最常用的是CLI,CLI 启动的时候同时启动一个Hive副本,Client是Hive客户端,用户会连接至Hive Server在定Client模式的时候,需要指出Hive Server所在的节点
并且在该节点启动Hive Server
WebUI是通过浏览器访问Hive,使用三方thirdServer:(JDBC/ODBC)
2.hive将元数据存储在数据库中–derby,mysql等等,Hive的元数据包括表的名字,包括分区,分桶等相关属性,hive中的表属性分为外部表和内部表,表的数据所在的目录等等。
ps:元数据里面不存储真正的数据,它是描述数据的,真正的数据是具体存储的值,
hive提供的数据存储在HDFS上,建表的信息在数据库,Hive本身存储不了数据,靠的是HDFS存储数据
3.Driver:解释器,编译器,优化器的作用是完成HQL查询语句从词法分析—语法分析–编译—优化以及查询计划的生成,生成的查询计划存储在HDFS上,并在随后的MapReduce中执行,
ps:driver解释器,将HQL语句生成一个抽象的表达式树,
编译器:对HQL语句进行词法分析,雨衣分析,语义编译(此时需要联系元数据),编译完成后会生成一个“有向无环”的执行计划
ps:有向无环—>有执行方向,但是不能成为一个环状结构
优化器:将执行计划进行优化,减少不必要的列,使用的分区等等
执行器:将优化后的执行计划交给hadoop的MapReduce来执行
4.hive:的数据存在HDFS上,大部分的查询和计算都是有MapReduce完成的,
select * from table 的查询不会生成MapReduce
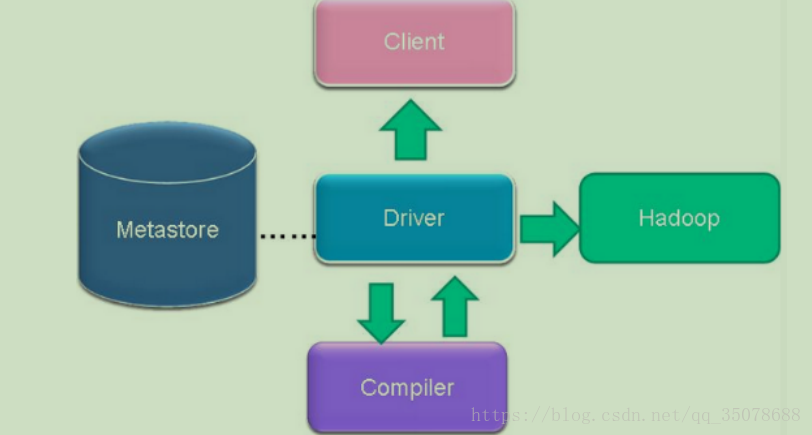
ps:编译器将HiveQL,再转换成操作符,操作符是Hive中的最小处理单元,每一个操作符代表HDFS的一个操作或一个MapReduce的作业
Hive和Hadoop的关系
hive基于Hadoop
hive本身没有存储和分析的功能,hive是建立在hadoop之上的一个工具
hive的存储是基于HDFS(HBASE),hive的分析依赖于MapReduce
Hive和传统数据库相比
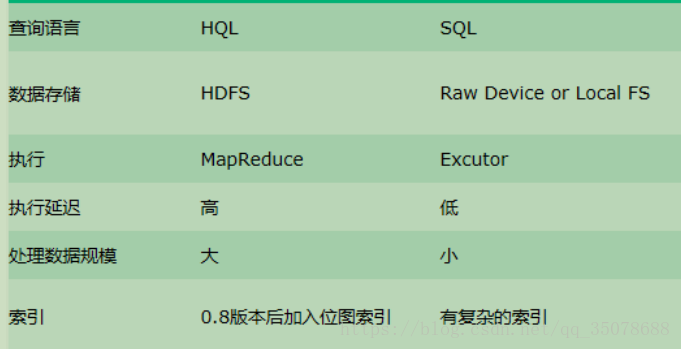
ps:hive是具有sql数据库的外表,但应用场景完全不同,还不适合用来做批量数据统计分析
详细说明:
1.查询语言,由于SQL被广泛的用用在数据仓库中,一次专门针对Hive的特性设计了类SQL的查询语言HQL。熟悉SQL开发的开发者可以很方便的使用hive 进行开发。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









