




 本文深入探讨MyBatis框架的高级特性,包括动态SQL、批量插入、分页插件、一对多查询、缓存机制等,解析MyBatis如何提升SQL效率与安全性,以及ORM映射的半自动特性。
本文深入探讨MyBatis框架的高级特性,包括动态SQL、批量插入、分页插件、一对多查询、缓存机制等,解析MyBatis如何提升SQL效率与安全性,以及ORM映射的半自动特性。
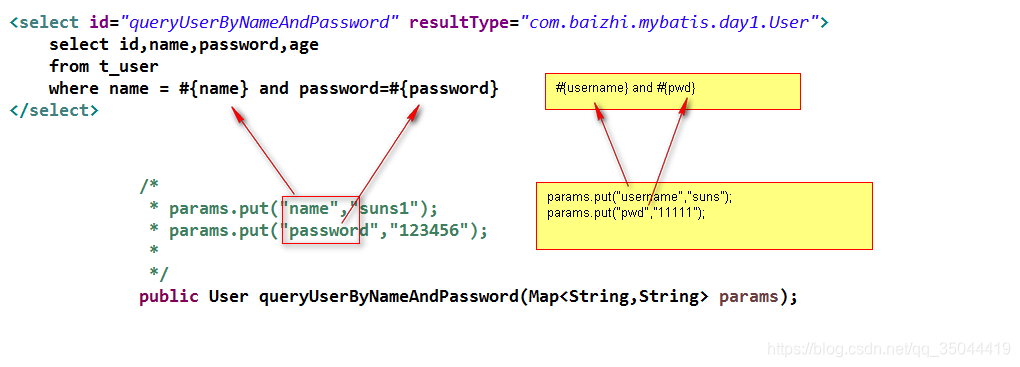
1、#{}和${}的区别是什么?
- #{}是预编译处理,${}是字符串替换。
-
#将传入的数据都当成一个字符串,会对自动传入的数据加一个双引号。如:order by #user_id#,如果传入的值是111,那么解析成sql时的值为order by "111", 如果传入的值是id,则解析成的sql为order by "id".
$将传入的数据直接显示生成在sql中。如:order by $user_id$,如果传入的值是111,那么解析成sql时的值为order by user_id, 如果传入的值是id,则解析成的sql为order by id.
- Mybatis在处理#{}时,会将sql中的#{}替换为?号,调用PreparedStatement的set方法来赋值;
- Mybatis在处理${}时,就是把${}替换成变量的值,属于静态文本替换,比如${driver}会被静态替换为com.mysql.jdbc.Driver。
- 使用#{}可以有效的防止SQL注入,提高系统安全性。、
2、ResultMap和ResultType区别?,ParameterMap和parameterType区别?
先说 resultMap和resultType的区别,只是个人理解哈。如果实体类属性和表字段相同,返回值类型就可以使用resltType=" ",如果实体类属性与表地段不一样,就会导致查询出的结果集与实体类无法匹配,mybatis是做不了这个映射的,所以就用resultMap来解决实体类与查询结果不匹配的问题。
附上一张图,介绍下resultMap的用法:

另外就是查询结果集与实体类不匹配的解决之道,最简化的就是查询的时候给表字段起别名,让别名与实体类一一对应也可以。
ParameterMap(不推荐使用)和parameterType:
ParameterMap:与resultMap方法类似,表示将查询结果集中列值的类型一一映射到java对象属性的类型上,在开发过程中不推荐这种方式。

parameterType:
parameterType直接将查询结果列值类型自动对应到java对象属性类型上,不再配置映射关系一一对应。

3、 JDBC编程有哪些不足之处,MyBatis是如何解决这些问题的?
① 数据库链接创建、释放频繁造成系统资源浪费从而影响系统性能,如果使用数据库链接池可解决此问题。
解决:在SqlMapConfig.xml中配置数据链接池,使用连接池管理数据库链接。
② Sql语句写在代码中造成代码不易维护,实际应用sql变化的可能较大,sql变动需要改变java代码。
解决:将Sql语句配置在XXXXmapper.xml文件中与java代码分离。
③ 向sql语句传参数麻烦,因为sql语句的where条件不一定,可能多也可能少,占位符需要和参数一一对应。
解决: Mybatis自动将java对象映射至sql语句。
④ 对结果集解析麻烦,sql变化导致解析代码变化,且解析前需要遍历,如果能将数据库记录封装成pojo对象解析比较方便。
解决:Mybatis自动将sql执行结果映射至java对象。
4、Mybatis执行批量插入,能返回数据库主键列表吗?
Mybatis在插入单条数据的时候有两种方式返回自增主键: mybatis3.3.1支持批量插入后返回主键ID,
首先对于支持自增主键的数据库:useGenerateKeys和keyProperty。
不支持生成自增主键的数据库:<selectKey>。
<insert id=”insertname” usegeneratedkeys=”true” keyproperty=”id”>
insert into names (name) values (#{name})
</insert>
name name = new name();
name.setname(“fred”);
int rows = mapper.insertname(name);
// 完成后,id已经被设置到对象中
system.out.println(“rows inserted = ” + rows);
system.out.println(“generated key value = ” + name.getid())
<insert id="insertOne" parameterType="cn.it.cast.dao.User">
<selectKey resultType="java.lang.Integer" order="AFTER" keyProperty="id">
SELECT LAST_INSERT_ID() AS id
</selectKey>
insert into user (username,password,age) values (#{username},#{password},#{age})
</insert>
5、 模糊查询like语句该怎么写?
第1种:在Java代码中添加sql通配符。
string wildcardname = “%smi%”;
list<name> names = mapper.selectlike(wildcardname);
<select id=”selectlike”>
select * from foo where bar like #{value}
</select>
第2种:在sql语句中拼接通配符,会引起sql注入
string wildcardname = “smi”;
list<name> names = mapper.selectlike(wildcardname);
<select id=”selectlike”>
select * from foo where bar like "%"#{value}"%"
</select>
6、通常一个Xml映射文件,都会写一个Dao接口与之对应,请问,这个Dao接口的工作原理是什么?Dao接口里的方法,参数不同时,方法能重载吗?
<1>、Dao接口,就是人们常说的Mapper接口,接口的全限名,就是映射文件中的namespace的值,接口的方法名,就是映射文件中MappedStatement的id值,接口方法内的参数,就是传递给sql的参数。Mapper接口是没有实现类的,当调用接口方法时,接口全限名+方法名拼接字符串作为key值,可唯一定位一个MappedStatement
举例:com.mybatis3.mappers.StudentDao.findStudentById,
可以唯一找到namespace为com.mybatis3.mappers.StudentDao下面id = findStudentById的MappedStatement。在Mybatis中,每一个<select>、<insert>、<update>、<delete>标签,都会被解析为一个MappedStatement对象。
<2>、Dao接口里的方法,是不能重载的,因为是全限名+方法名的保存和寻找策略。
<3>、Dao接口的工作原理是JDK动态代理,Mybatis运行时会使用JDK动态代理为Dao接口生成代理proxy对象,代理对象proxy会拦截接口方法,转而执行MappedStatement所代表的sql,然后将sql执行结果返回。
7、Mybatis是如何进行分页的?分页插件的原理是什么?
Mybatis使用RowBounds对象进行分页,它是针对ResultSet结果集执行的内存分页,而非物理分页,可以在sql内直接书写带有物理分页的参数来完成物理分页功能,也可以使用分页插件来完成物理分页。
分页插件的基本原理是使用Mybatis提供的插件接口,实现自定义插件,在插件的拦截方法内拦截待执行的sql,然后重写sql,根据dialect方言,添加对应的物理分页语句和物理分页参数。
举例:select * from student,拦截sql后重写为:select t.* from (select * from student)t limit 0,10
8、MyBatis在mapper中如何传递多个参数?
<1>、可以通过下标的形式进行操作

<2>、 @Param注解 进行参数绑定【建议】

<3>、老炮儿在早期的使用方式
9、Mybatis动态sql是做什么的?都有哪些动态sql?能简述一下动态sql的执行原理不?
Mybatis动态sql可以让我们在Xml映射文件内,以标签的形式编写动态sql,
完成逻辑判断和动态拼接sql的功能。
Mybatis提供了9种动态sql标签:
trim|where|set|foreach|if|choose|when|otherwise|bind。
其执行原理为:
使用OGNL从sql参数对象中计算表达式的值,根据表达式的值动态拼接sql,
以此来完成动态sql的功能。
10、Mybatis的Xml映射文件中,不同的Xml映射文件,id是否可以重复?
不同的Xml映射文件,
如果配置了namespace,那么id可以重复;
如果没有配置namespace,那么id不能重复;
毕竟namespace不是必须的,只是最佳实践而已。
原因就是namespace+id是作为Map<String, MappedStatement>的key使用的,
如果没有namespace,就剩下id,那么,id重复会导致数据互相覆盖。
有了namespace,自然id就可以重复,namespace不同,namespace+id自然也就不同。
11、为什么说Mybatis是半自动ORM映射工具?它与全自动的区别在哪里?
Hibernate属于全自动ORM映射工具,使用Hibernate查询关联对象或者关联集合对象时,
可以根据对象关系模型直接获取,所以它是全自动的。
而Mybatis在查询关联对象或关联集合对象时,需要手动编写sql来完成,
所以,称之为半自动ORM映射工具。
12、使用MyBatis的mapper接口调用时有哪些要求?
① Mapper接口方法名和mapper.xml中定义的每个sql的id相同
② Mapper接口方法的输入参数类型和mapper.xml中定义的每个sql 的parameterType的类型相同
③ Mapper接口方法的输出参数类型和mapper.xml中定义的每个sql的resultType的类型相同
④ Mapper.xml文件中的namespace即是mapper接口的类路径。
13、SqlMapConfig.xml中配置有哪些内容?
properties(属性)
settings(配置)
typeAliases(类型别名)
typeHandlers(类型处理器)
objectFactory(对象工厂)
plugins(插件)
environments(环境集合属性对象)
environment(环境子属性对象)
transactionManager(事务管理)
dataSource(数据源)
mappers(映射器)
14.Mapper编写有哪几种方式?
①接口实现类继承SqlSessionDaoSupport
使用此种方法需要编写mapper接口,mapper接口实现类、mapper.xml文件
1、在sqlMapConfig.xml中配置mapper.xml的位置
<mappers><mapper resource="mapper.xml文件的地址" /><mapper resource="mapper.xml文件的地址" /></mappers>
2、定义mapper接口
3、实现类集成SqlSessionDaoSupport
mapper方法中可以this.getSqlSession()进行数据增删改查。
4、spring 配置
<bean id=" " class="mapper接口的实现"><property name="sqlSessionFactory" ref="sqlSessionFactory"></property></bean>
②使用org.mybatis.spring.mapper.MapperFactoryBean
1、在sqlMapConfig.xml中配置mapper.xml的位置
如果mapper.xml和mappre接口的名称相同且在同一个目录,这里可以不用配置
<mappers><mapper resource="mapper.xml文件的地址" /><mapper resource="mapper.xml文件的地址" /></mappers>
2、定义mapper接口
注意
1、mapper.xml中的namespace为mapper接口的地址
2、mapper接口中的方法名和mapper.xml中的定义的statement的id保持一致
3、 Spring中定义
<bean id="" class="org.mybatis.spring.mapper.MapperFactoryBean"><property name="mapperInterface" value="mapper接口地址" /><property name="sqlSessionFactory" ref="sqlSessionFactory" /></bean>
③使用mapper扫描器
1、mapper.xml文件编写,
注意:
mapper.xml中的namespace为mapper接口的地址
mapper接口中的方法名和mapper.xml中的定义的statement的id保持一致
如果将mapper.xml和mapper接口的名称保持一致则不用在sqlMapConfig.xml中进行配置
2、定义mapper接口
注意mapper.xml的文件名和mapper的接口名称保持一致,且放在同一个目录
3、配置mapper扫描器
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer"><property name="basePackage" value="mapper接口包地址"></property><property name="sqlSessionFactoryBeanName" value="sqlSessionFactory"/></bean>
4、使用扫描器后从spring容器中获取mapper的实现对象
扫描器将接口通过代理方法生成实现对象,要spring容器中自动注册,名称为mapper 接口的名称
15、Mybatis映射文件中,如果A标签通过include引用了B标签的内容,请问,B标签能否定义在A标签的后面,还是说必须定义在A标签的前面?
虽然Mybatis解析Xml映射文件是按照顺序解析的,但是,被引用的B标签依然可以定义在任何地方,Mybatis都可以正确识别。
原理是,Mybatis解析A标签,发现A标签引用了B标签,但是B标签尚未解析到,尚不存在,此时,Mybatis会将A标签标记为未解析状态,然后继续解析余下的标签,包含B标签,待所有标签解析完毕,Mybatis会重新解析那些被标记为未解析的标签,此时再解析A标签时,B标签已经存在,A标签也就可以正常解析完成了。
16、MyBatis实现一对多有几种方式,怎么操作的?
有联合查询和嵌套查询,联合查询是几个表联合查询,只查询一次,通过在resultMap里面配 置collection节点配置一对多的类就可以完成;
嵌套查询是先查一个表,根据这个表里面的 结果的外键id,去再另外一个表里面查询数据,也是通过配置collection,但另外一个表的 查询通过select节点配置。
17、Mybatis的一级、二级缓存:
1)一级缓存: 基于 PerpetualCache 的 HashMap 本地缓存,其存储作用域为 Session,当 Session flush 或 close 之后,该 Session 中的所有 Cache 就将清空,默认打开一级缓存。
2)二级缓存与一级缓存其机制相同,默认也是采用 PerpetualCache,HashMap 存储,不同在于其存储作用域为 Mapper(Namespace),并且可自定义存储源,如 Ehcache。默认不打开二级缓存,要开启二级缓存,使用二级缓存属性类需要实现Serializable序列化接口(可用来保存对象的状态),可在它的映射文件中配置<cache/> ;
3)对于缓存数据更新机制,当某一个作用域(一级缓存 Session/二级缓存Namespaces)的进行了C/U/D 操作后,默认该作用域下所有 select 中的缓存将被 clear,其实是事务commit()之后,才会清除缓存中的数据。

















 638
638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









