




HashMap
数组(Node类型的数组)加链表(或者红黑树),new HashMap时不指定大小,则默认为空,在第一次put数据时候会对Node数组进行扩容,默认大小为16,扩容是耗费性能的,所以阿里手册中创建HashMap时候需要指定容量大小
transient Node<K,V>[] table;
通过计算存入对象的Hash值来计算在数组的索引位置
无Hash冲突时相当于一个数组
当发生Hash冲突时候,冲突的索引位置会以链表的形式解决冲突
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
如果链表的长度大于8,会尝试把链表转化为红黑树。
问题:链表的长度有没有可能大于8?
是存在这种情况的
因为升级为红黑树时会调用treeifyBin方法,该方法会判读当前map的size是否小于64,如果小于64,会先对table进行扩容,如果大于64则转换为红黑树;因此当前map的size小于64是存在链表的长度大于8的情况的。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
....
if (binCount >= TREEIFY_THRESHOLD - 1) //8-1
treeifyBin(tab, hash);
.....
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
// 如果小于64则先resize扩容
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
// 否则才会转为红黑树
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
为什么HashMap的key是乱序的呢?
因为对HashMap取key时,它是按照数组table的顺序进行取值的,而数组table所存储元素的位置又是根据Hash算出来的,所以导致乱序,取key时候如下图:
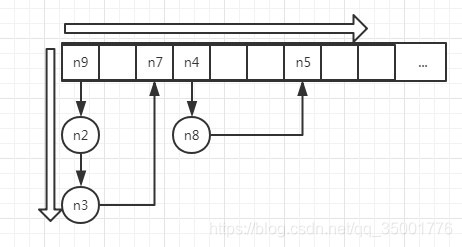
即遍历数组,如果元素为链表,把该数组索引位置的链表遍历完成后,在遍历数组中下一个元素。
如果想要使用key按照添加顺序的map的话,可以使用下面的LinkedHashMap。
LinkedHashMap
继承于HashMap,构造方法如下:
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
前两个参数同HashMap;
accessOrder:是否按照访问次数排序,默认为false,false则按照插入次序排序。
接下来我们看它是如何保证顺序不变的,首先看put方法,它的put方法还是使用的HashMap的put方法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);// newNode是重点
else {
...
}
....
}
其中LinkedHashMap对这个方法进行了重写
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
再看linkNodeLast方法,该方法每次添加新的节点都会添加到原链表的末端
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
发现了head和tail对象,LinkedHashMap维护了两个成员变量,是双向链表
transient LinkedHashMap.Entry<K,V> head;
transient LinkedHashMap.Entry<K,V> tail;
这两个双向列表在每次进行put操作时候都会进行更新,按照插入顺序不断在链表末尾添加新的数据,从而保证了数据的次序性,从而达到获取的key是按顺序显示的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









