




| EMNLP2019 | Doc2EDAG: An End-to-End Document-level Framework for Chinese Financial Event Extraction |
|---|---|
| Author | Shun Zheng, Wei Cao, Wei Xu, Jiang Bian |
| url | https://www.aclweb.org/anthology/D19-1032.pdf |
| Code | https://github.com/dolphin-zs/Doc2EDAG |
大多数现有的事件抽取方法只抽取句子范围的事件参数。但是这种句子级别的事件抽取方法难以解决新兴应用(如金融、法律、卫生等)数量激增的文档。它们的事件论元分散在不同的句子中,甚至多个事件实例在同一文档中同时存在。为了解决这些问题,我们提出了一种新的端到端模型Doc2EDAG,它可以生成一个基于实体的有向无环图来有效地实现文档级事件抽取。此外,我们提出了一个无触发词设计的文档级事件抽取任务,以简化文档级事件标注。为了证明模型的有效性,我们构建了一个包含有上述挑战的中国财务公告的大型真实数据集。综合分析的大量实验证明了Doc2EDAG相对于最新方法的优越性。
1 Introduction
鉴于金融领域文档及业务的特殊性,在做事件抽取的过程中存在一些挑战:
- 事件元素分散(Arguments-scattering):指事件论元可能在不同的句子(Sentence)中
- 多事件(Muti-event):指一个文档中可能包含多个事件
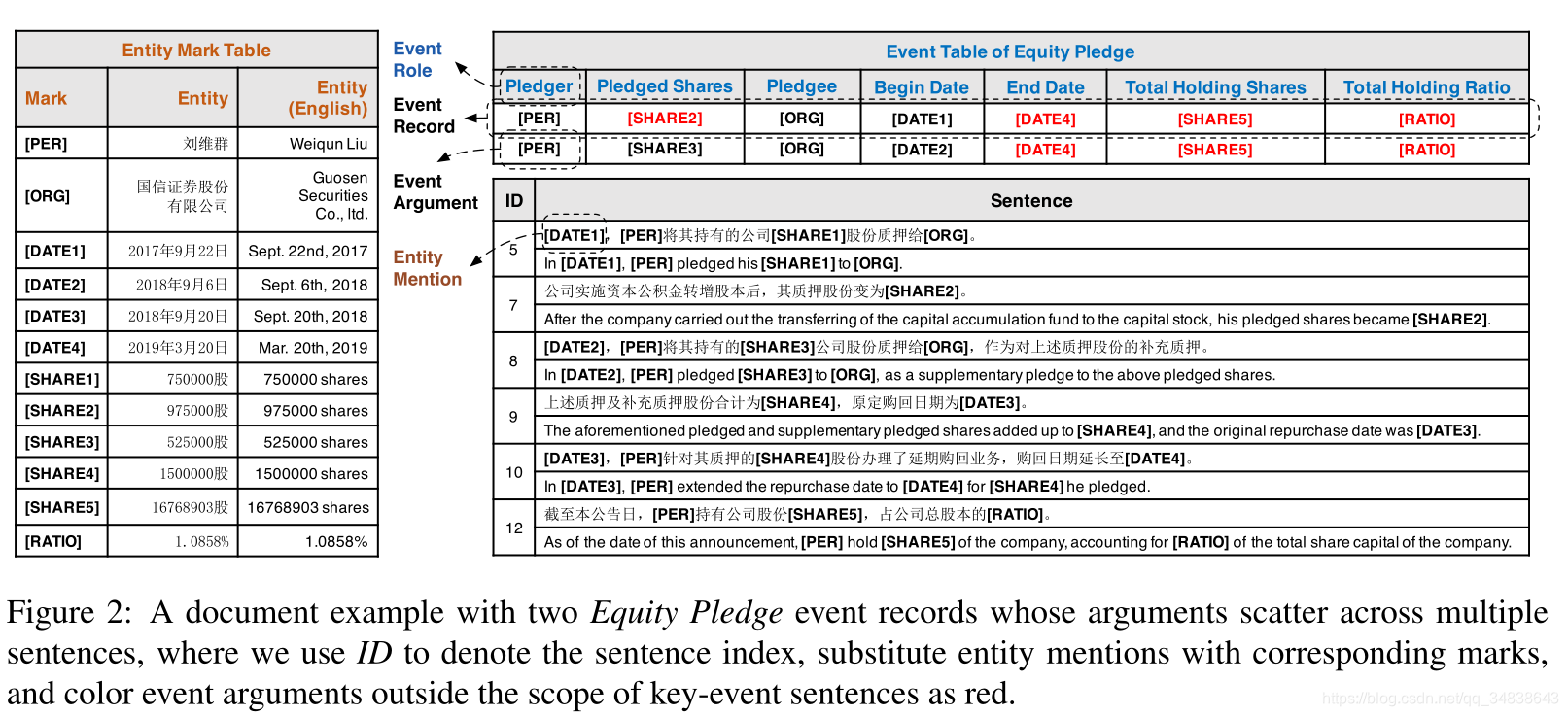
以该图为例,一个文档中有两个股权质押的事件实例,对应Event Table of Equity Pledge表中也就有两条Event record。该事件的角色包括抵押者、抵押的股权量、承押者、开始时间、结束时间、持有股份总数、持有股份占公司股份的比例。
我们以ID作为句子索引,用相应的标记代替实体提及,将关键事件语句范围之外的事件参数颜色显示为红色。则每个事件的论元都可能分布在多个句子中,且大概率是分散分布的。
现如今的研究多是在句子范围内标记事件论元,我们把这类任务称为句子级事件抽取,它显然忽略了我们上面提到的挑战。
在本文中,我们提出了一个新的端到端模型Doc2EDAG,以解决文档级事件抽取(DEE)的独特挑战。该模型的核心思想是将事件表转换为基于实体的有向无环图(EDAG)。EDAG的形式可以将困难的事件表填充任务转换为多个基于实体的顺序路径扩展子任务,这些子任务更容易处理。
为了有效地支持EDAG的生成,Doc2EDAG使用文档级上下文对实体进行编码,并设计了路径扩展的记忆机制。此外,为了简化基于远程监督的文档级事件标注,我们提出了一种新的DEE形式化方法。该方法去除了触发词标注,并将DEE视为直接基于文档填充事件表。这种无触发词设计不依赖任何预定义的触发词集或启发式来过滤多个候选触发词,并且仍然完全符合DEE的最终目标,即将文档映射到底层事件表。
总的来说,本文的贡献在于:
- 提出了一个新的模型Doc2EDAG,它可以直接基于文档生成事件表,有效地解决DEE的独特挑战。
- 重新定义了一个没有触发词的DEE任务,以简化基于远程监督的文档级事件标记。
- 为DEE建立了一个大规模的真实世界数据集,该数据集面临着参数分散和多事件的独特挑战,大量的实验证明了Doc2EDAG的优越性。
2 Preliminaries
我们首先阐明几个基本概念:
- entity mention:实体提及是指一个实体对象的文本块
- event role:事件角色对应事件表的预定义字段
- event argument:事件论元是扮演特定事件角色的实体
- event record:事件记录对应于事件表的一条记录,包含多个所需角色的论元
为了更好地阐述和评估我们提出的方法,我们在本文中利用了ChFinAnn数据。ChFinAnn文档包含中国股市上市公司的第一手官方信息,有数百种类型,如年报和盈利预测。在进行这项工作时,我们将重点放在那些与事件相关的,频繁,有影响力且主要由自然语言表达的事件上。
3 文档级事件标注
作为DEE的前提工作,我们首先在文档级别进行基于远程监督的事件标注。更具体地说,我们将表格记录从事件知识库映射到文档文本,然后将较为匹配的记录视为该文档所表示的事件。此外,我们采用了无触发词设计,并相应地重新设计了新的DEE任务,以实现端到端模型设计。
Event Labeling:
为了保证标记质量,我们对匹配的记录设置了两个约束
- 预定义键的事件角色的论元必须存在
- 匹配的论元的个数要大于某个阈值
这些约束的配置是特定于事件的。在实践中,我们可以对它们进行优化从而直接确保文档级别的标签质量。我们把满足这两个约束条件的记录视为匹配较好的记录,这些记录充当了受远程监督的基本事实。除了标记事件记录之外,我们将论元的角色分配给匹配的token,作为token-level实体标签。注意,我们没有显式地标记触发词。除了不影响DEE功能之外,这种无触发词的设计的另一个好处是基于远程监督的标注更容易,它不依赖于预定义的触发词词典或者手动引导的启发式方法来过滤多个潜在的触发词。
DEE Task Without Trigger Words:
我们将DEE的一个新任务重新定义为基于文档直接填充事件表,通常需要三个子任务:
- 实体抽取:抽取实体提及作为候选论元
- 事件检测:判断一个文档是否触发某个事件类型
- 事件表填充:将论元填充到触发的事件对应的表中
这种新颖的文档级的事件抽取和传统的句子级事件抽取任务有很大不同,但是和上述基于远程监督的事件标签的简化方法是一样的。
4 模型
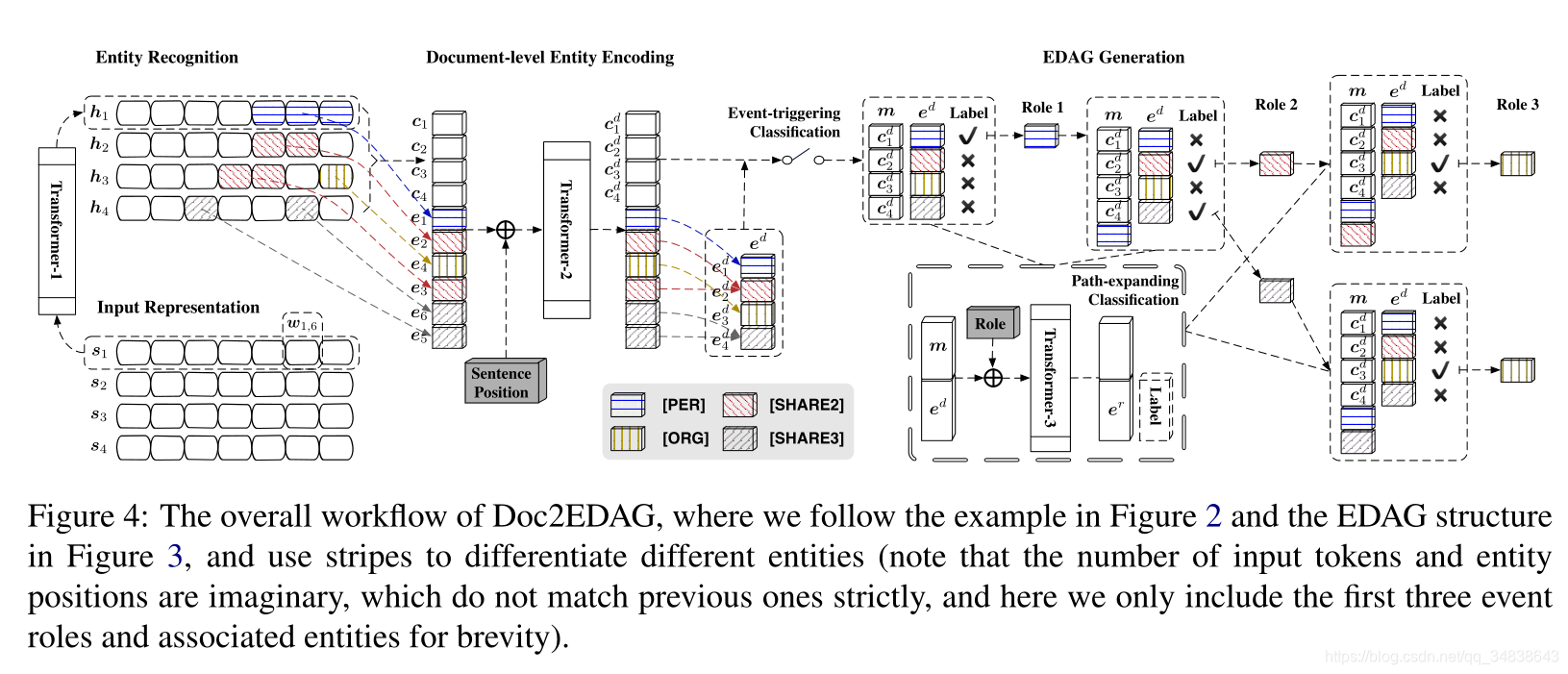
Doc2EDAG的核心思想是将表格式的事件记录转换为EDAG,并让模型基于文档级上下文学习生成该EDAG。根据Figure 2中的示例,Figure 3描述了EDAG生成的过程。Figure 4显示了Doc2EDAG的总体工作流程,其中包括两个关键阶段:文档级实体编码和EDAG生成。在详细介绍它们之前,我们首先描述两个预处理模块:输入表示和实体识别。
输入表示:
本文中,我们将文档表示为一系列句子。查找token embedding表 V ∈ R d w ∗ ∣ V ∣ V \in \mathbb{R} ^ {d_w * |V|} V∈Rdw∗∣V∣,我们把文档表示为句子序列 [ s 1 ; s 2 ; . . . ; s N s ] [s_1;s_2;...;s_{N_s}] [s1;s2;...;sNs],每一个句子 s i ∈ R d w ∗ N w s_i \in \mathbb{R} ^ {d_w * N_w} si∈Rdw∗Nw 都是由token embeddings的序列组成的,如 [ w i , 1 , w i , 2 , . . . , w i , N w ] [w_{i,1},w_{i,2},...,w_{i,N_w}] [wi,1,wi,2,...,wi,Nw]。其中
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1895
1895

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









