







1 什么是原子操作
原子操作是一种不可分割的操作,执行过程不会由于线程调度被切换,意味着多个线程访问同一个资源时,当前仅有一个线程会对资源进行操作。这种特性使得原子操作在保证数据一致性和线程安全方面具有显著优势。
多线程编程的核心问题时,如何保证数据的一致性。传统使用锁机制使得线程进入阻塞,存在死锁风险。而原子操作是通过硬件支持,提供了一种轻量级的同步机制,有效避免了上述问题。
无原子操作的问题
如果不是原子操作时,可能会导致读写撕裂问题。
比如一个简单的赋值操作,编译器会使用两条机器指令来执行,第一条指令设置低32位的0×00000002,第二条指令设置高32位的0×00000001.非常明显,这个赋值操作是非原子的。如果共享变量同时被不同的线程存取,就会出现很多错误:
- 如果一个线程在两个机器指令的间隙先调用存储变量,将会在内存中留下像0×0000000000000002这样的值——这是一个写撕裂。在这个时候,如果另一个线程读取共享变量,它将会接收到一个完全伪造的、没有人想要存储的值。
- 更糟糕的是,如果一个线程在两个机器指令的间隙先占用变量,而另一个线程在第一个线程重新获得这个变量之前修改了sharedValue,那将导致一个永久性的写撕裂:一个线程得到高32位,另一个线程得到低32位。
- 在多核设备上,并不是只有先行占有其中一个线程来导致一个写撕裂。当一个线程调用storeValue时,任何线程在另一个核上可能同时读取一个明显未修改完的sharedValue。
2 使用方法
2.1 原子类型
#include <atomic>
atomic<T> x;
2.2 内存序
了解内存序,有助于提高原子操作的性能和正确性。内存序控制了原子操作在多线程环境中的执行顺序,主要有以下几种:
| value | 顺序 | 含义 |
|---|---|---|
| memory_order_relaxed | 宽松 | 不保证操作的顺序,仅保证操作的原子性。适用于对顺序没有严格要求的场景,如简单的计数器 |
| memory_order_acquire | 获取 | 当前线程中读或写不能被重排到此加载之前。其他线程的所有释放同一原子变量的写入,能为当前线程所见。 |
| memory_order_release | 当前线程中的读或写不能被重排到此存储之后。当前线程的所有写入,可见于获得该同一原子变量的其他线程 | |
| memory_order_acq_rel | 当前线程的读或写内存不能被重排到此存储之前或之后。所有释放同一原子变量的线程的写入可见于修改之前,而且修改可见于其他获得同一原子变量的线程。适用于读-改-写操作 | |
| memory_order_seq_cst | 最严格的内存序,进行获得操作和释放操作,再加上存在一个单独全序,其中所有线程以同一顺序观测到所有修改。适用于对顺序有严格要求的场景 |
2.2.1 memory_order_relaxed
memory_order_relaxed仅保证原子性,但是多个线程同时对一个变量进fetch_add操作时并不会有同步一致性问题,这是因为:
(1)缓存一致性协议
现代多核CPU通常具有多级缓存(L1、L2、L3等),每个核有自己的私有L1和L2缓存,而L3缓存可能是共享的。在多核处理器系统中,每个核心可能会在其本地缓存中存储内存位置的副本。这可能导致一个核心上的线程修改了数据,而这个修改没有立即反映到其他核心的缓存中,从而导致缓存不一致。
为了解决这个问题,现代CPU使用缓存一致性协议(如MESI协议),确保多个CPU核心之间的缓存保持一致。当一个核心修改了它的缓存中的数据时,其他核心的缓存副本将被标记为无效,并在需要时从主内存中重新加载最新数据。
CPU内核 0 CPU内核 1 CPU内核 N
| | |
L1 Cache L1 Cache L1 Cache 【1级缓存】
| | |
L2 Cache L2 Cache L2 Cache 【2级缓存】
| | |
...........共享的L3 Cache......... 【共享区】
|
主内存 (RAM)
但是无法保证数据顺序一致性,比如下面的例子
std::atomic<bool> flag(false); // 用于同步的原子标志
std::vector<int> data;
void producer() {//生产者线程
data.push_back(42);
flag.store(true, std::memory_order_relaxed);
}
void consumer() {//消费者线程
while (!flag.load(std::memory_order_relaxed)) {
std::this_thread::yield(); //主动让CPU切换线程,避免忙等
}
for (int val : data) {
std::cout << "消费者-》收到数据: " << val << std::endl;
}
}
在这个栗子中,对flag的操作是原子的,但consumer有可能在flag置位时仍无法获取到数据,由于以下两个原因:
- 指令重排:生产者线程先操作
flag,再写data - 缓存更新:消费者线程的缓存只同步到了
flag的缓存,还没有同步data的缓存。最终缓存数据是一致的,但是存在数据不一致的瞬间。
2.2.2 memory_order_acquire和release
memory_order_acquire- 阻止之后的读和写操作被重排序到原子操作之前。且立刻获得其他线程对该原子变量的写入memory_order_release- 阻止之前的读和写操作被重排序到原子操作之后。且对该原子变量的写入操作能被其他线程缓存更新可见
对于2.2.1中的栗子,我们可以修改为以下代码:
std::atomic<bool> flag(false); // 用于同步的原子标志
std::vector<int> data;
void producer() {//生产者线程
data.push_back(42);
flag.store(true, std::memory_order_relased);
}
void consumer() {//消费者线程
while (!flag.load(std::memory_order_acquire)) {
std::this_thread::yield(); //主动让CPU切换线程,避免忙等
}
for (int val : data) {
std::cout << "消费者-》收到数据: " << val << std::endl;
}
}
这样:
- 指令重排消失:生产者线程
flag被设置后data一定有数据
2.2.4 memory_order_acq_rel
同时包含acruire和release的语义,memory_order_acq_rel就是所有的写要在原子之前,所有的读要在原子操作之后,很明显这个原子操作附近就成了隔离带。
例子
#include <atomic>
#include <thread>
#include <vector>
#include <iostream>
std::atomic<int> counter(0); // 原子计数器
void increment(int id) {
for (int i = 0; i < 10; ++i) {
int old_count = counter.fetch_add(1, std::memory_order_acq_rel);
std::cout << "Thread " << id << " incremented counter to " << old_count + 1 << std::endl;
}
}
int main() {
const int num_threads = 4;
std::vector<std::thread> threads;
for (int i = 0; i < num_threads; ++i) {
threads.push_back(std::thread(increment, i));
}
for (auto& t : threads) {
t.join();
std::cout << "Final counter value is " << counter.load() << std::endl;
return 0;
}
最终显示为不仅最后数据是对的,中间每次执行都是实时的,fetch_add本身就是个读写操作。
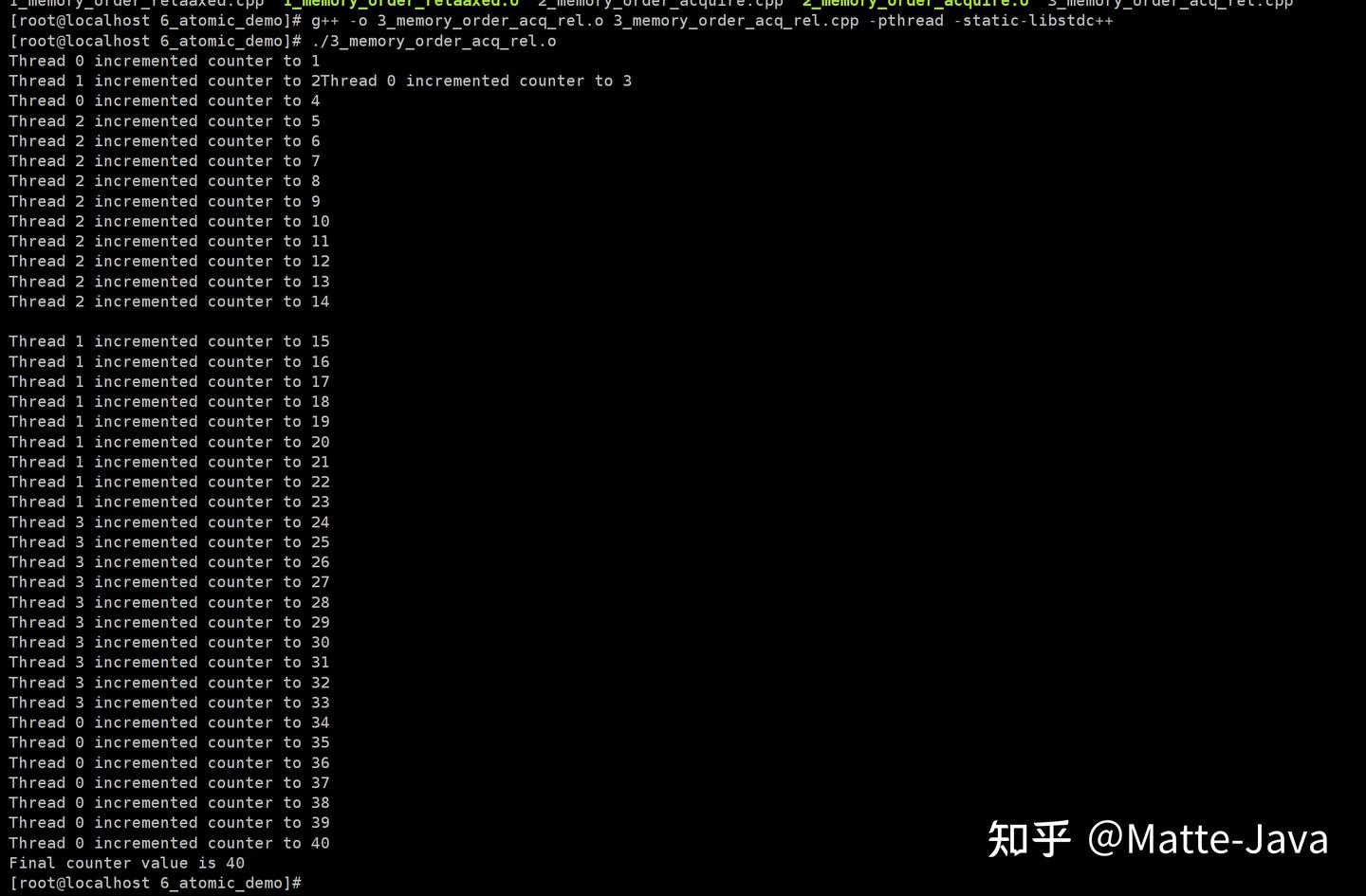
2.2.5 memory_order_seq_cst
https://zhuanlan.zhihu.com/p/454915077
memory_order_seq_cst 与 memory_order_acq_rel 的主要区别在于全局顺序的保证:
memory_order_seq_cst保证了所有线程看到的全局顺序,这意味着所有使用memory_order_seq_cst的原子操作都遵循相同的顺序,无论是读操作、写操作还是读-修改-写操作。memory_order_acq_rel只保证了读-修改-写操作的局部顺序,并且只在获取-释放对之间提供同步。它不保证全局顺序,也不保证独立的读操作或写操作之间的顺序。
2.3 API
2.3.1 构造函数
std::atomic::atomic();
//示例
std::atomic<bool> ready(false);
(1) 默认构造函数:使对象处于未初始化状态。 atomic() noexcept = default;
(2) 初始化 :使用val初始化对象。constexpr atomic (T val) noexcept;
(3) 复制 [删除] :无法复制/移动对象。 atomic (const atomic&) = delete;
2.3.2 is_lock_free()
指示该原子对象是否无锁,无锁时不会导致其他线程访问时阻塞。
bool is_lock_free() const noexcept;
如果对象是无锁的 返回true.
2.3.3 store()
修改包含的值。将包含的值替换为val,该操作为原子操作。
参数memory_order的枚举值见章节2.2
void store (T val, memory_order sync = memory_order_seq_cst) noexcept;
//示例
std::atomic<int> foo (0);
foo.store(x, std::memory_order_relaxed); // set value atomically
2.3.4 load
读取包含的值,返回包含的值。该操作是原子操作。
T load (memory_order sync = memory_order_seq_cst) const volatile noexcept;
T load (memory_order sync = memory_order_seq_cst) const noexcept;
// 示例
std::atomic<int> foo (0);
int x = foo.load(std::memory_order_relaxed); // get value atomically
2.3.5 exchange
访问和修改包含的值,将包含的值替换并返回它前面的值。
整个操作是原子的(原子读-修改-写操作):从读取(要返回)值的那一刻到此函数修改值的那一刻,该值不受其他线程的影响。
T exchange (T val, memory_order sync = memory_order_seq_cst) noexcept;
std::atomic<bool> winner (false);
winner.exchange(true);
2.3.8 其他接口
这些接口和上面接口的使用并无差异:
| 操作 | 含义 |
|---|---|
| fetch_add | 添加到包含的值并返回它在操作之前具有的值 |
| fetch_sub | 从包含的值中减去,并返回它在操作之前的值。 |
| fetch_and | 读取包含的值,并将其替换为在读取值和 之间执行按位 AND 运算的结果。 |
| fetch_or | 读取包含的值,并将其替换为在读取值和 之间执行按位 OR 运算的结果。 |
| fetch_xor | 读取包含的值,并将其替换为在读取值和 之间执行按位 XOR 运算的结果。 |
3 代码实例
3.1
#include <iostream> // std::cout
#include <atomic> // std::atomic, std::memory_order_relaxed
#include <thread> // std::thread
std::atomic<int> count(0); // 准确初始化
void set_count(int x)
{
std::cout << "set_count:" << x << std::endl;
count.store(x, std::memory_order_relaxed); // set value atomically
}
void print_count()
{
int x;
do {
x = count.load(std::memory_order_relaxed); // get value atomically
} while (x==0);
std::cout << "count: " << x << '\n';
}
int main ()
{
std::thread t1 (print_count);
std::thread t2 (set_count, 10);
t1.join();
t2.join();
std::cout << "main finish\n";
return 0;
}
3.2
测试时要让for循环时间大于操作系统时间片,才能测出来原子操作和简单++的差异
g++ test.cpp -pthread
#include <iostream>
#include <unistd.h>
#include <string>
#include <cstring>
#include <atomic>
#include <thread>
typedef struct ITEM
{
std::atomic<int> a{0};
std::atomic<int> b{0};
}ITEM;
void thread_func(ITEM& item)
{
for(int i=0; i < 20000; ++i)
{
item.a.fetch_add(1, std::memory_order_relaxed);
}
std::cout<<"thread_func"<<std::endl;
}
void thread_func_sub(ITEM& item)
{
for(int i=0; i < 20000; ++i)
{
item.a.fetch_sub(1, std::memory_order_relaxed);
}
std::cout<<"thread_func_sub"<<std::endl;
}
int main()
{
ITEM item;
std::thread t1(thread_func, std::ref(item));
std::thread t2(thread_func, std::ref(item));
std::thread t3(thread_func, std::ref(item));
std::thread t4(thread_func, std::ref(item));
std::thread t5(thread_func, std::ref(item));
std::thread t6(thread_func, std::ref(item));
std::thread t7(thread_func, std::ref(item));
std::thread t8(thread_func_sub, std::ref(item));
t1.join();t2.join();t3.join();t4.join();
t5.join();t6.join();t7.join();t8.join();
sleep(3);
std::cout<<item.a.load(std::memory_order_relaxed)<<std::endl;
return 0;
}
4 原子操作使用及注意
4.1 原子操作不能拷贝
只要是原子操作,都不能进行赋值和拷贝。拷贝构造和拷贝赋值都将读取第一个对象,然后再写入另外一个。对于两个独立的对象,这里就有两个独立的操作了,因此操作就不被允许,如:
#include <iostream>
#include <atomic>
int main() {
std::atomic<int> atomicValue(10);
// 不能进行赋值操作
std::atomic<int> anotherAtomicValue = atomicValue; // 编译错误
// 不能进行拷贝操作
// std::atomic<int> copiedAtomicValue(atomicValue); // 编译错误
return 0;
}
4.2 尽量不要使用=号给原子变量赋值
如果代码涉及到多线程,并希望确保线程安全性,那么尽量使用 .load() 和 .store(),即使 = 操作符在很多情况下也能工作。
load()和store()能清楚地表达出原子操作的意图,使代码在多线程环境下更安全、更可读- 函数内部提供了跨平台一致性
- 提供了更丰富的内存序选项
5 原子操作和锁机制场景分析
原子操作的优点:
性能高:原子操作由硬件直接支持,通常比锁机制更高效。
避免死锁:由于不使用锁,原子操作避免了死锁问题。
原子操作的缺点:
适用范围有限:原子操作适用于简单的同步场景,对于复杂的同步需求,可能需要借助锁机制。
代码复杂性:在一些情况下,使用原子操作的代码可能比使用锁机制的代码更复杂。
锁机制的优点:
适用范围广:锁机制可以处理复杂的同步需求,如保护复杂的数据结构、实现复杂的同步逻辑等。
代码简单:在某些情况下,使用锁机制的代码比使用原子操作的代码更简单直观。
锁机制的缺点:
性能开销大:锁机制会引入额外的上下文切换和系统调用,导致性能下降。
死锁风险:不当的锁管理可能导致死锁,影响程序的稳定性。

















 26
26

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









