




 本文深入探讨了逻辑回归在二分类问题中的应用,通过对比线性回归,介绍了S型函数如何将模型输出转换为概率,实现0到1之间的预测,并详细解释了决策边界的确定方法。
本文深入探讨了逻辑回归在二分类问题中的应用,通过对比线性回归,介绍了S型函数如何将模型输出转换为概率,实现0到1之间的预测,并详细解释了决策边界的确定方法。
机器学习(六)逻辑回归—二分类问题
前言:
前面讲到的线性回归都是属于对样本数据拟合,得到学习器,进而预测数据的方法。本节学习逻辑回归,一种数据的监督分类方法。对于分类问题,本节我们首先主要学习两种类别的分类问题
例如:
| 举例 | 类别 |
|---|---|
| 邮件 | 垃圾邮件/非垃圾邮件(YES/NO) |
| 在线交易 | 欺诈交易/非欺诈交易(YES/NO) |
| 肿瘤 | 恶性/良性(YES/NO) |
二分类问题,即分类结果 y∈{0,1},0代表NO(负类);1代表YES(正类)
一、分类问题的线性回归
假设根据肿瘤大小(size)判断肿瘤是恶性还是良性,依据线性回归的思路如下:
1、假设函数 hθ(x)=θTx ,其中θ 和x都是向量
2、对于最终的学习器我们可能得到如下图两种情况:
分类原则:因为我们是二分类问题,y要么为0,要么为1,因此假设 hθ(x)>0.5,则y=1; hθ(x)<=0.5,则y=0;

得到上图的线性回归,根据训练样本可以看到,直线hθ(x)能够正确得到分类结果,即设 hθ(x)>0.5,则分类为恶性肿瘤; hθ(x)<=0.5,则分类为良性肿瘤

但是,如果得到类似上图的线性回归直线,我们可以发现根据我们的分类原则,圆圈里面的恶性肿瘤别分类为了良性肿瘤,那么分类结果就是错误的!!!
由上面两幅图,我们可以知道线性回归并不能很好的解决分类问题,大部分情况下我们不会使用线性回归解决分类问题
二、分类问题的逻辑回归
1、逻辑回归模型
对于线性模型 hθ(x),我们发现它的取值范围是(-∞,+∞),而我们的分类结果y的取值范围是y∈{0,1},即y要么是1,要么是0;那么由此也能看出用线性模型解决分类问题是不可靠的。那么我们需要找到一个模型,这个模型要有一个特征,那就是该模型的取值范围在0~1之间,即 hθ(x)∈(0,1),那么在数学中有一个S型函数就满足这个特征。
S型函数为:g(z) = 1/(1+e-z),了解数学中的极限的,一定能发现这个函数当自变量z趋向于-∞时,因变量g(z)趋向于0;当自变量z趋向于+∞时,因变量g(z)趋向于1;
S型函数图形如下:

由此,我们得到满足二分类要求的逻辑回归模型为:

2、逻辑回归模型的假设函数 hθ(x)计算结果的含义
hθ(x)的计算值是在输入x的情况下,y=1的概率值。
例如:
根据肿瘤大小,判断肿瘤是恶性还是良性,如果 hθ(x)=0.7,则该肿瘤为恶性的概率是70%
关于 hθ(x)的计算输出值的含义,用数学表达如下:
hθ(x)=P(y=1 | x,θ);
因为y=0 或1,则P(y=0 | x,θ)+P(y=1 | x,θ)=1,即,P(y=0 | x,θ)=1-P(y=1 | x,θ);
3、决策边界(分类器)确定
根据S函数的图形可知,对于假设函数 hθ(x)=g(θTx),
如果假设 hθ(x)>=0.5 ,即y=1的概率大于50%,则y=1,即θTx>=0;
如果假设 hθ(x)<0.5 ,即y=1的概率小于50%,则y=0,即θTx<0;
例1,假设函数hθ(x)=g(θ0+θ1x1+θ2x2),其样本数据分布如下图

假设求得,θ0=-3;θ1=1;θ2=1;则hθ(x)=g(-3+x1+x2),
则,如果y=1,则-3+x1+x2>=0,即x1+x2>=3;
如果y=0,则-3+x1+x2<0,即x1+x2< 3;
由此可得到线性决策边界如下图:

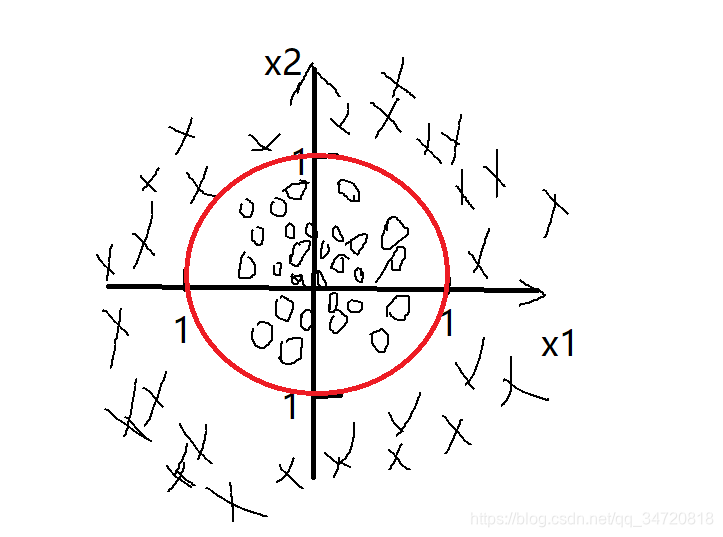
例2,假设函数hθ(x)=g(θ0+θ1x1+θ2x2+θ3x12+θ4x22),其样本数据分布如下图

假设求得,θ0=-1;θ1=0;θ2=0;θ3=1;θ4=1;;则hθ(x)=g(-1+x12+x22),
则,如果y=1,则-1+x12+x22>=0,即x12+x22>=1;
如果y=0,则-1+x12+x22<0,即x12+x22< 1;
由此可得到非线性决策边界如下图:


















 1256
1256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











