




Aggregating Sequential Views for 3D Global Feature Learning by CNN with Hierarchical Attention Aggregation
使用分层注意聚合的CNN聚合顺序视图进行三维全局特征学习
关键词:
3D2SeqViews;层次注意力聚合;递归视图集成;视图注意力机制
解决的问题:
在深度学习模型中,视图聚合所带来的内容信息和空间关系的损失,通过更有效地聚合多个视图的内容信息和空间关系来学习三维特征仍然是一个研究挑战。
原理:
3D2SeqViews概述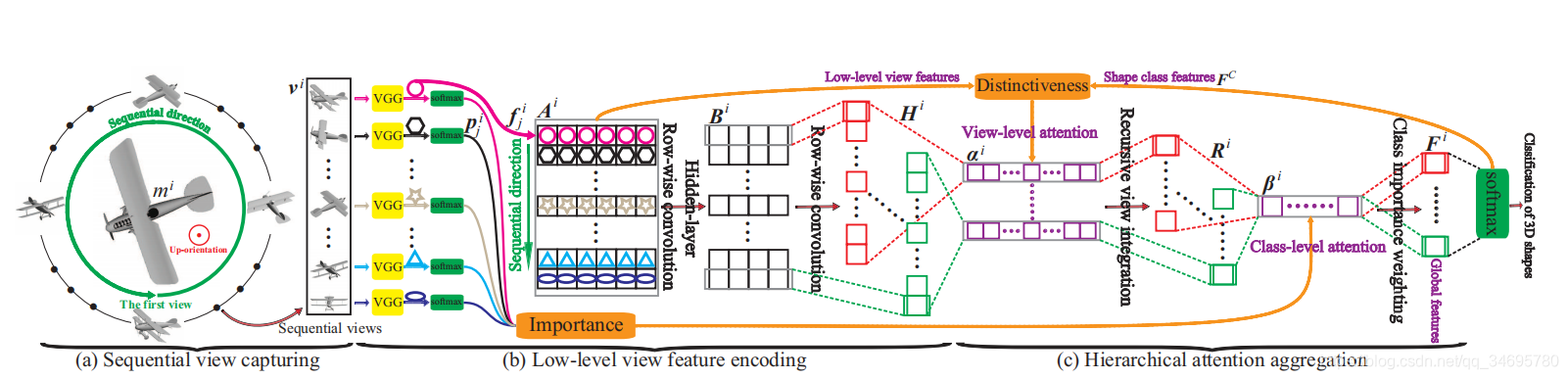 顺序视图首先在(a)中的圆圈上围绕每个向上的三维图形捕捉。然后,通过微调VGG网络提取后,对每个视图的低级特征进行逐行卷积编码,如(b)所示。最后,通过在分层注意聚合中聚合顺序视图来学习全局三维特征。
顺序视图首先在(a)中的圆圈上围绕每个向上的三维图形捕捉。然后,通过微调VGG网络提取后,对每个视图的低级特征进行逐行卷积编码,如(b)所示。最后,通过在分层注意聚合中聚合顺序视图来学习全局三维特征。
(1) 序列视图捕获
与传统的多视图捕获不同,序列视图是在一个圆圈上捕获的,而不是单位球体上捕获的。 虽然序列视图不能完全覆盖三维形状的顶部或底部,但序列视图中的内容信息可以更有效地聚合,同时保持视图之间的顺序空间性,用于三维全局特征学习。
(2) 低级视图特征编码
首先通过微调VGG19提取vi中每个视图vij的低级特征fij。 然后,通过使用逐行卷积降低低层特征的维数,抽象出每个视图中的内容信息。 最后,抽象的内容信息通过逐行卷积将所有Vij进一步编码成一组Hi列式特征映射。 在Hi中的内容信息和vi的顺序空间性随后通过分层注意聚合进行聚合。
(3) 分层注意聚合
是想将编码的内容信息聚合在序列视图中,并将视图之间的序列空间用于学习三维全局特征。 此外,需要注意的是视图级注意
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









