




1 说明
6月7日23点左右,应用侧反馈说有个程序跑得慢,未找到原因,快速看一下数据库等待事件、活跃会话和主机负载情况也未发现异常,平时这时候就可以糊弄过去了,但是有领导的领导关注这件事,所以就需要排查清楚数据库到底有没有问题,好将锅甩回去。
根据应用反馈,这个应用程序是当天凌晨就开始有跑了,下午发现慢,发起重跑,到了晚上发现也不行,才跟我们说,所以就有了开头这一幕。
2 排查过程
跟应用确认好所属库、应用进程名、应用主机名、时间点就可以开始排查了,排查过程如下。
2.1 查看当前负载情况
主要查一下主机和数据库层面整体的负载情况,以供参考。
一、主机负载
主要看cpu使用率、内存使用率、IOPS和网络吞吐量等情况:
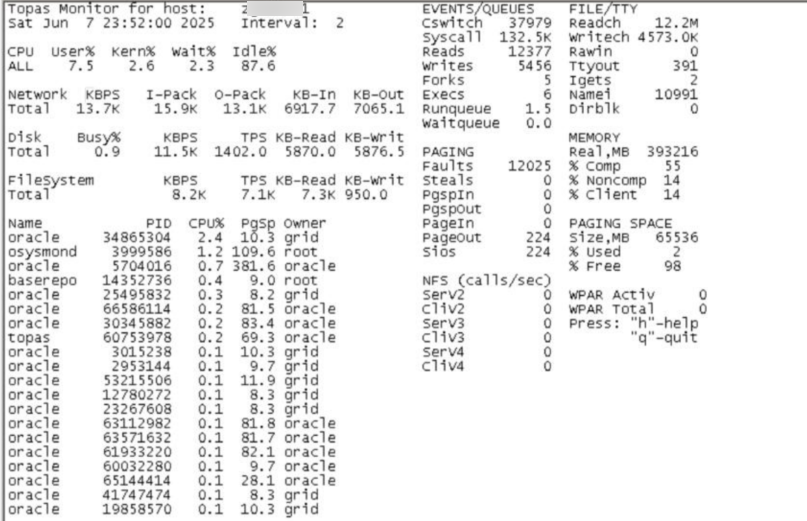
当前主机负载都不高。
二、数据库负载
查看时间点前后两天dbtime的情况:
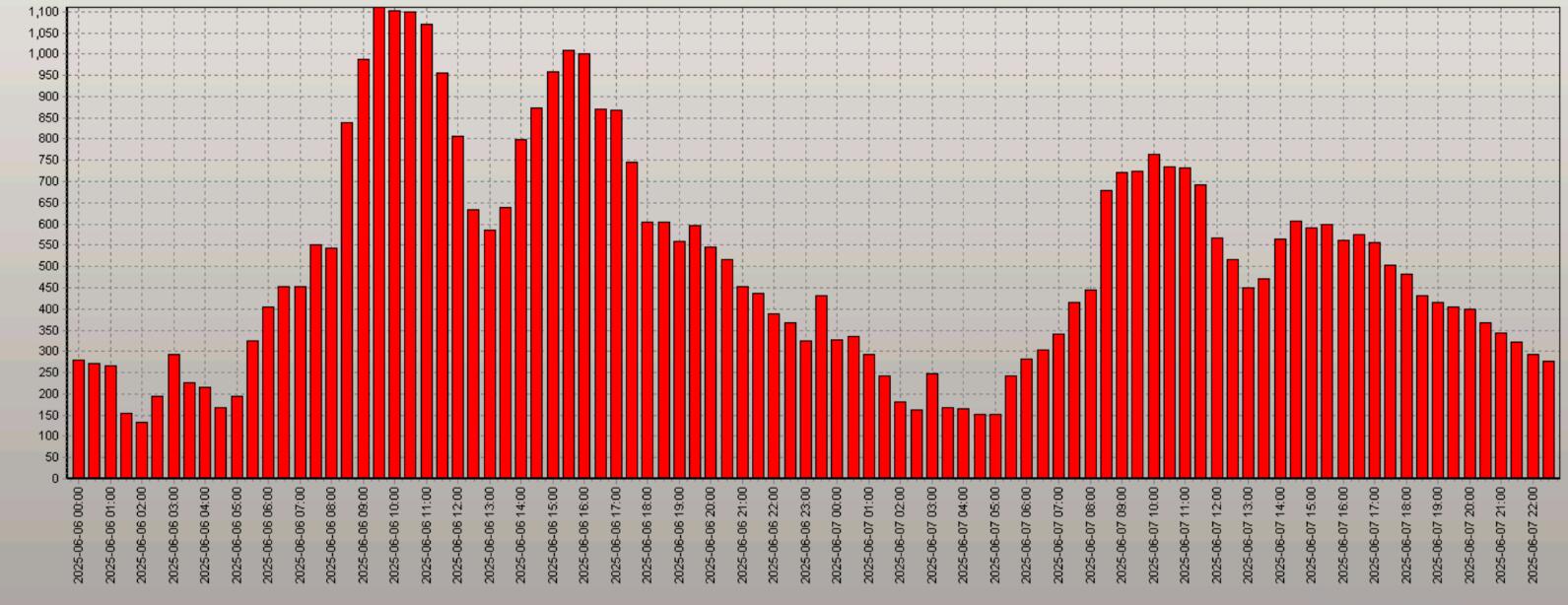
这台aix主机逻辑cpu个数是176,一个快照dbtime要达到5280才是高负载,上图所示dbtime大部分时间在几百,表明数据库层面是没什么负载了,并且问题发生时间点的dbtime总体上比前一天的还要低。
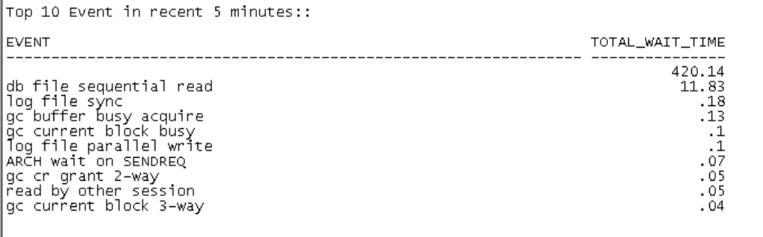
三、等待事件
近5分钟也并无异常等待,不过可以看到单块读和log file sync等待靠前,说明数据库主要是IO方面等待。
2.2 当前会话情况
根据应用提供的进程名,查看当前的会话情况:

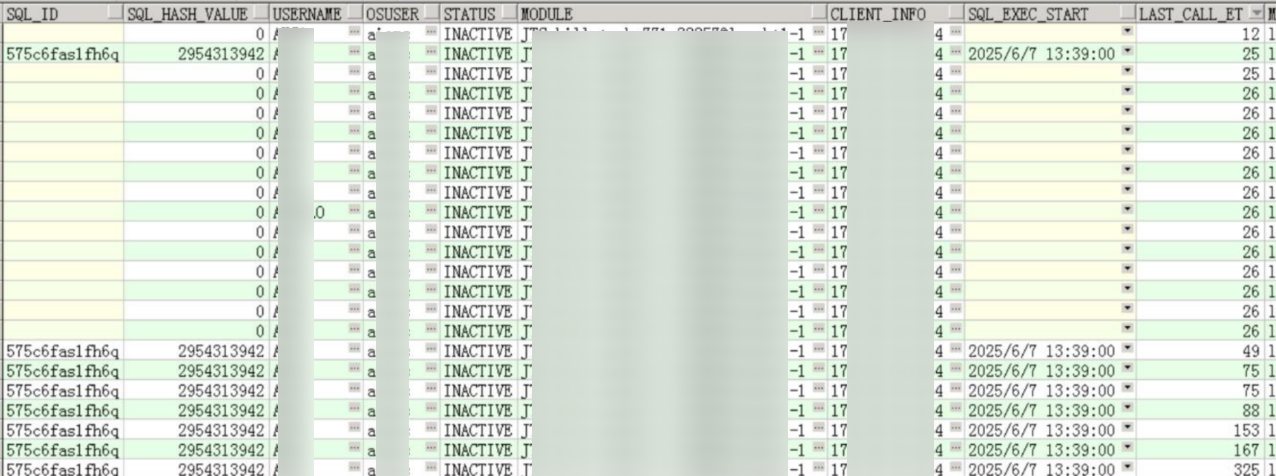
都是非活动会话,并且最后一次调用时间大部分在几十秒之前,说明应用进程没有快速大量执行的语句,至少是间隔执行的。
这和应用反馈跑不出来的说法有点不太相符,跑不出来应该是有活跃会话执行很久的情况才是。
留意一下出现的sql_id,极有可能是topsql。
2.3 历史活跃会话情况
当前会话情况没看出啥,那就看一下历史的会话情况。
一、历史活跃会话数
查看进程相关的活跃会话数:

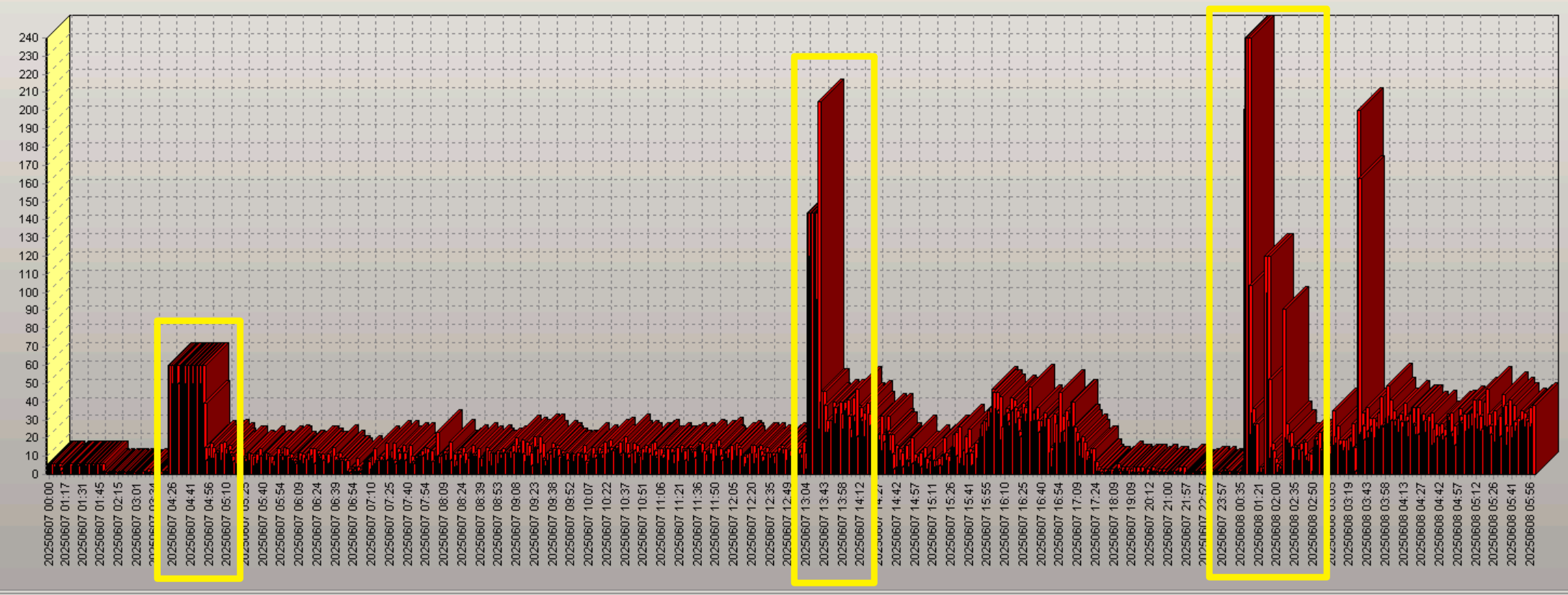
可以发现,有三波连接风暴,每分钟由十几二十个连接数翻了几倍到十几倍。前两个时间段基本能对的上应用说的时间,接下来重点找这两个时间段(4:25左右和13:40左右)都有在执行的topsql。最后一波应该是应用的人发起的最新一次任务,先不用关注。
二、SQL历史执行情况
查看SQL总活跃会话数、平均等待时间:
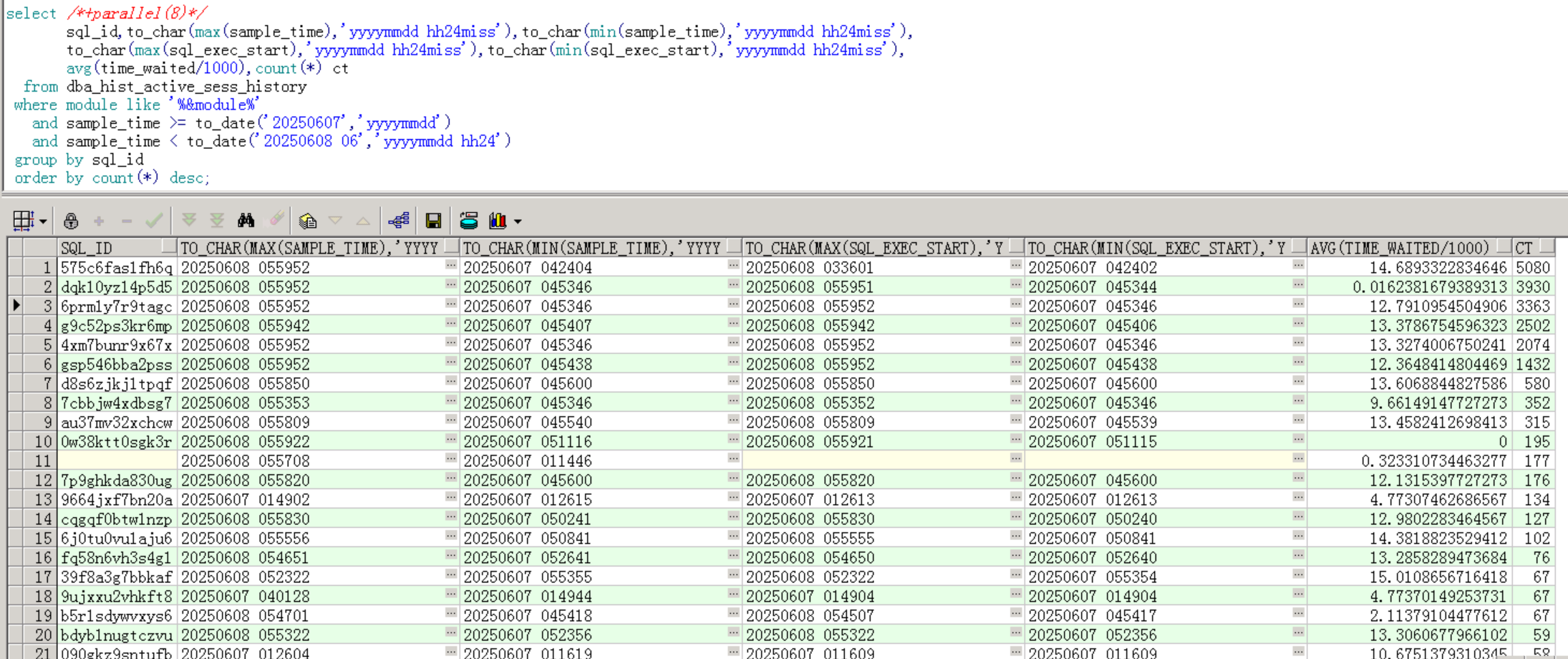
注意到第一个sql,总活跃会话数最多,这里并不等于总的执行次数,可以说明持续时间久,执行时间最长。会话平均等待14s,并且也是刚才上面查看当前会话中的sql,需要重点关注。
再检查一下最小开始执行时间,貌似发现也只有第一个在4:25左右执行的。
2.3 SQL执行情况
一、查看sql执行时间
查看各个sql的开始执行开始时间和执行时长:

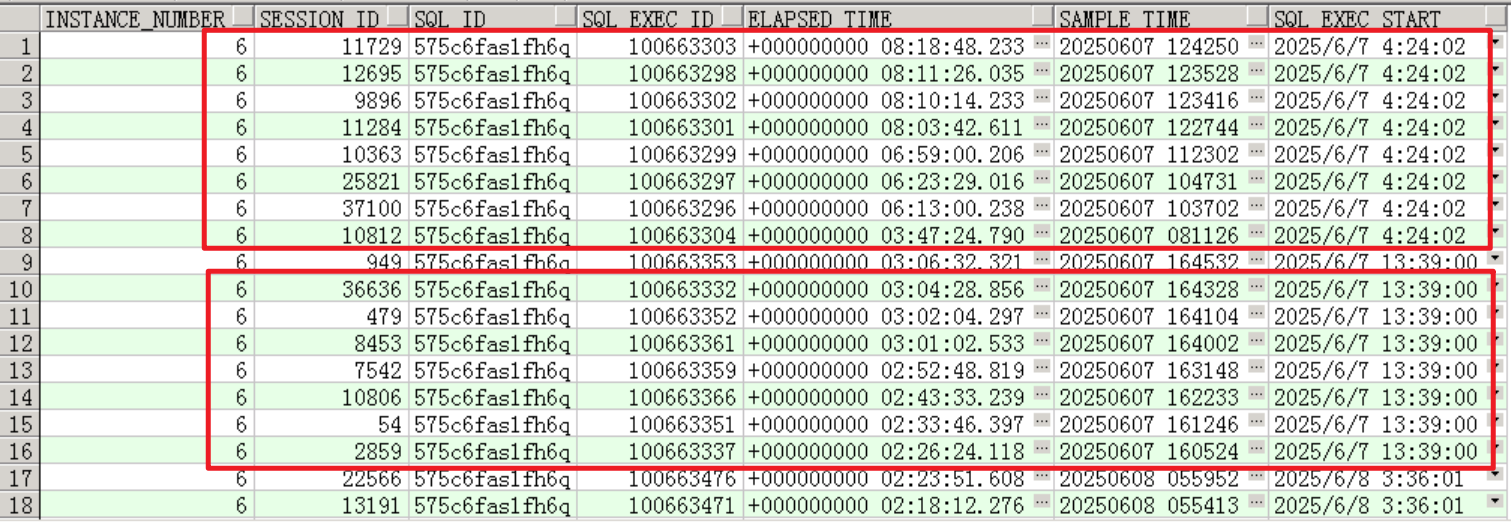
可以看到,这两个sql执行时间段基本吻合上面活跃会话突增的时间,第一次执行时间在凌晨4:24分,第二次在下午13:39分。
到这里基本能确认这个语句是比较关键的了,而且4:24第一次的执行时间超过8小时,说明sql性能有很大问题,程序跑不出来十有八九就是因为这个语句。
二、统计SQL历史执行信息
查看topsql在过去一段时间内按照快照的统计信息,主要包括执行计划hash_value、执行次数、平均执行时间和io等待等:
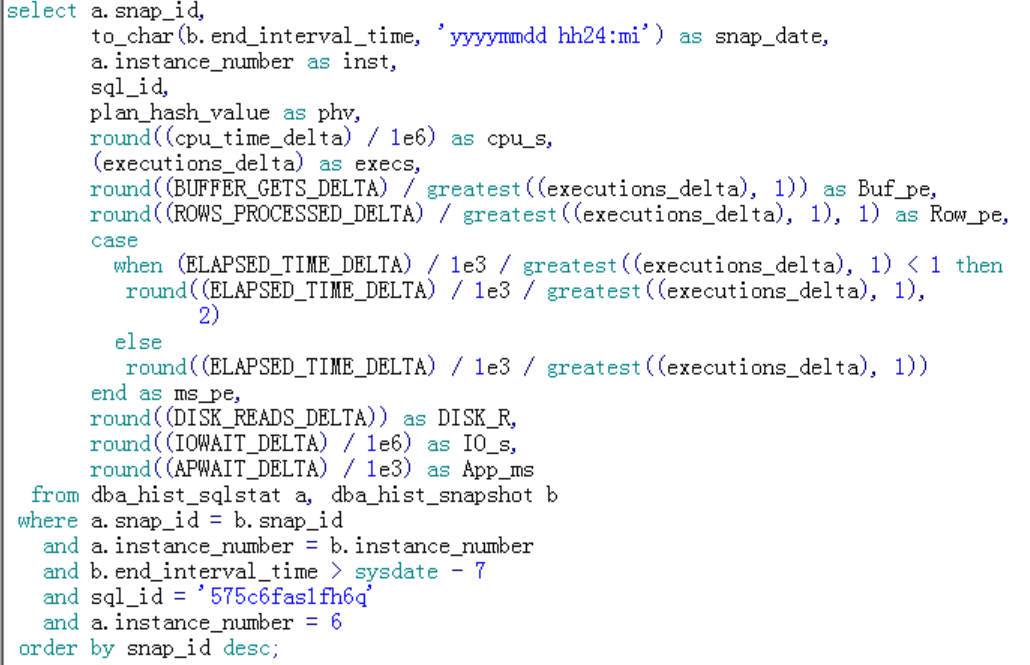
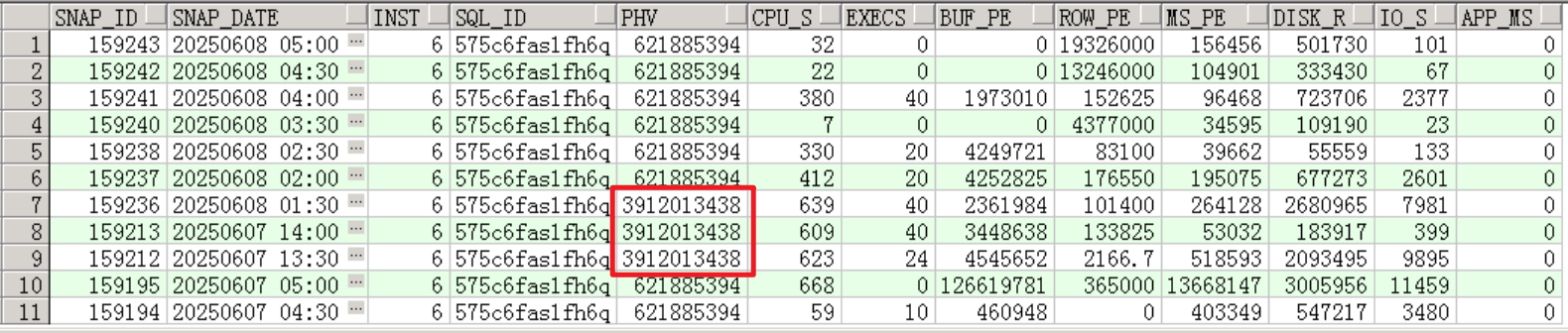
明显发现有执行计划变更,并且执行时间都很慢,两个执行计划没有哪个好不好之分,sql本身慢。
三、查看执行计划
sql monitor:

输出的sql monitor报告中,发现tmp命名的中间表实际行数和预估行数差别很大,说明执行计划不太准确了,大概率这种中间表应用程序里进行大量的修改,但是修改后并没有及时收集统计信息,导致执行计划不准确,也印证了上面执行计划有变更的问题。
排查到这里基本已经清楚了,将相关sql丢给应用确认,并跟领导交差说明数据库没有问题,就是sql本身慢。
3 总结
在工作中遇到性能问题排查的思路和方法大致就是:
- 查看当前负载情况
- 当前会话情况
- 历史活跃会话情况
- TOPSQL查找
如果负载不高,无异常等待事件,基本上就是有慢sql了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









