




现在很多网站启用了防盗链反爬,防止服务器上的资源被人恶意盗取。什么是防盗链呢?
以图片为例,访问图片要从他的网站访问才可以,否则直接访问图片地址得不到图片
练习:抓取微博图片:http://blog.sina.com.cn/s/blog_01ebcb8a0102zi2o.html?tj=1
直接请求real_src请求到的图片不显示,加上Refere请求头即可
哪里找Refere:抓包工具定位到某一张图片数据包,在其requests headers中获取
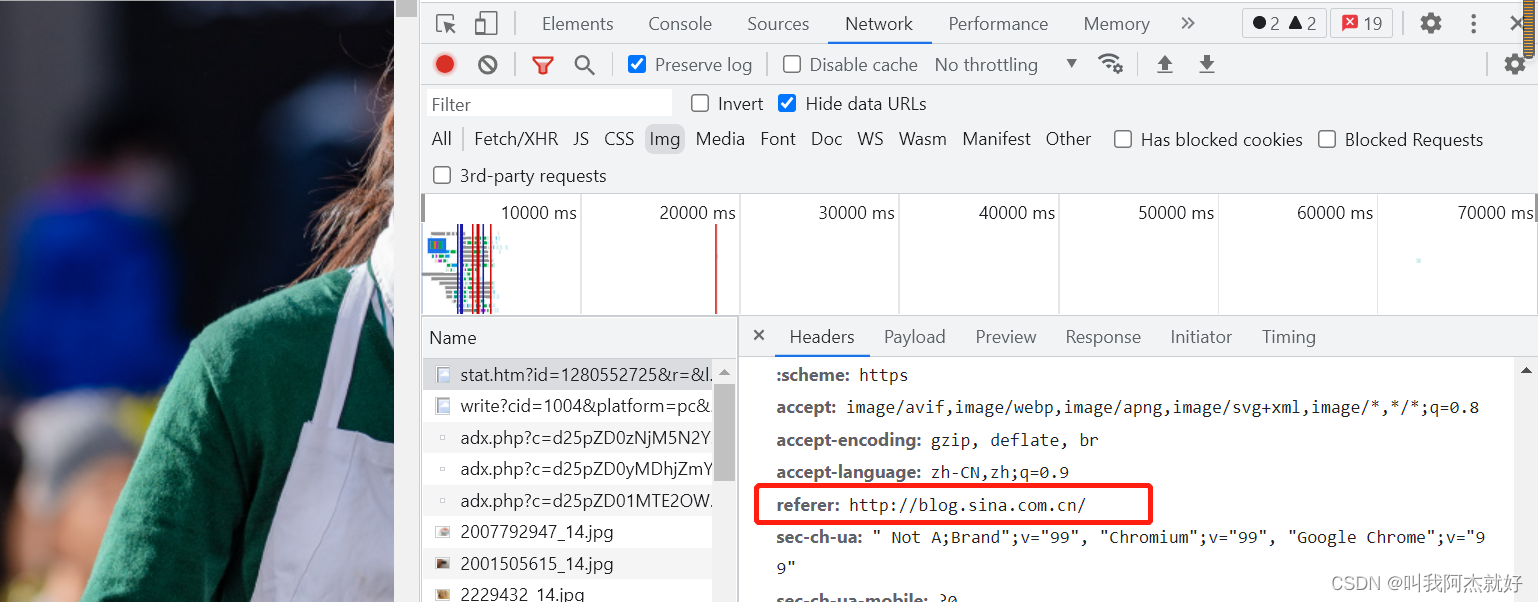
from lxml import etree
import requests
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36',
"referer":"http://blog.sina.com.cn/"
}
url='http://blog.sina.com.cn/s/blog_01ebcb8a0102zi2o.html?tj=1'
respone = requests.get(url=url,headers=headers).text
tree = etree.HTML(respone)
src_list = tree.xpath('//*[@id="sina_keyword_ad_area2"]/div/a/img/@real_src')
for img_url in src_list:
data = requests.get(url=img_url,headers=headers).content
img_name = img_url.split('/')[-1]+'.jpg'
with open('./Jpg/'+img_name,'wb') as fb:
fb.write(data)


















 1728
1728

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











