



 本文探讨了Python中re模块findall方法使用反向引用时出现的问题及解决方法。作者通过实例展示了findall与search方法的区别,并提供了一种有效的方法来正确获取重复字母。
本文探讨了Python中re模块findall方法使用反向引用时出现的问题及解决方法。作者通过实例展示了findall与search方法的区别,并提供了一种有效的方法来正确获取重复字母。
最近在练习反向引用的时候发现re模块中使用findall方法时,反向引用的结果总是不对.
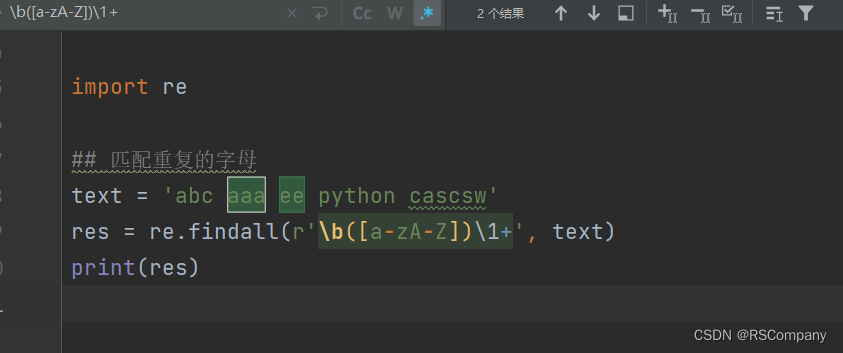
import re
## 匹配重复的字母
text = 'abc aaa ee python cascsw'
res = re.findall(r'\b([a-zA-Z])\1+', text)
print(res)
-> ['a', 'e']
# 结果总是不对,出来总是只有括号的东西
但是在PyCharm中直接匹配,却没有问题
问题分析:
1.因为在PyCharm中使用正则可以直接匹配,所以考虑是不是因为编程语言中对于括号视为了一个匹配组,所以考虑用?:忽略括号。
但是结果不尽人意,因为 ?: 本质上其实是是非捕获型括号,仅仅匹配括号内容,但是不捕获!
所以他带上括号就不再是捕获组,使用\1自然也无法引用
所以这样肯定是报错,运行了一下,报错提示也和我说的一样。
import re
## 匹配重复的字母
text = 'abc aaa ee python cascsw'
res = re.findall(r'\b(?:[a-zA-Z])\1+', text)
print(res)
-> 报错:re.error: invalid group reference 1 at position 15
-> 位置re.error:无效组引用1 - 15
2. 上面行不通之后,就开始考虑,findall方法对整个匹配会对括号内容视为一个匹配,也就是只会匹配括号里的东西,但是search方法就不会这样,而是将括号仅仅作为正则表达式中的整体去做匹配,所以用search验证了一下。
果然没问题,结果返回值aaa
-> <re.Match object; span=(4, 7), match='aaa'>
3. 所以对于这种使用反向引用并且需要匹配到具体值的,不能直接用findall方法,我的建议是对匹配的反向引用值也再加一个括号,让他们变成元组元组匹配,最后再拼接元组,如下所示:
def find_repeat_letter(text: str) -> list:
reg = r'\b([a-zA-Z])(\1+)'
res = re.findall(reg, text)
print(res)
# -> 此时得到的值是: [('a', 'aa'), ('e', 'e')]
if res:
# 通过for循环将字符串拼接即可
return [''.join(i) for i in res]
# 结果: ['aaa','ee']
else:
return []
if __name__ == '__main__':
text = 'abc aaa ee python cascsw'
find_repeat_letter(text)
re模块中还有很多的坑,尤其要注意的其实还是括号对于整个表达式的影响以及对findall方法的影响


















 336
336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









