




首先请你回忆一下第 4 课中我们学了什么: 为一些花和价格生成吸引人的描述,并将这些描述和原因存储到一个 CSV 文件中。为了实现这个目标,程序调用了 OpenAI 模型,并利用了结构化输出解析器,以及一些数据处理和存储的工具。
今天我要带着你深入研究一下 LangChain 中的输出解析器,并用一个新的解析器——Pydantic 解析器来重构第 4 课中的程序。这节课也是模型 I/O 框架的最后一讲。
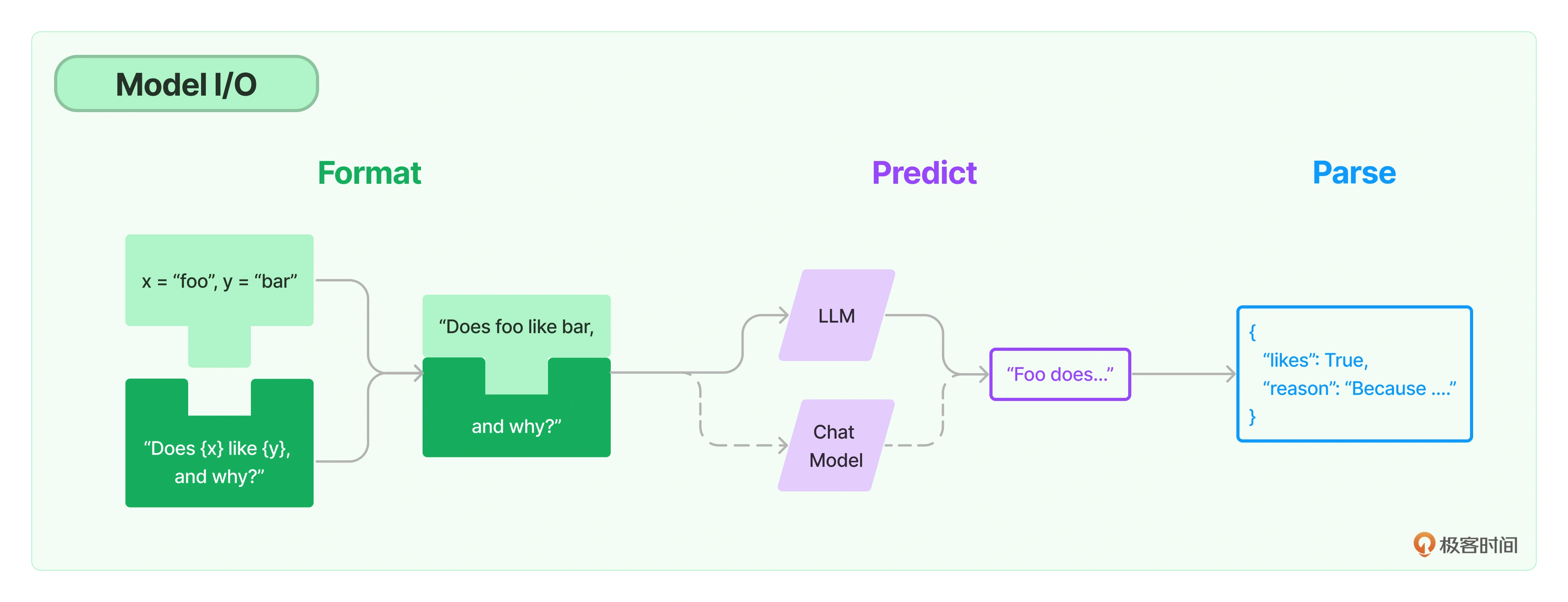
下面先来看看 LangChain 中的输出解析器究竟是什么,有哪些种类。
LangChain 中的输出解析器
语言模型输出的是文本,这是给人类阅读的。但很多时候,你可能想要获得的是程序能够处理的结构化信息。这就是输出解析器发挥作用的地方。
输出解析器是一种专用于处理和构建语言模型响应的类。一个基本的输出解析器类通常需要实现两个核心方法。
- get_format_instructions:这个方法需要返回一个字符串,用于指导如何格式化语言模型的输出,告诉它应该如何组织并构建它的回答。
- parse:这个方法接收一个字符串(也就是语言模型的输出)并将其解析为特定的数据结构或格式。这一步通常用于确保模型的输出符合我们的预期,并且能够以我们需要的形式进行后续处理。
还有一个可选的方法。
- parse_with_prompt:这个方法接收一个字符串(也就是语言模型的输出)和一个提示(用于生成这个输出的提示),并将其解析为特定的数据结构。这样,你可以根据原始提示来修正或重新解析模型的输出,确保输出的信息更加准确和贴合要求。
下面是一个基于上述描述的简单伪代码示例:
class OutputParser:
def __init__(self):
pass
def get_format_instructions(self):
# 返回一个字符串,指导如何格式化模型的输出
pass
def parse(self, model_output):
# 解析模型的输出,转换为某种数据结构或格式
pass
def parse_with_prompt(self, model_output, prompt):
# 基于原始提示解析模型的输出,转换为某种数据结构或格式
pass
在 LangChain 中,通过实现 get_format_instructions、parse 和 parse_with_prompt 这些方法,针对不同的使用场景和目标,设计了各种输出解析器。让我们来逐一认识一下。
- 列表解析器(List Parser):这个解析器用于处理模型生成的输出,当需要模型的输出是一个列表的时候使用。例如,如果你询问模型“列出所有鲜花的库存”,模型的回答应该是一个列表。
- 日期时间解析器(Datetime Parser):这个解析器用于处理日期和时间相关的输出,确保模型的输出是正确的日期或时间格式。
- 枚举解析器(Enum Parser):这个解析器用于处理预定义的一组值,当模型的输出应该是这组预定义值之一时使用。例如,如果你定义了一个问题的答案只能是“是”或“否”,那么枚举解析器可以确保模型的回答是这两个选项之一。
- 结构化输出解析器(Structured Output Parser):这个解析器用于处理复杂的、结构化的输出。如果你的应用需要模型生成具有特定结构的复杂回答(例如一份报告、一篇文章等),那么可以使用结构化输出解析器来实现。
- Pydantic(JSON)解析器:这个解析器用于处理模型的输出,当模型的输出应该是一个符合特定格式的 JSON 对象时使用。它使用 Pydantic 库,这是一个数据验证库,可以用于构建复杂的数据模型,并确保模型的输出符合预期的数据模型。
- 自动修复解析器(Auto-Fixing Parser):这个解析器可以自动修复某些常见的模型输出错误。例如,如果模型的输出应该是一段文本,但是模型返回了一段包含语法或拼写错误的文本,自动修复解析器可以自动纠正这些错误。
- 重试解析器(RetryWithErrorOutputParser):这个解析器用于在模型的初次输出不符合预期时,尝试修复或重新生成新的输出。例如,如果模型的输出应该是一个日期,但是模型返回了一个字符串,那么重试解析器可以重新提示模型生成正确的日期格式。上面的各种解析器中,前三种很容易理解,而结构化输出解析器你已经用过了。
所以接下来我们重点讲一讲 Pydantic(JSON)解析器、自动修复解析器和重试解析器。
Pydantic(JSON)解析器实战
Pydantic (JSON) 解析器应该是最常用也是最重要的解析器,我带着你用它来重构鲜花文案生成程序。
Pydantic 是一个 Python 数据验证和设置管理库,主要基于 Python 类型提示。尽管它不是专为 JSON 设计的,但由于 JSON 是现代 Web 应用和 API 交互中的常见数据格式,Pydantic 在处理和验证 JSON 数据时特别有用。
第一步:创建模型实例
先通过环境变量设置 OpenAI API 密钥,然后使用 LangChain 库创建了一个 OpenAI 的模型实例。这里我们仍然选择了 text-davinci-003 作为大语言模型。
# ------Part 1
# 设置OpenAI API密钥
import os
os.environ["OPENAI_API_KEY"] = '你的OpenAI API Key'
# 创建模型实例
from langchain import OpenAI
model = OpenAI(model_name='gpt-3.5-turbo-instruct')
第二步:定义输出数据的格式
先创建了一个空的 DataFrame,用于存储从模型生成的描述。接下来,通过一个名为 FlowerDescription 的 Pydantic BaseModel 类,定义了期望的数据格式(也就是数据的结构)。
# ------Part 2
# 创建一个空的DataFrame用于存储结果
import pandas as pd
df = pd.DataFrame(columns=["flower_type", "price", "description", "reason"])
# 数据准备
flowers = ["玫瑰", "百合", "康乃馨"]
prices = ["50", "30", "20"]
# 定义我们想要接收的数据格式
from pydantic import BaseModel, Field
class FlowerDescription(BaseModel):
flower_type: str = Field(description="鲜花的种类")
price: int = Field(description="鲜花的价格")
description: str = Field(description="鲜花的描述文案")
reason: str = Field(description="为什么要这样写这个文案")
在这里我们用到了负责数据格式验证的 Pydantic 库来创建带有类型注解的类 FlowerDescription,它可以自动验证输入数据,确保输入数据符合你指定的类型和其他验证条件。
Pydantic 有这样几个特点。
- 数据验证:当你向 Pydantic 类赋值时,它会自动进行数据验证。例如,如果你创建了一个字段需要是整数,但试图向它赋予一个字符串,Pydantic 会引发异常。
- 数据转换:Pydantic 不仅进行数据验证,还可以进行数据转换。例如,如果你有一个需要整数的字段,但你提供了一个可以转换为整数的字符串,如 “42”,Pydantic 会自动将这个字符串转换为整数 42。
- 易于使用:创建一个 Pydantic 类就像定义一个普通的 Python 类一样简单。只需要使用 Python 的类型注解功能,即可在类定义中指定每个字段的类型。
- JSON 支持:Pydantic 类可以很容易地从 JSON 数据创建,并可以将类的数据转换为 JSON 格式。
下面,我们基于这个 Pydantic 数据格式类来创建 LangChain 的输出解析器。
第三步:创建输出解析器
在这一步中,我们创建输出解析器并获取输出格式指示。先使用 LangChain 库中的 PydanticOutputParser 创建了输出解析器,该解析器将用于解析模
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1673
1673

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









